 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Personalized Quantum Federated Learning for Anomaly Detection
Nov 08, 2025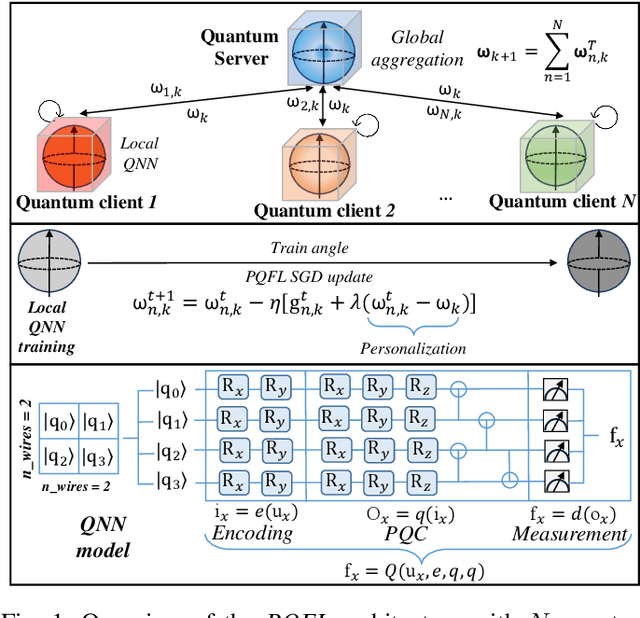

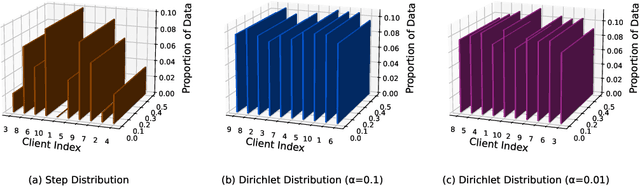
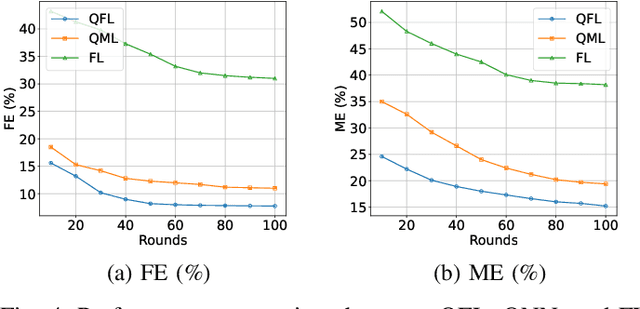
Anomaly detection has a significant impact on applications such as video surveillance, medical diagnostics, and industrial monitoring, where anomalies frequently depend on context and anomaly-labeled data are limited. Quantum federated learning (QFL) overcomes these concerns by distributing model training among several quantum clients, consequently eliminating the requirement for centralized quantum storage and processing. However, in real-life quantum networks, clients frequently differ in terms of hardware capabilities, circuit designs, noise levels, and how classical data is encoded or preprocessed into quantum states. These differences create inherent heterogeneity across clients - not just in their data distributions, but also in their quantum processing behaviors. As a result, training a single global model becomes ineffective, especially when clients handle imbalanced or non-identically distributed (non-IID) data. To address this, we propose a new framework called personalized quantum federated learning (PQFL) for anomaly detection. PQFL enhances local model training at quantum clients using parameterized quantum circuits and classical optimizers, while introducing a quantum-centric personalization strategy that adapts each client's model to its own hardware characteristics and data representation. Extensive experiments show that PQFL significantly improves anomaly detection accuracy under diverse and realistic conditions. Compared to state-of-the-art methods, PQFL reduces false errors by up to 23%, and achieves gains of 24.2% in AUROC and 20.5% in AUPR, highlighting its effectiveness and scalability in practical quantum federated settings.
