 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Machine Learning Meets Privacy: A Survey and Outlook
Nov 24, 2020
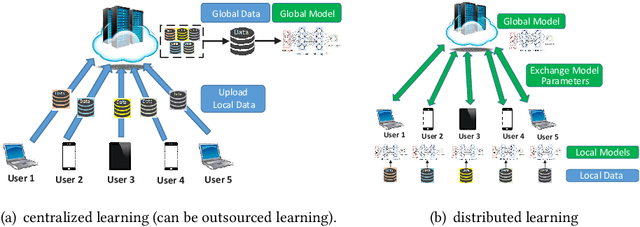
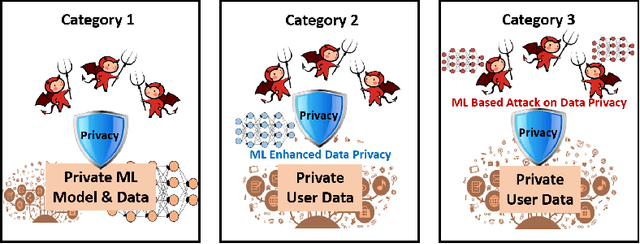
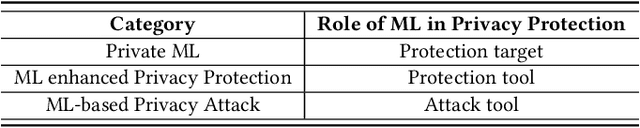
The newly emerged machine learning (e.g. deep learning) methods have become a strong driving force to revolutionize a wide range of industries, such as smart healthcare, financial technology, and surveillance systems. Meanwhile, privacy has emerged as a big concern in this machine learning-based artificial intelligence era. It is important to note that the problem of privacy preservation in the context of machine learning is quite different from that in traditional data privacy protection, as machine learning can act as both friend and foe. Currently, the work on the preservation of privacy and machine learning (ML) is still in an infancy stage, as most existing solutions only focus on privacy problems during the machine learning process. Therefore, a comprehensive study on the privacy preservation problems and machine learning is required. This paper surveys the state of the art in privacy issues and solutions for machine learning. The survey covers three categories of interactions between privacy and machine learning: (i) private machine learning, (ii) machine learning aided privacy protection, and (iii) machine learning-based privacy attack and corresponding protection schemes. The current research progress in each category is reviewed and the key challenges are identified. Finally, based on our in-depth analysis of the area of privacy and machine learning, we point out future research directions in this field.
Distributed Training of Deep Learning Models: A Taxonomic Perspective
Jul 08, 2020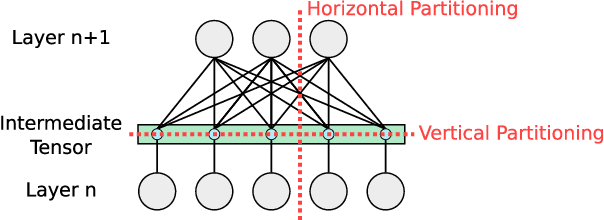
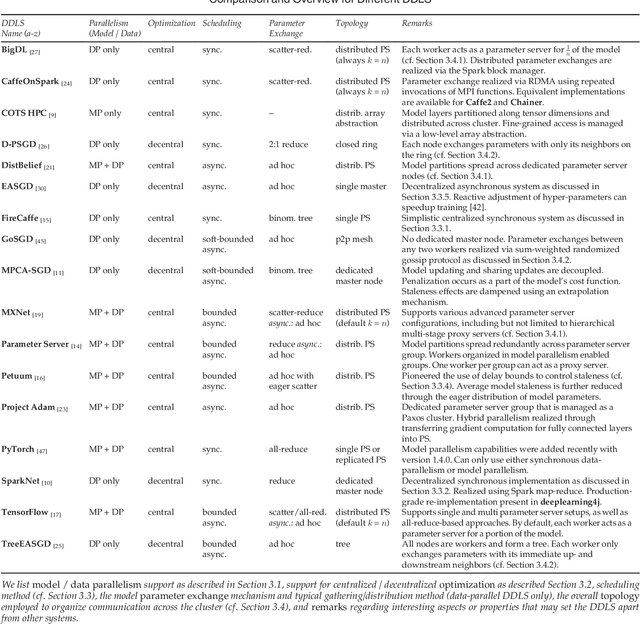
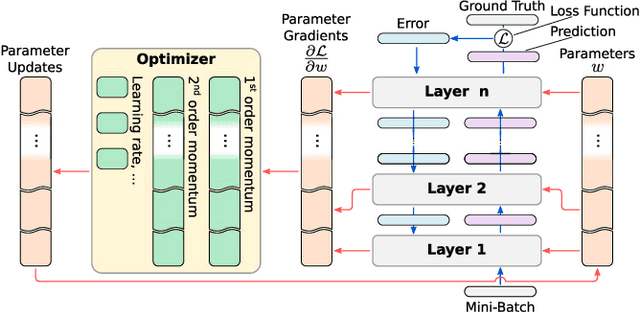
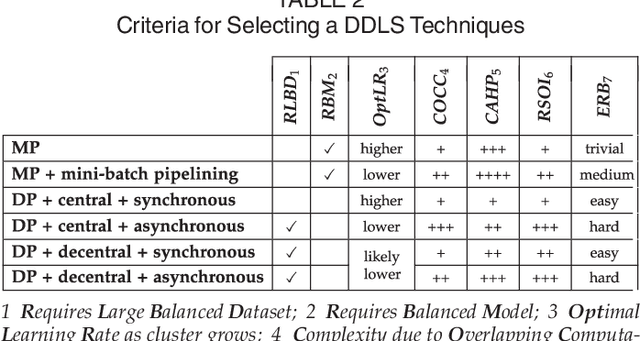
Distributed deep learning systems (DDLS) train deep neural network models by utilizing the distributed resources of a cluster. Developers of DDLS are required to make many decisions to process their particular workloads in their chosen environment efficiently. The advent of GPU-based deep learning, the ever-increasing size of datasets and deep neural network models, in combination with the bandwidth constraints that exist in cluster environments require developers of DDLS to be innovative in order to train high quality models quickly. Comparing DDLS side-by-side is difficult due to their extensive feature lists and architectural deviations. We aim to shine some light on the fundamental principles that are at work when training deep neural networks in a cluster of independent machines by analyzing the general properties associated with training deep learning models and how such workloads can be distributed in a cluster to achieve collaborative model training. Thereby we provide an overview of the different techniques that are used by contemporary DDLS and discuss their influence and implications on the training process. To conceptualize and compare DDLS, we group different techniques into categories, thus establishing a taxonomy of distributed deep learning systems.