 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Generality and Knowledge Transferability in Cross-Domain Duplicate Question Detection for Heterogeneous Community Question Answering
Paper and Code
Nov 15, 2018

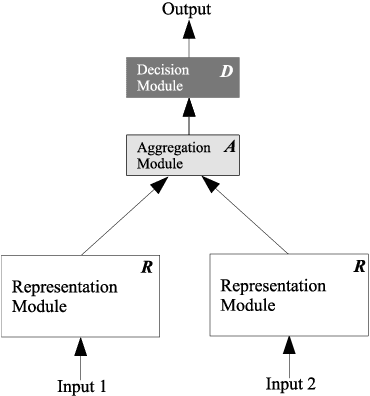
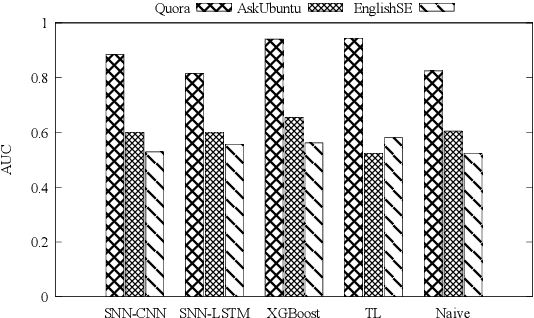
Duplicate question detection is an ongoing challenge in community question answering because semantically equivalent questions can have significantly different words and structures. In addition, the identification of duplicate questions can reduce the resources required for retrieval, when the same questions are not repeated. This study compares the performance of deep neural networks and gradient tree boosting, and explores the possibility of domain adaptation with transfer learning to improve the under-performing target domains for the text-pair duplicates classification task, using three heterogeneous datasets: general-purpose Quora, technical Ask Ubuntu, and academic English Stack Exchange. Ultimately, our study exposes the alternative hypothesis that the meaning of a "duplicate" is not inherently general-purpose, but rather is dependent on the domain of learning, hence reducing the chance of transfer learning through adapting to the domain.