Holistic Survey of Privacy and Fairness in Machine Learning
Jul 28, 2023Privacy and fairness are two crucial pillars of responsible Artificial Intelligence (AI) and trustworthy Machine Learning (ML). Each objective has been independently studied in the literature with the aim of reducing utility loss in achieving them. Despite the significant interest attracted from both academia and industry, there remains an immediate demand for more in-depth research to unravel how these two objectives can be simultaneously integrated into ML models. As opposed to well-accepted trade-offs, i.e., privacy-utility and fairness-utility, the interrelation between privacy and fairness is not well-understood. While some works suggest a trade-off between the two objective functions, there are others that demonstrate the alignment of these functions in certain scenarios. To fill this research gap, we provide a thorough review of privacy and fairness in ML, including supervised, unsupervised, semi-supervised, and reinforcement learning. After examining and consolidating the literature on both objectives, we present a holistic survey on the impact of privacy on fairness, the impact of fairness on privacy, existing architectures, their interaction in application domains, and algorithms that aim to achieve both objectives while minimizing the utility sacrificed. Finally, we identify research challenges in achieving privacy and fairness concurrently in ML, particularly focusing on large language models.
Learning Dynamic Graphs from All Contextual Information for Accurate Point-of-Interest Visit Forecasting
Jun 28, 2023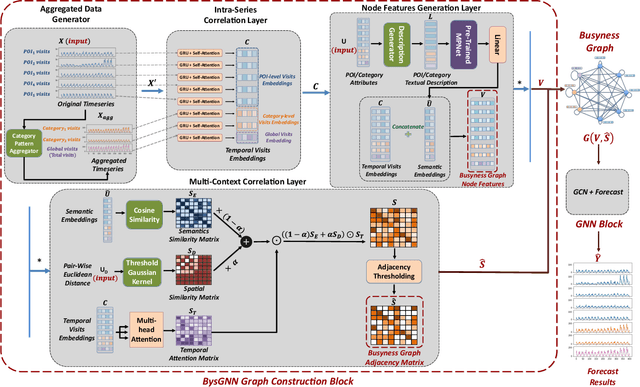

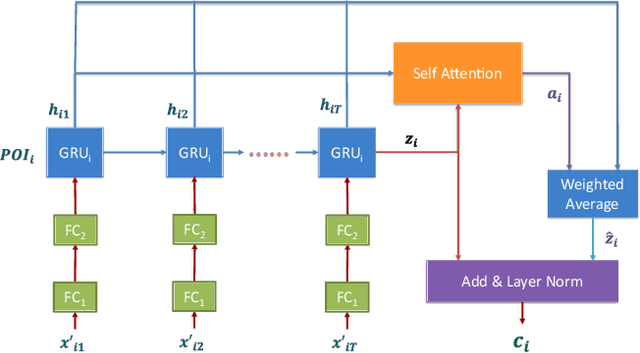

Forecasting the number of visits to Points-of-Interest (POI) in an urban area is critical for planning and decision-making for various application domains, from urban planning and transportation management to public health and social studies. Although this forecasting problem can be formulated as a multivariate time-series forecasting task, the current approaches cannot fully exploit the ever-changing multi-context correlations among POIs. Therefore, we propose Busyness Graph Neural Network (BysGNN), a temporal graph neural network designed to learn and uncover the underlying multi-context correlations between POIs for accurate visit forecasting. Unlike other approaches where only time-series data is used to learn a dynamic graph, BysGNN utilizes all contextual information and time-series data to learn an accurate dynamic graph representation. By incorporating all contextual, temporal, and spatial signals, we observe a significant improvement in our forecasting accuracy over state-of-the-art forecasting models in our experiments with real-world datasets across the United States.
