 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLooking at CTR Prediction Again: Is Attention All You Need?
May 12, 2021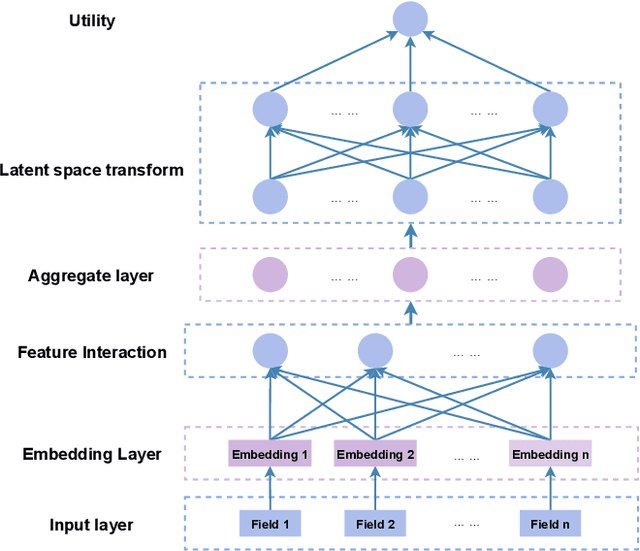

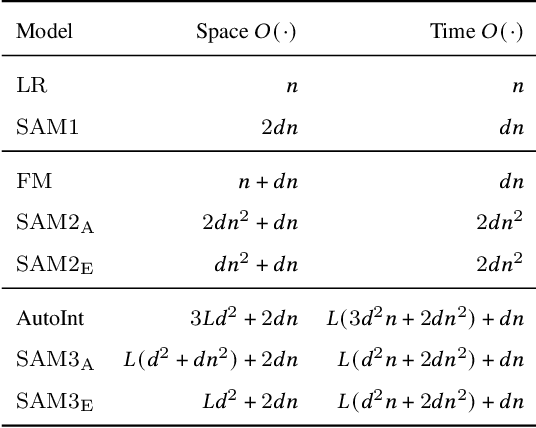
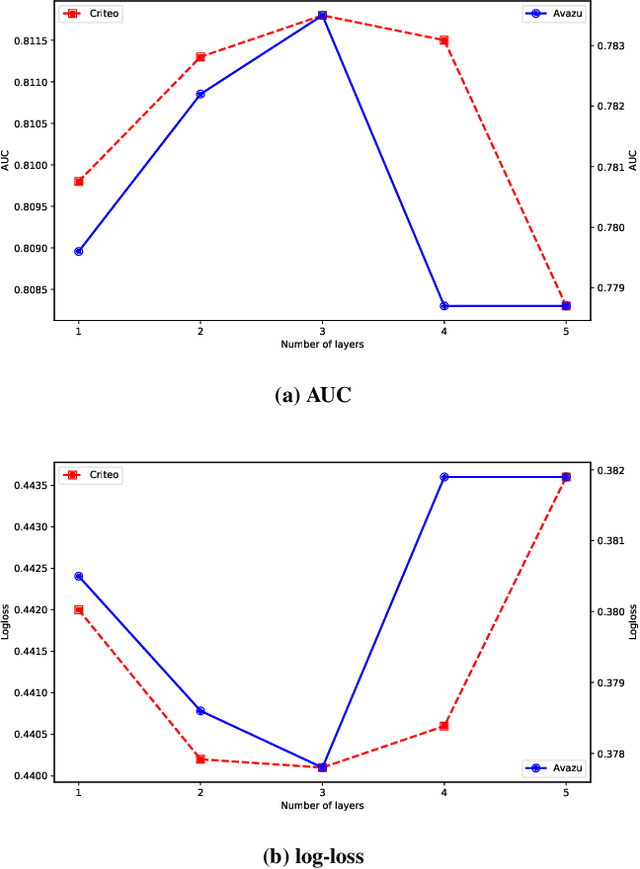
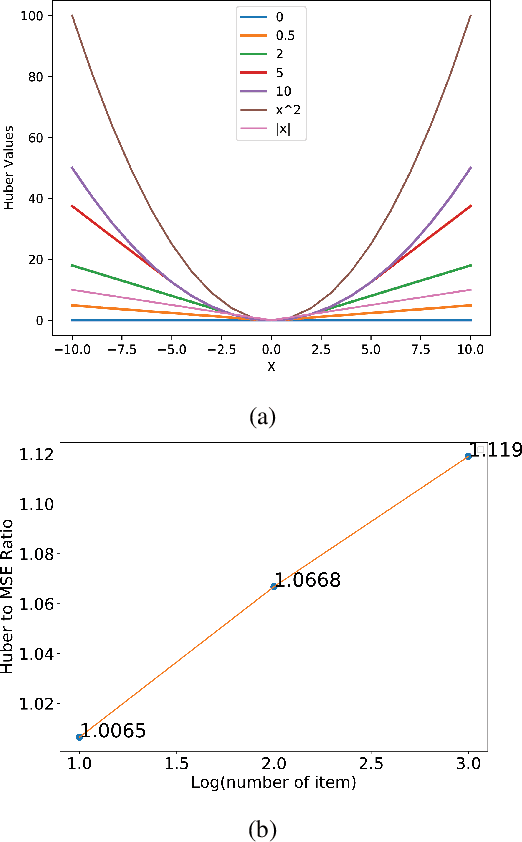
Click-through rate (CTR) prediction is a critical problem in web search, recommendation systems and online advertisement displaying. Learning good feature interactions is essential to reflect user's preferences to items. Many CTR prediction models based on deep learning have been proposed, but researchers usually only pay attention to whether state-of-the-art performance is achieved, and ignore whether the entire framework is reasonable. In this work, we use the discrete choice model in economics to redefine the CTR prediction problem, and propose a general neural network framework built on self-attention mechanism. It is found that most existing CTR prediction models align with our