 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Path Towards Quantum Advantage in Training Deep Generative Models with Quantum Annealers
Dec 04, 2019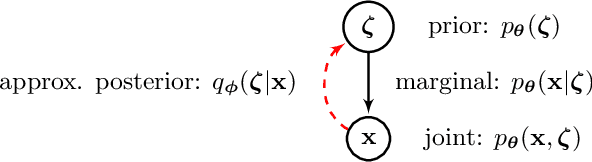

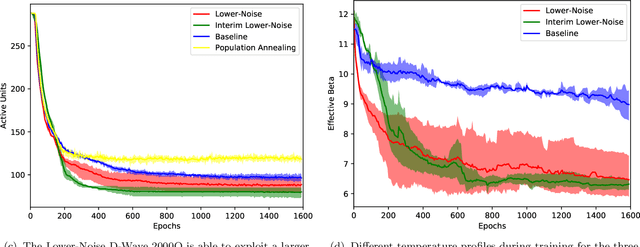
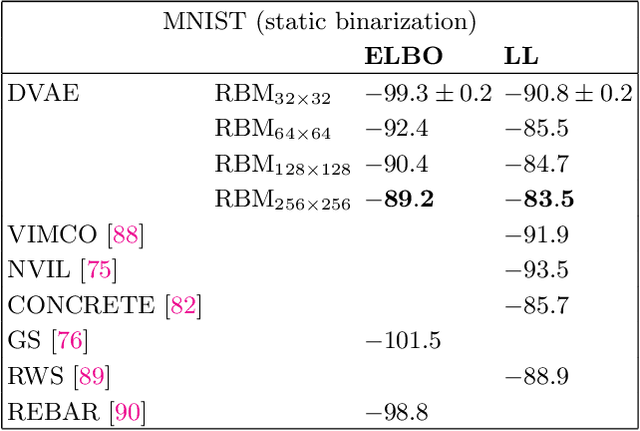
The development of quantum-classical hybrid (QCH) algorithms is critical to achieve state-of-the-art computational models. A QCH variational autoencoder (QVAE) was introduced in Ref. [1] by some of the authors of this paper. QVAE consists of a classical auto-encoding structure realized by traditional deep neural networks to perform inference to, and generation from, a discrete latent space. The latent generative process is formalized as thermal sampling from either a quantum or classical Boltzmann machine (QBM or BM). This setup allows quantum-assisted training of deep generative models by physically simulating the generative process with quantum annealers. In this paper, we have successfully employed D-Wave quantum annealers as Boltzmann samplers to perform quantum-assisted, end-to-end training of QVAE. The hybrid structure of QVAE allows us to deploy current-generation quantum annealers in QCH generative models to achieve competitive performance on datasets such as MNIST. The results presented in this paper suggest that commercially available quantum annealers can be deployed, in conjunction with well-crafted classical deep neutral networks, to achieve competitive results in unsupervised and semisupervised tasks on large-scale datasets. We also provide evidence that our setup is able to exploit large latent-space (Q)BMs, which develop slowly mixing modes. This expressive latent space results in slow and inefficient classical sampling, and paves the way to achieve quantum advantage with quantum annealing in realistic sampling applications.
PixelVAE++: Improved PixelVAE with Discrete Prior
Aug 26, 2019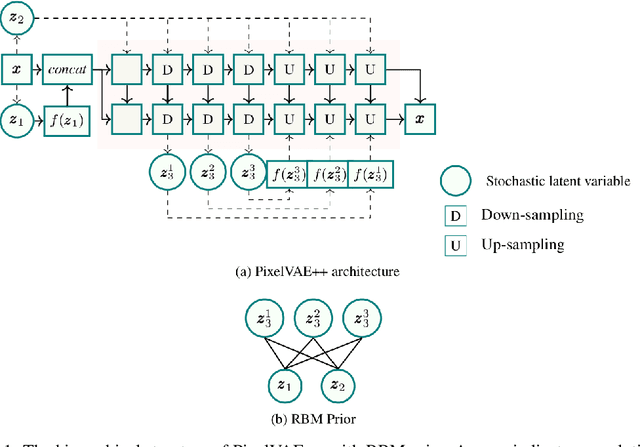



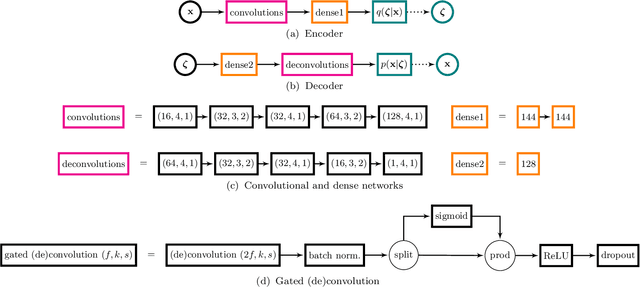
Constructing powerful generative models for natural images is a challenging task. PixelCNN models capture details and local information in images very well but have limited receptive field. Variational autoencoders with a factorial decoder can capture global information easily, but they often fail to reconstruct details faithfully. PixelVAE combines the best features of the two models and constructs a generative model that is able to learn local and global structures. Here we introduce PixelVAE++, a VAE with three types of latent variables and a PixelCNN++ for the decoder. We introduce a novel architecture that reuses a part of the decoder as an encoder. We achieve the state of the art performance on binary data sets such as MNIST and Omniglot and achieve the state of the art performance on CIFAR-10 among latent variable models while keeping the latent variables informative.