Fair Spatial Indexing: A paradigm for Group Spatial Fairness
Feb 05, 2023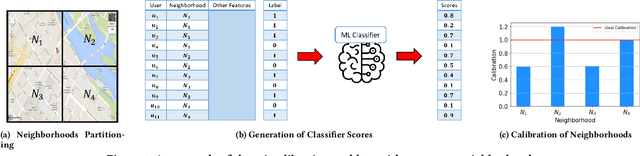

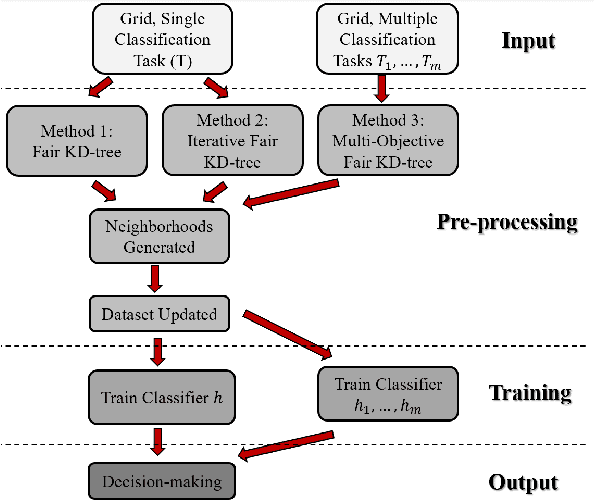
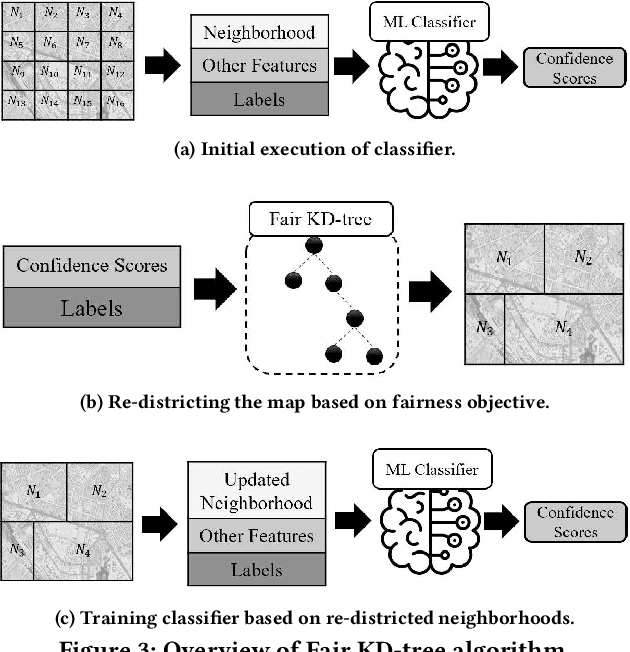
Machine learning (ML) is playing an increasing role in decision-making tasks that directly affect individuals, e.g., loan approvals, or job applicant screening. Significant concerns arise that, without special provisions, individuals from under-privileged backgrounds may not get equitable access to services and opportunities. Existing research studies fairness with respect to protected attributes such as gender, race or income, but the impact of location data on fairness has been largely overlooked. With the widespread adoption of mobile apps, geospatial attributes are increasingly used in ML, and their potential to introduce unfair bias is significant, given their high correlation with protected attributes. We propose techniques to mitigate location bias in machine learning. Specifically, we consider the issue of miscalibration when dealing with geospatial attributes. We focus on spatial group fairness and we propose a spatial indexing algorithm that accounts for fairness. Our KD-tree inspired approach significantly improves fairness while maintaining high learning accuracy, as shown by extensive experimental results on real data.
Models and Mechanisms for Fairness in Location Data Processing
Apr 04, 2022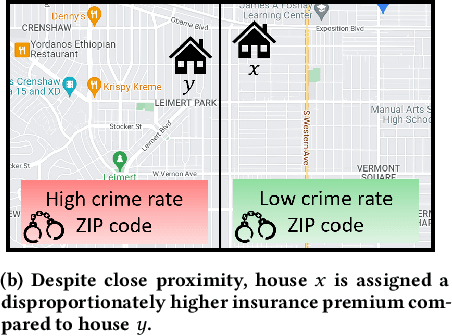
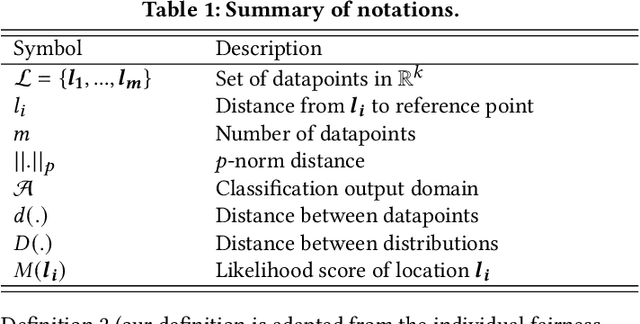

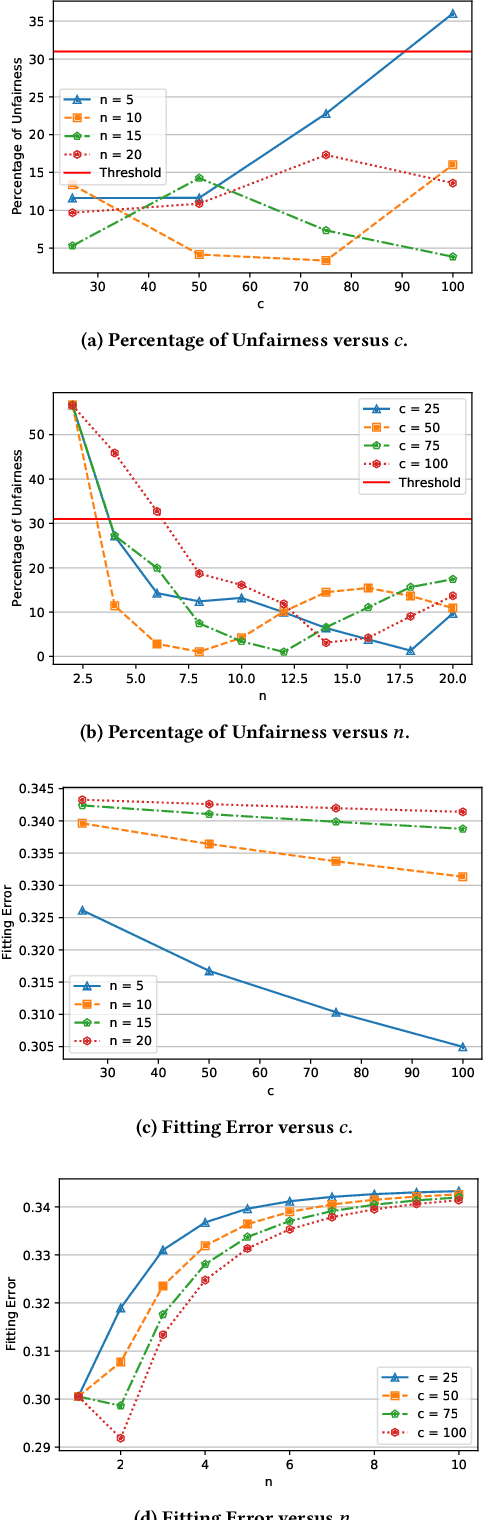
Location data use has become pervasive in the last decade due to the advent of mobile apps, as well as novel areas such as smart health, smart cities, etc. At the same time, significant concerns have surfaced with respect to fairness in data processing. Individuals from certain population segments may be unfairly treated when being considered for loan or job applications, access to public resources, or other types of services. In the case of location data, fairness is an important concern, given that an individual's whereabouts are often correlated with sensitive attributes, e.g., race, income, education. While fairness has received significant attention recently, e.g., in the case of machine learning, there is little focus on the challenges of achieving fairness when dealing with location data. Due to their characteristics and specific type of processing algorithms, location data pose important fairness challenges that must be addressed in a comprehensive and effective manner. In this paper, we adapt existing fairness models to suit the specific properties of location data and spatial processing. We focus on individual fairness, which is more difficult to achieve, and more relevant for most location data processing scenarios. First, we devise a novel building block to achieve fairness in the form of fair polynomials. Then, we propose two mechanisms based on fair polynomials that achieve individual fairness, corresponding to two common interaction types based on location data. Extensive experimental results on real data show that the proposed mechanisms achieve individual location fairness without sacrificing utility.