proposed general framework. We also examine the expressive power and model complexity of our proposed framework, along with potential extensions to some existing models. And finally we demonstrate and verify our insights through some experimental results on public datasets.
Interpretable Reinforcement Learning Inspired by Piaget's Theory of Cognitive Development
Feb 01, 2021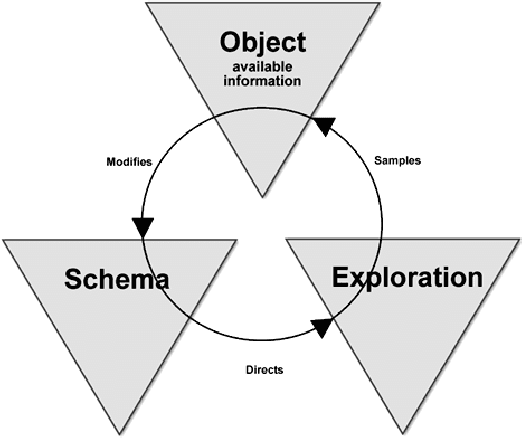

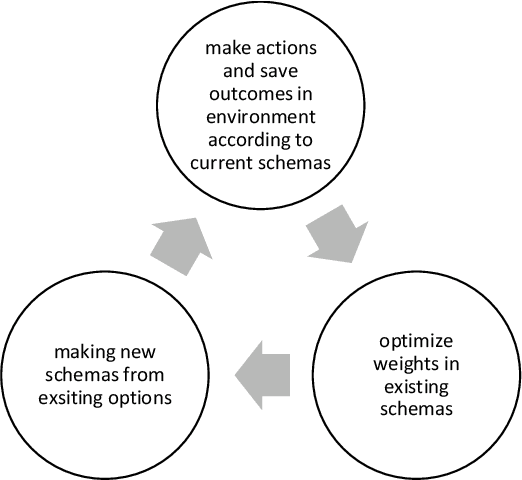
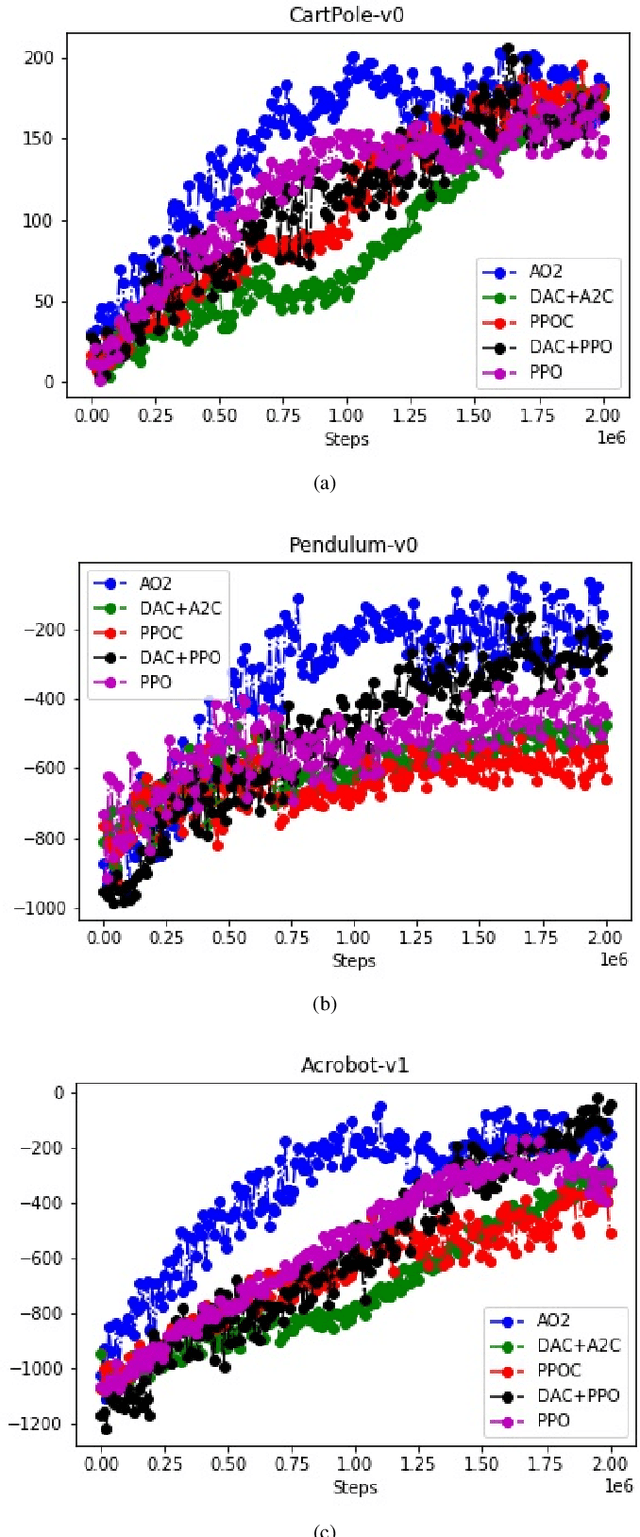
Endeavors for designing robots with human-level cognitive abilities have led to different categories of learning machines. According to Skinner's theory, reinforcement learning (RL) plays a key role in human intuition and cognition. Majority of the state-of-the-art methods including deep RL algorithms are strongly influenced by the connectionist viewpoint. Such algorithms can significantly benefit from theories of mind and learning in other disciplines. This paper entertains the idea that theories such as language of thought hypothesis (LOTH), script theory, and Piaget's cognitive development theory provide complementary approaches, which will enrich the RL field. Following this line of thinking, a general computational building block is proposed for Piaget's schema theory that supports the notions of productivity, systematicity, and inferential coherence as described by Fodor in contrast with the connectionism theory. Abstraction in the proposed method is completely upon the system itself and is not externally constrained by any predefined architecture. The whole process matches the Neisser's perceptual cycle model. Performed experiments on three typical control problems followed by behavioral analysis confirm the interpretability of the proposed method and its competitiveness compared to the state-of-the-art algorithms. Hence, the proposed framework can be viewed as a step towards achieving human-like cognition in artificial intelligent systems.