Learning Undirected Posteriors by Backpropagation through MCMC Updates
Jan 11, 2019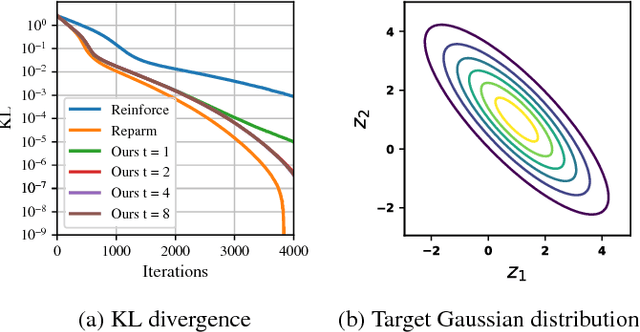
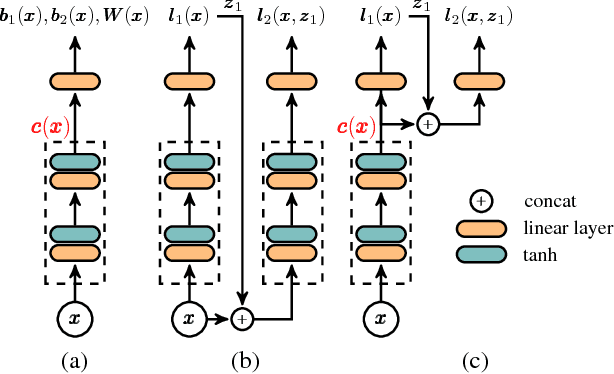
The representation of the posterior is a critical aspect of effective variational autoencoders (VAEs). Poor choices for the posterior have a detrimental impact on the generative performance of VAEs due to the mismatch with the true posterior. We extend the class of posterior models that may be learned by using undirected graphical models. We develop an efficient method to train undirected posteriors by showing that the gradient of the training objective with respect to the parameters of the undirected posterior can be computed by backpropagation through Markov chain Monte Carlo updates. We apply these gradient estimators for training discrete VAEs with Boltzmann machine posteriors and demonstrate that undirected models outperform previous results obtained using directed graphical models as posteriors.
DVAE#: Discrete Variational Autoencoders with Relaxed Boltzmann Priors
Oct 15, 2018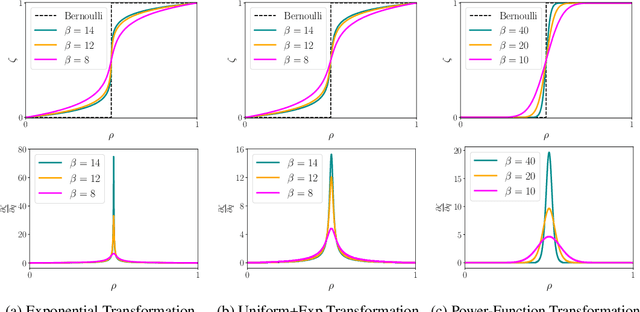
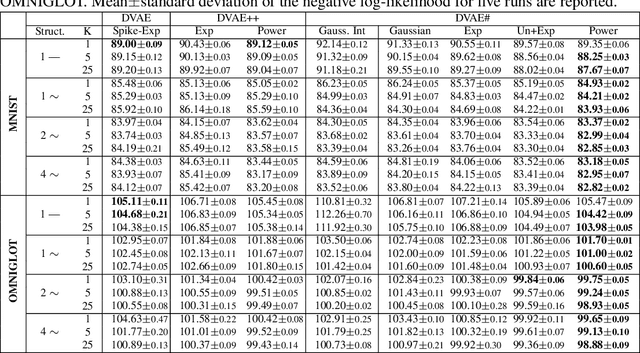

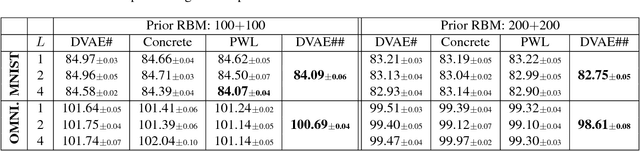
Boltzmann machines are powerful distributions that have been shown to be an effective prior over binary latent variables in variational autoencoders (VAEs). However, previous methods for training discrete VAEs have used the evidence lower bound and not the tighter importance-weighted bound. We propose two approaches for relaxing Boltzmann machines to continuous distributions that permit training with importance-weighted bounds. These relaxations are based on generalized overlapping transformations and the Gaussian integral trick. Experiments on the MNIST and OMNIGLOT datasets show that these relaxations outperform previous discrete VAEs with Boltzmann priors. An implementation which reproduces these results is available at https://github.com/QuadrantAI/dvae .