When Machine Learning Meets Privacy: A Survey and Outlook
Nov 24, 2020
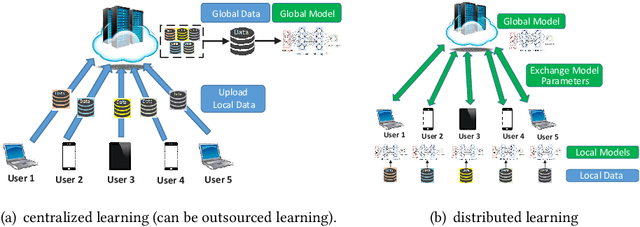
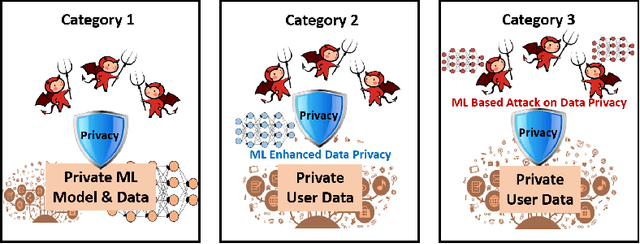
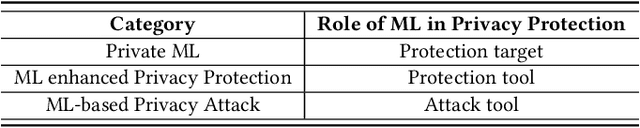
The newly emerged machine learning (e.g. deep learning) methods have become a strong driving force to revolutionize a wide range of industries, such as smart healthcare, financial technology, and surveillance systems. Meanwhile, privacy has emerged as a big concern in this machine learning-based artificial intelligence era. It is important to note that the problem of privacy preservation in the context of machine learning is quite different from that in traditional data privacy protection, as machine learning can act as both friend and foe. Currently, the work on the preservation of privacy and machine learning (ML) is still in an infancy stage, as most existing solutions only focus on privacy problems during the machine learning process. Therefore, a comprehensive study on the privacy preservation problems and machine learning is required. This paper surveys the state of the art in privacy issues and solutions for machine learning. The survey covers three categories of interactions between privacy and machine learning: (i) private machine learning, (ii) machine learning aided privacy protection, and (iii) machine learning-based privacy attack and corresponding protection schemes. The current research progress in each category is reviewed and the key challenges are identified. Finally, based on our in-depth analysis of the area of privacy and machine learning, we point out future research directions in this field.
Machine Learning Aided Anonymization of Spatiotemporal Trajectory Datasets
Feb 24, 2019
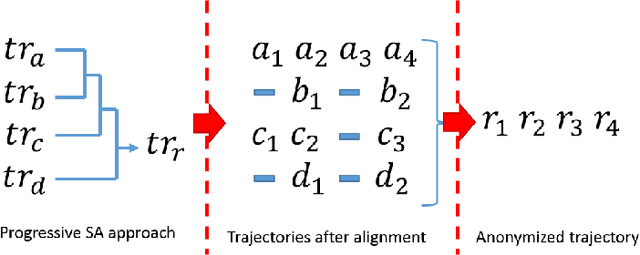
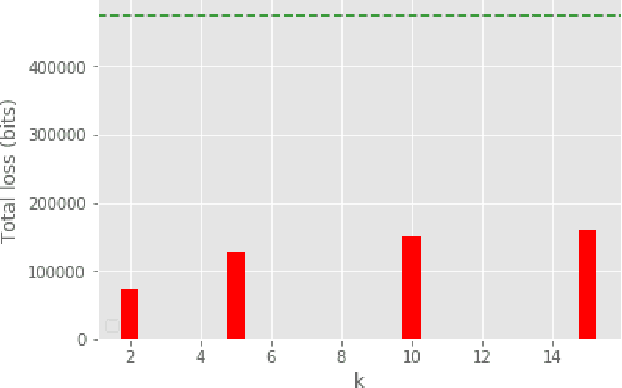
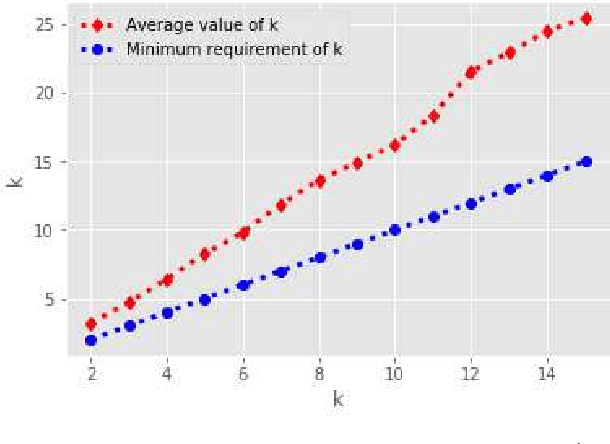
The big data era requires a growing number of companies to publish their data publicly. Preserving the privacy of users while publishing these data has become a critical problem. One of the most sensitive sources of data is spatiotemporal trajectory datasets. Such datasets are extremely sensitive as users' personal information such as home address, workplace and shopping habits can be inferred from them. In this paper, we propose an approach for anonymization of spatiotemporal trajectory datasets. The proposed approach is based on generalization entailing alignment and clustering of trajectories. We propose to apply $k'$-means algorithm for clustering trajectories by developing a technique that makes it possible. We also significantly reduce the information loss during the alignment by incorporating multiple sequence alignment instead of pairwise sequence alignment used in the literature. We analyze the performance of our proposed approach by applying it to Geolife dataset, which includes GPS logs of over 180 users in Beijing, China. Our experiments indicate the robustness of our framework compared to prior works.