Enacted Visual Perception: A Computational Model based on Piaget Equilibrium
Jan 30, 2021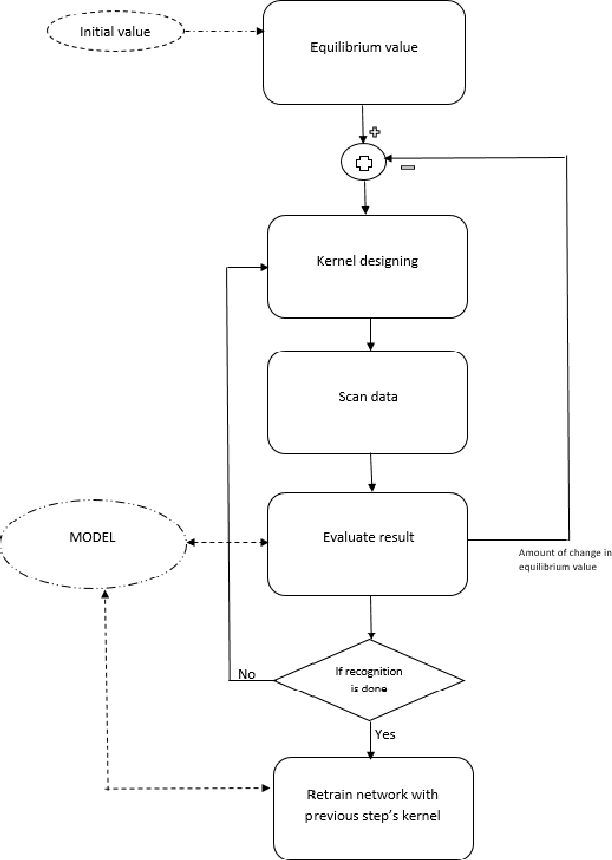
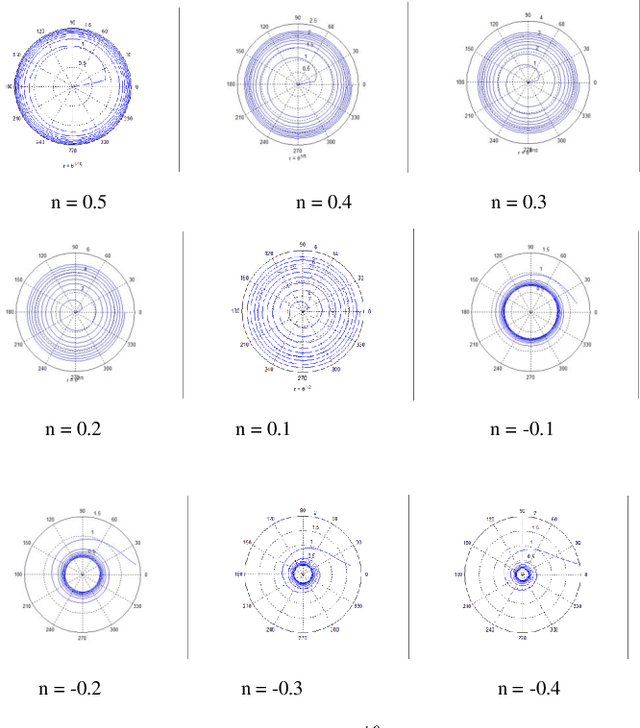
In Maurice Merleau-Ponty's phenomenology of perception, analysis of perception accounts for an element of intentionality, and in effect therefore, perception and action cannot be viewed as distinct procedures. In the same line of thinking, Alva No\"{e} considers perception as a thoughtful activity that relies on capacities for action and thought. Here, by looking into psychology as a source of inspiration, we propose a computational model for the action involved in visual perception based on the notion of equilibrium as defined by Jean Piaget. In such a model, Piaget's equilibrium reflects the mind's status, which is used to control the observation process. The proposed model is built around a modified version of convolutional neural networks (CNNs) with enhanced filter performance, where characteristics of filters are adaptively adjusted via a high-level control signal that accounts for the thoughtful activity in perception. While the CNN plays the role of the visual system, the control signal is assumed to be a product of mind.
