 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA General-Purpose Transferable Predictor for Neural Architecture Search
Feb 21, 2023



Understanding and modelling the performance of neural architectures is key to Neural Architecture Search (NAS). Performance predictors have seen widespread use in low-cost NAS and achieve high ranking correlations between predicted and ground truth performance in several NAS benchmarks. However, existing predictors are often designed based on network encodings specific to a predefined search space and are therefore not generalizable to other search spaces or new architecture families. In this paper, we propose a general-purpose neural predictor for NAS that can transfer across search spaces, by representing any given candidate Convolutional Neural Network (CNN) with a Computation Graph (CG) that consists of primitive operators. We further combine our CG network representation with Contrastive Learning (CL) and propose a graph representation learning procedure that leverages the structural information of unlabeled architectures from multiple families to train CG embeddings for our performance predictor. Experimental results on NAS-Bench-101, 201 and 301 demonstrate the efficacy of our scheme as we achieve strong positive Spearman Rank Correlation Coefficient (SRCC) on every search space, outperforming several Zero-Cost Proxies, including Synflow and Jacov, which are also generalizable predictors across search spaces. Moreover, when using our proposed general-purpose predictor in an evolutionary neural architecture search algorithm, we can find high-performance architectures on NAS-Bench-101 and find a MobileNetV3 architecture that attains 79.2% top-1 accuracy on ImageNet.
GENNAPE: Towards Generalized Neural Architecture Performance Estimators
Nov 30, 2022



Predicting neural architecture performance is a challenging task and is crucial to neural architecture design and search. Existing approaches either rely on neural performance predictors which are limited to modeling architectures in a predefined design space involving specific sets of operators and connection rules, and cannot generalize to unseen architectures, or resort to zero-cost proxies which are not always accurate. In this paper, we propose GENNAPE, a Generalized Neural Architecture Performance Estimator, which is pretrained on open neural architecture benchmarks, and aims to generalize to completely unseen architectures through combined innovations in network representation, contrastive pretraining, and fuzzy clustering-based predictor ensemble. Specifically, GENNAPE represents a given neural network as a Computation Graph (CG) of atomic operations which can model an arbitrary architecture. It first learns a graph encoder via Contrastive Learning to encourage network separation by topological features, and then trains multiple predictor heads, which are soft-aggregated according to the fuzzy membership of a neural network. Experiments show that GENNAPE pretrained on NAS-Bench-101 can achieve superior transferability to 5 different public neural network benchmarks, including NAS-Bench-201, NAS-Bench-301, MobileNet and ResNet families under no or minimum fine-tuning. We further introduce 3 challenging newly labelled neural network benchmarks: HiAML, Inception and Two-Path, which can concentrate in narrow accuracy ranges. Extensive experiments show that GENNAPE can correctly discern high-performance architectures in these families. Finally, when paired with a search algorithm, GENNAPE can find architectures that improve accuracy while reducing FLOPs on three families.
Profiling Neural Blocks and Design Spaces for Mobile Neural Architecture Search
Sep 25, 2021
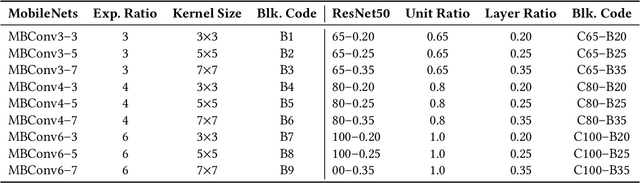
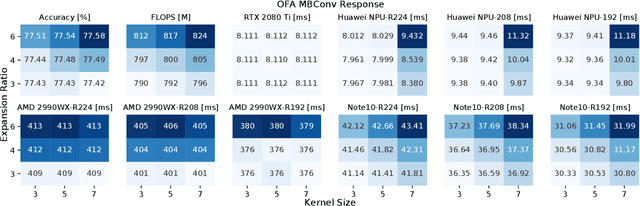
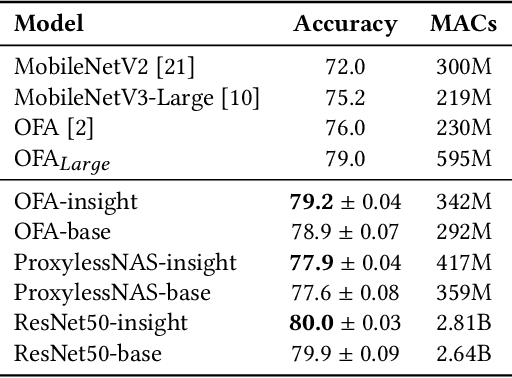
Neural architecture search automates neural network design and has achieved state-of-the-art results in many deep learning applications. While recent literature has focused on designing networks to maximize accuracy, little work has been conducted to understand the compatibility of architecture design spaces to varying hardware. In this paper, we analyze the neural blocks used to build Once-for-All (MobileNetV3), ProxylessNAS and ResNet families, in order to understand their predictive power and inference latency on various devices, including Huawei Kirin 9000 NPU, RTX 2080 Ti, AMD Threadripper 2990WX, and Samsung Note10. We introduce a methodology to quantify the friendliness of neural blocks to hardware and the impact of their placement in a macro network on overall network performance via only end-to-end measurements. Based on extensive profiling results, we derive design insights and apply them to hardware-specific search space reduction. We show that searching in the reduced search space generates better accuracy-latency Pareto frontiers than searching in the original search spaces, customizing architecture search according to the hardware. Moreover, insights derived from measurements lead to notably higher ImageNet top-1 scores on all search spaces investigated.