Improved Gradient-Based Optimization Over Discrete Distributions
Sep 29, 2018
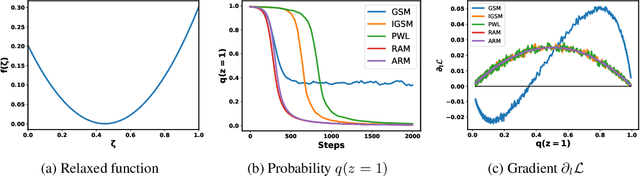

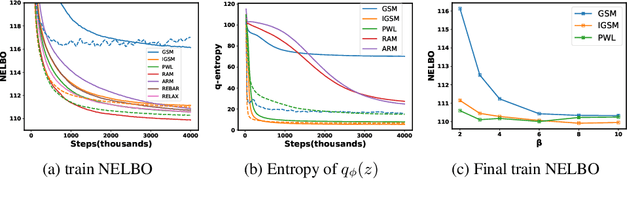
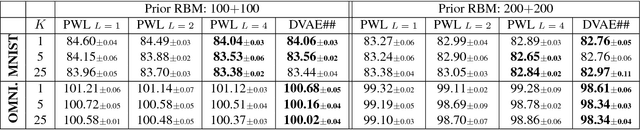
In many applications we seek to maximize an expectation with respect to a distribution over discrete variables. Estimating gradients of such objectives with respect to the distribution parameters is a challenging problem. We analyze existing solutions including finite-difference (FD) estimators and continuous relaxation (CR) estimators in terms of bias and variance. We show that the commonly used Gumbel-Softmax estimator is biased and propose a simple method to reduce it. We also derive a simpler piece-wise linear continuous relaxation that also possesses reduced bias. We demonstrate empirically that reduced bias leads to a better performance in variational inference and on binary optimization tasks.
DVAE++: Discrete Variational Autoencoders with Overlapping Transformations
May 25, 2018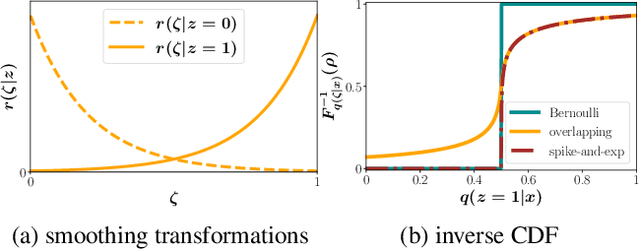



Training of discrete latent variable models remains challenging because passing gradient information through discrete units is difficult. We propose a new class of smoothing transformations based on a mixture of two overlapping distributions, and show that the proposed transformation can be used for training binary latent models with either directed or undirected priors. We derive a new variational bound to efficiently train with Boltzmann machine priors. Using this bound, we develop DVAE++, a generative model with a global discrete prior and a hierarchy of convolutional continuous variables. Experiments on several benchmarks show that overlapping transformations outperform other recent continuous relaxations of discrete latent variables including Gumbel-Softmax (Maddison et al., 2016; Jang et al., 2016), and discrete variational autoencoders (Rolfe 2016).
Quantum Variational Autoencoder
Feb 15, 2018

Variational autoencoders (VAEs) are powerful generative models with the salient ability to perform inference. Here, we introduce a \emph{quantum variational autoencoder} (QVAE): a VAE whose latent generative process is implemented as a quantum Boltzmann machine (QBM). We show that our model can be trained end-to-end by maximizing a well-defined loss-function: a "quantum" lower-bound to a variational approximation of the log-likelihood. We use quantum Monte Carlo (QMC) simulations to train and evaluate the performance of QVAEs. To achieve the best performance, we first create a VAE platform with discrete latent space generated by a restricted Boltzmann machine (RBM). Our model achieves state-of-the-art performance on the MNIST dataset when compared against similar approaches that only involve discrete variables in the generative process. We consider QVAEs with a smaller number of latent units to be able to perform QMC simulations, which are computationally expensive. We show that QVAEs can be trained effectively in regimes where quantum effects are relevant despite training via the quantum bound. Our findings open the way to the use of quantum computers to train QVAEs to achieve competitive performance for generative models. Placing a QBM in the latent space of a VAE leverages the full potential of current and next-generation quantum computers as sampling devices.