Deep Reinforcement Learning-Based Product Recommender for Online Advertising
Jan 30, 2021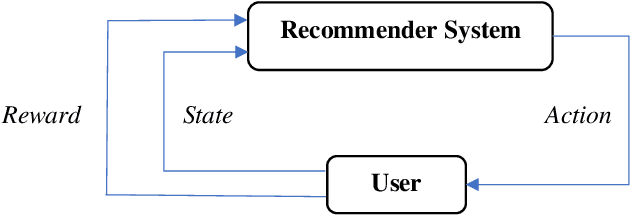
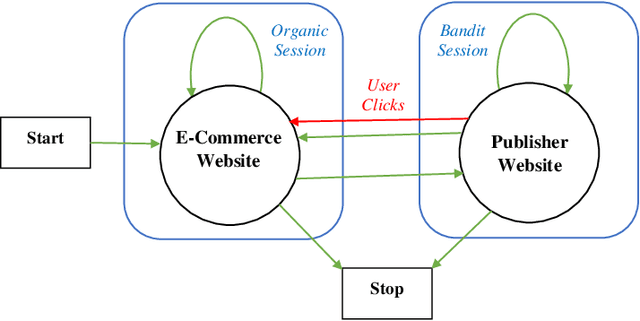
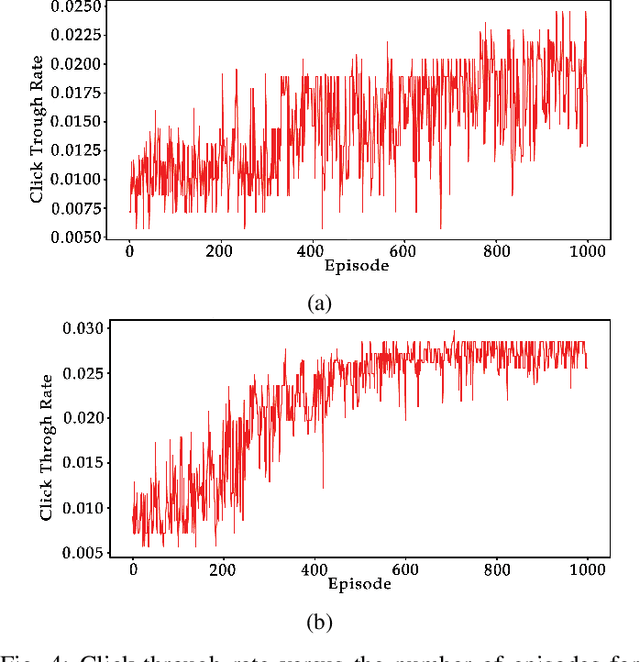
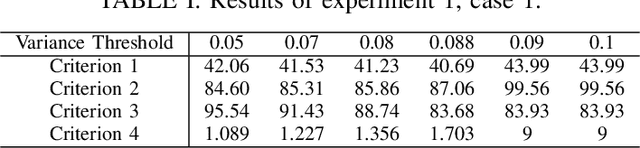
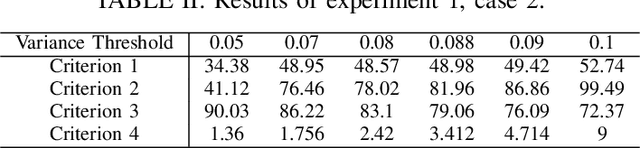
In online advertising, recommender systems try to propose items from a list of products to potential customers according to their interests. Such systems have been increasingly deployed in E-commerce due to the rapid growth of information technology and availability of large datasets. The ever-increasing progress in the field of artificial intelligence has provided powerful tools for dealing with such real-life problems. Deep reinforcement learning (RL) that deploys deep neural networks as universal function approximators can be viewed as a valid approach for design and implementation of recommender systems. This paper provides a comparative study between value-based and policy-based deep RL algorithms for designing recommender systems for online advertising. The RecoGym environment is adopted for training these RL-based recommender systems, where the long short term memory (LSTM) is deployed to build value and policy networks in these two approaches, respectively. LSTM is used to take account of the key role that order plays in the sequence of item observations by users. The designed recommender systems aim at maximising the click-through rate (CTR) for the recommended items. Finally, guidelines are provided for choosing proper RL algorithms for different scenarios that the recommender system is expected to handle.
Defence against adversarial attacks using classical and quantum-enhanced Boltzmann machines
Dec 21, 2020


We provide a robust defence to adversarial attacks on discriminative algorithms. Neural networks are naturally vulnerable to small, tailored perturbations in the input data that lead to wrong predictions. On the contrary, generative models attempt to learn the distribution underlying a dataset, making them inherently more robust to small perturbations. We use Boltzmann machines for discrimination purposes as attack-resistant classifiers, and compare them against standard state-of-the-art adversarial defences. We find improvements ranging from 5% to 72% against attacks with Boltzmann machines on the MNIST dataset. We furthermore complement the training with quantum-enhanced sampling from the D-Wave 2000Q annealer, finding results comparable with classical techniques and with marginal improvements in some cases. These results underline the relevance of probabilistic methods in constructing neural networks and demonstrate the power of quantum computers, even with limited hardware capabilities. This work is dedicated to the memory of Peter Wittek.