Benchmarking Quantum Hardware for Training of Fully Visible Boltzmann Machines
Nov 14, 2016
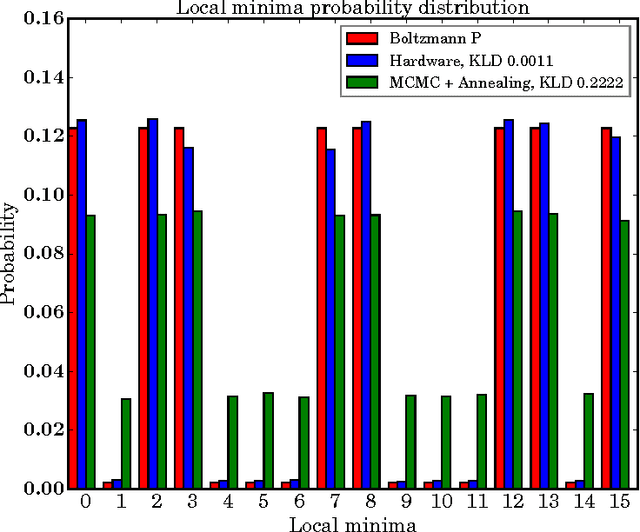
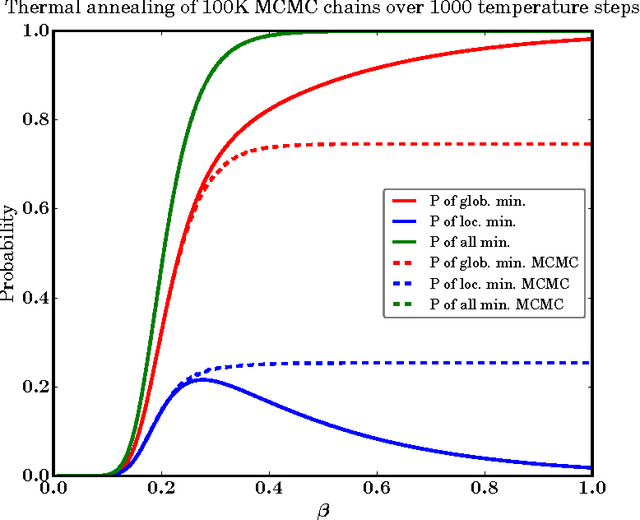
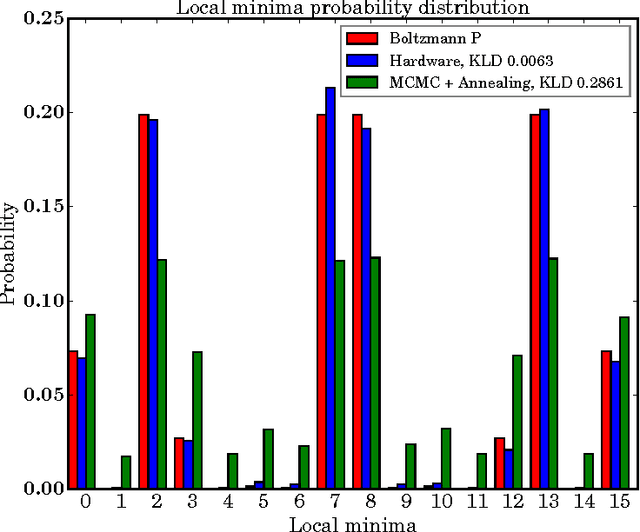
Quantum annealing (QA) is a hardware-based heuristic optimization and sampling method applicable to discrete undirected graphical models. While similar to simulated annealing, QA relies on quantum, rather than thermal, effects to explore complex search spaces. For many classes of problems, QA is known to offer computational advantages over simulated annealing. Here we report on the ability of recent QA hardware to accelerate training of fully visible Boltzmann machines. We characterize the sampling distribution of QA hardware, and show that in many cases, the quantum distributions differ significantly from classical Boltzmann distributions. In spite of this difference, training (which seeks to match data and model statistics) using standard classical gradient updates is still effective. We investigate the use of QA for seeding Markov chains as an alternative to contrastive divergence (CD) and persistent contrastive divergence (PCD). Using $k=50$ Gibbs steps, we show that for problems with high-energy barriers between modes, QA-based seeds can improve upon chains with CD and PCD initializations. For these hard problems, QA gradient estimates are more accurate, and allow for faster learning. Furthermore, and interestingly, even the case of raw QA samples (that is, $k=0$) achieved similar improvements. We argue that this relates to the fact that we are training a quantum rather than classical Boltzmann distribution in this case. The learned parameters give rise to hardware QA distributions closely approximating classical Boltzmann distributions that are hard to train with CD/PCD.