Privacy Preservation in Location-Based Services: A Novel Metric and Attack Model
May 16, 2018
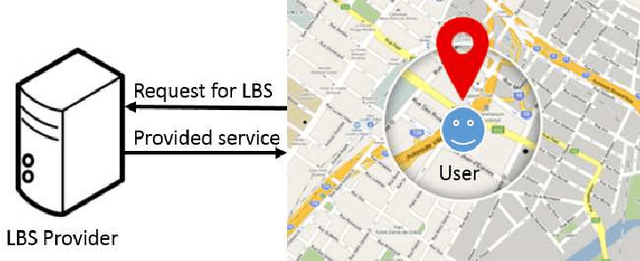
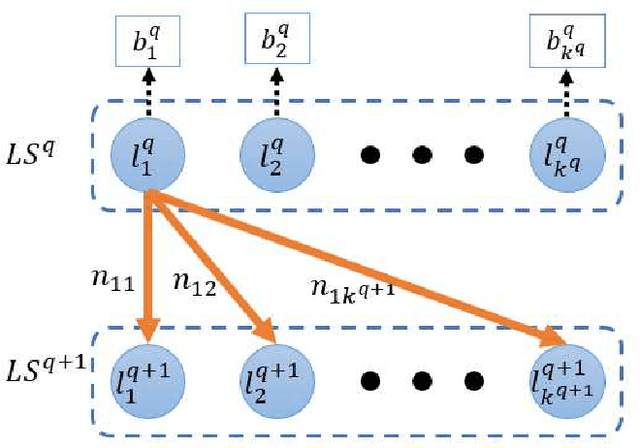
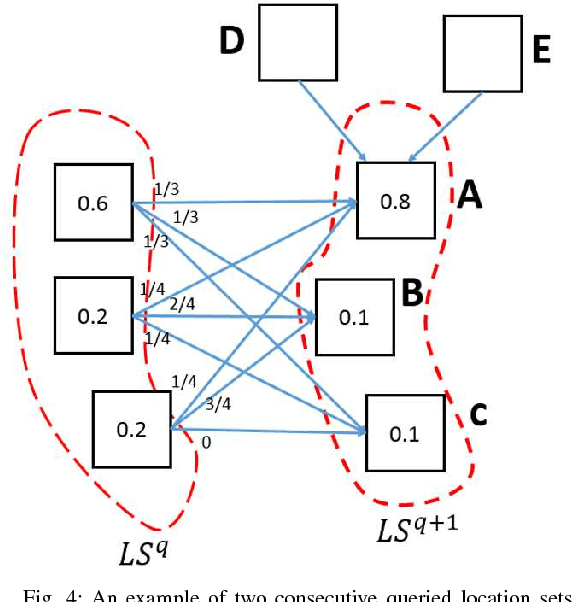
Recent years have seen rising needs for location-based services in our everyday life. Aside from the many advantages provided by these services, they have caused serious concerns regarding the location privacy of users. An adversary such as an untrusted location-based server can monitor the queried locations by a user to infer critical information such as the user's home address, health conditions, shopping habits, etc. To address this issue, dummy-based algorithms have been developed to increase the anonymity of users, and thus, protecting their privacy. Unfortunately, the existing algorithms only consider a limited amount of side information known by an adversary which may face more serious challenges in practice. In this paper, we incorporate a new type of side information based on consecutive location changes of users and propose a new metric called transition-entropy to investigate the location privacy preservation, followed by two algorithms to improve the transition-entropy for a given dummy generation algorithm. Then, we develop an attack model based on the Viterbi algorithm which can significantly threaten the location privacy of the users. Next, in order to protect the users from Viterbi attack, we propose an algorithm called robust dummy generation (RDG) which can resist against the Viterbi attack while maintaining a high performance in terms of the privacy metrics introduced in the paper. All the algorithms are applied and analyzed on a real-life dataset.