Distributed Training of Deep Learning Models: A Taxonomic Perspective
Jul 08, 2020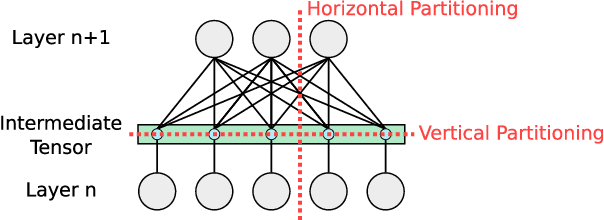
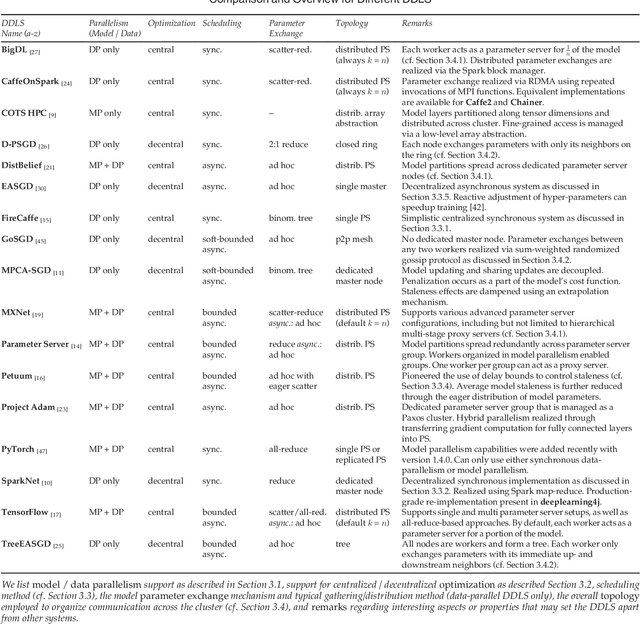
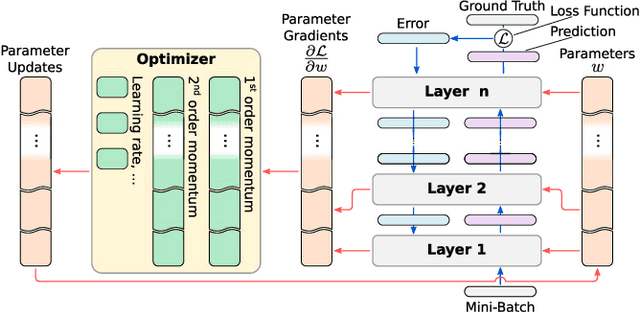
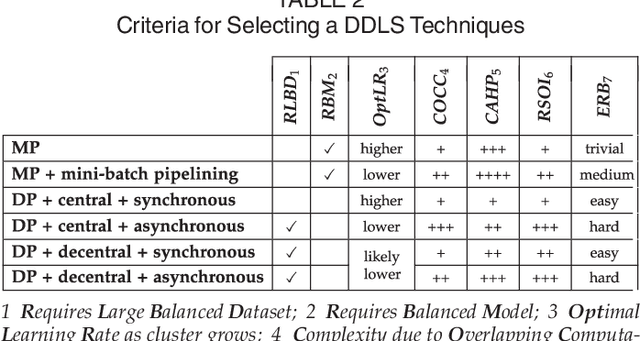
Distributed deep learning systems (DDLS) train deep neural network models by utilizing the distributed resources of a cluster. Developers of DDLS are required to make many decisions to process their particular workloads in their chosen environment efficiently. The advent of GPU-based deep learning, the ever-increasing size of datasets and deep neural network models, in combination with the bandwidth constraints that exist in cluster environments require developers of DDLS to be innovative in order to train high quality models quickly. Comparing DDLS side-by-side is difficult due to their extensive feature lists and architectural deviations. We aim to shine some light on the fundamental principles that are at work when training deep neural networks in a cluster of independent machines by analyzing the general properties associated with training deep learning models and how such workloads can be distributed in a cluster to achieve collaborative model training. Thereby we provide an overview of the different techniques that are used by contemporary DDLS and discuss their influence and implications on the training process. To conceptualize and compare DDLS, we group different techniques into categories, thus establishing a taxonomy of distributed deep learning systems.