Benchmarking Quantum Hardware for Training of Fully Visible Boltzmann Machines
Nov 14, 2016
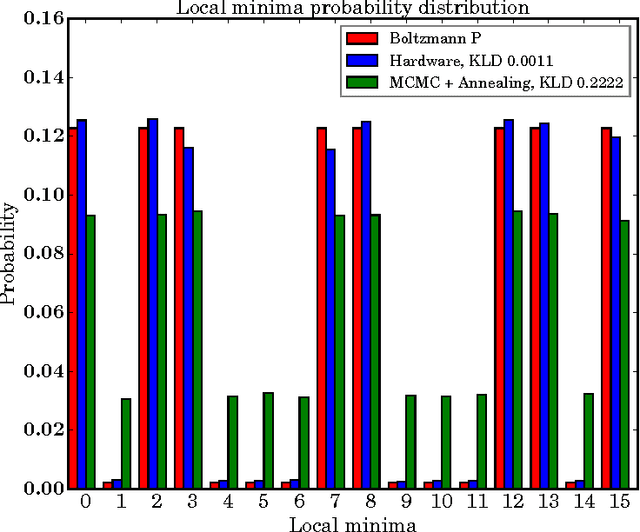
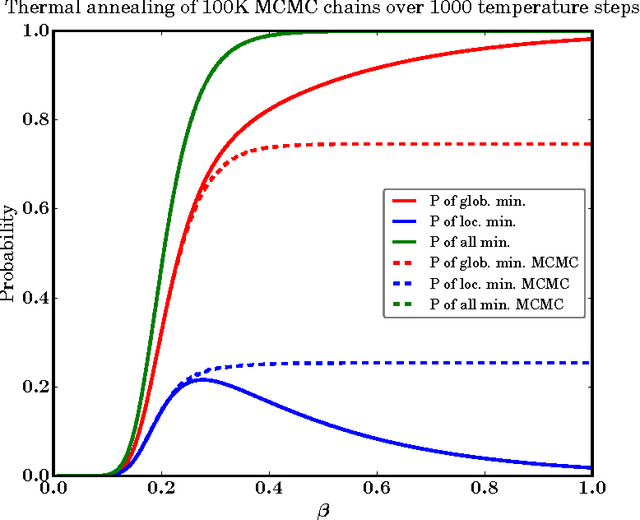
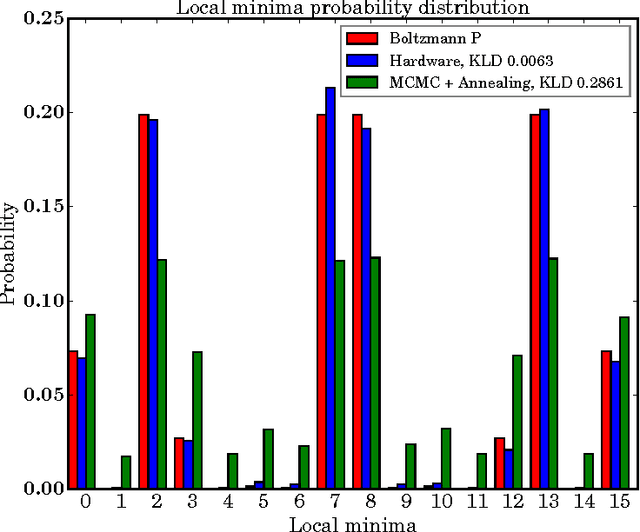
Quantum annealing (QA) is a hardware-based heuristic optimization and sampling method applicable to discrete undirected graphical models. While similar to simulated annealing, QA relies on quantum, rather than thermal, effects to explore complex search spaces. For many classes of problems, QA is known to offer computational advantages over simulated annealing. Here we report on the ability of recent QA hardware to accelerate training of fully visible Boltzmann machines. We characterize the sampling distribution of QA hardware, and show that in many cases, the quantum distributions differ significantly from classical Boltzmann distributions. In spite of this difference, training (which seeks to match data and model statistics) using standard classical gradient updates is still effective. We investigate the use of QA for seeding Markov chains as an alternative to contrastive divergence (CD) and persistent contrastive divergence (PCD). Using $k=50$ Gibbs steps, we show that for problems with high-energy barriers between modes, QA-based seeds can improve upon chains with CD and PCD initializations. For these hard problems, QA gradient estimates are more accurate, and allow for faster learning. Furthermore, and interestingly, even the case of raw QA samples (that is, $k=0$) achieved similar improvements. We argue that this relates to the fact that we are training a quantum rather than classical Boltzmann distribution in this case. The learned parameters give rise to hardware QA distributions closely approximating classical Boltzmann distributions that are hard to train with CD/PCD.