Benchmarking Quantum Hardware for Training of Fully Visible Boltzmann Machines
Nov 14, 2016
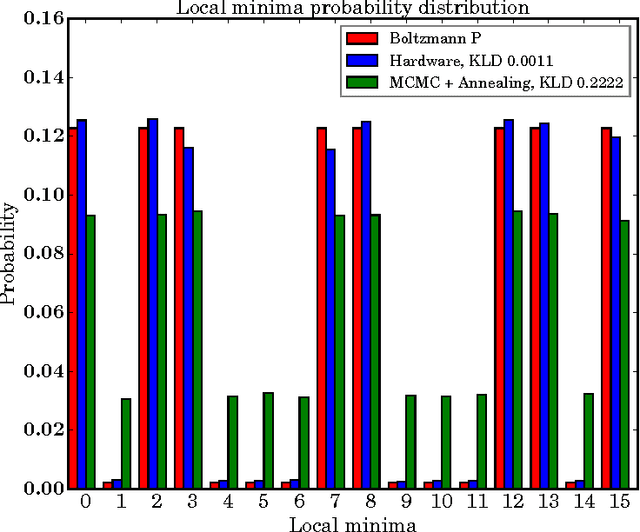
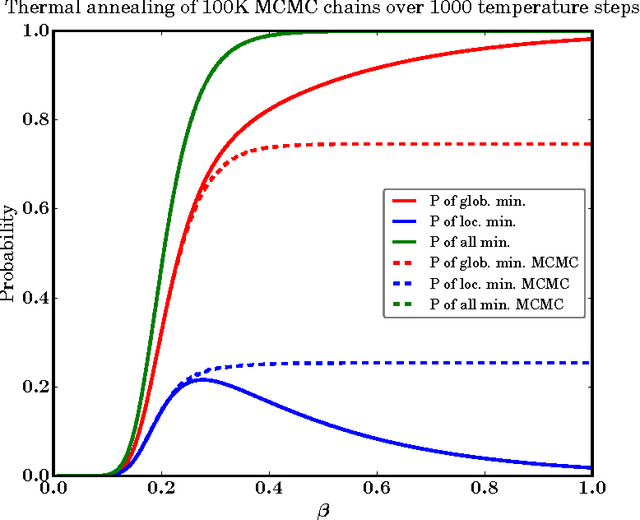
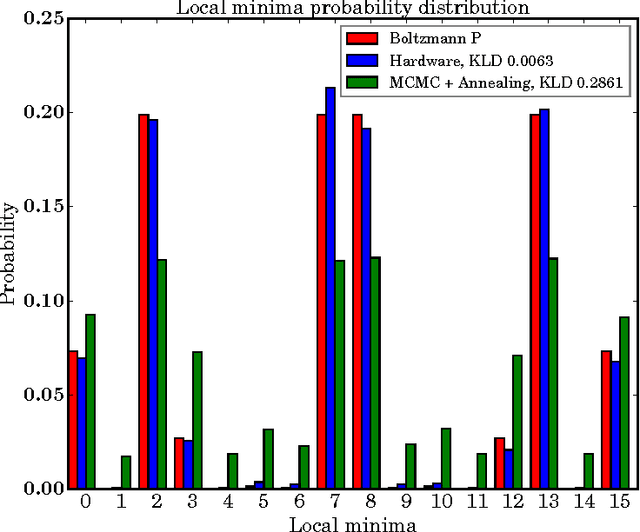
Quantum annealing (QA) is a hardware-based heuristic optimization and sampling method applicable to discrete undirected graphical models. While similar to simulated annealing, QA relies on quantum, rather than thermal, effects to explore complex search spaces. For many classes of problems, QA is known to offer computational advantages over simulated annealing. Here we report on the ability of recent QA hardware to accelerate training of fully visible Boltzmann machines. We characterize the sampling distribution of QA hardware, and show that in many cases, the quantum distributions differ significantly from classical Boltzmann distributions. In spite of this difference, training (which seeks to match data and model statistics) using standard classical gradient updates is still effective. We investigate the use of QA for seeding Markov chains as an alternative to contrastive divergence (CD) and persistent contrastive divergence (PCD). Using $k=50$ Gibbs steps, we show that for problems with high-energy barriers between modes, QA-based seeds can improve upon chains with CD and PCD initializations. For these hard problems, QA gradient estimates are more accurate, and allow for faster learning. Furthermore, and interestingly, even the case of raw QA samples (that is, $k=0$) achieved similar improvements. We argue that this relates to the fact that we are training a quantum rather than classical Boltzmann distribution in this case. The learned parameters give rise to hardware QA distributions closely approximating classical Boltzmann distributions that are hard to train with CD/PCD.