 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFair Spatial Indexing: A paradigm for Group Spatial Fairness
Paper and Code
Feb 05, 2023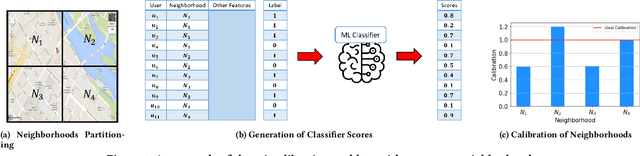

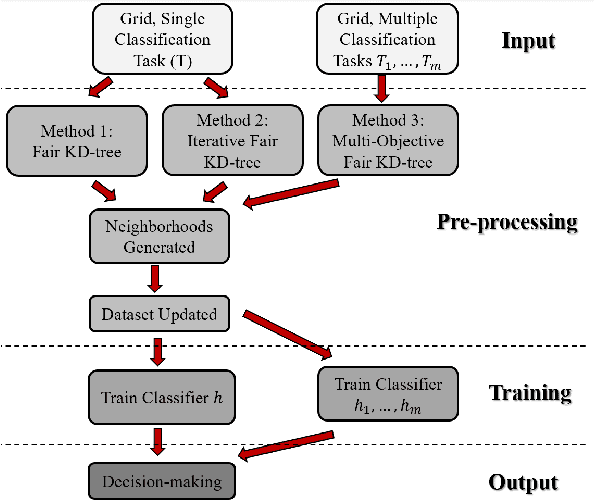
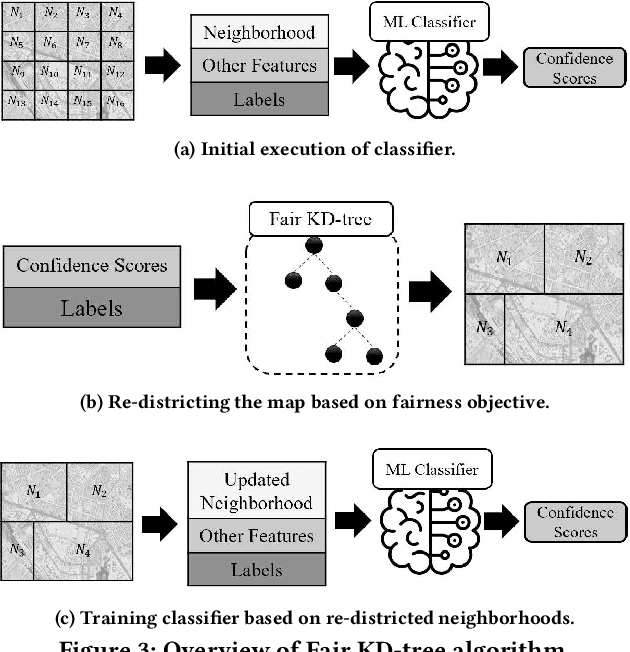
Machine learning (ML) is playing an increasing role in decision-making tasks that directly affect individuals, e.g., loan approvals, or job applicant screening. Significant concerns arise that, without special provisions, individuals from under-privileged backgrounds may not get equitable access to services and opportunities. Existing research studies fairness with respect to protected attributes such as gender, race or income, but the impact of location data on fairness has been largely overlooked. With the widespread adoption of mobile apps, geospatial attributes are increasingly used in ML, and their potential to introduce unfair bias is significant, given their high correlation with protected attributes. We propose techniques to mitigate location bias in machine learning. Specifically, we consider the issue of miscalibration when dealing with geospatial attributes. We focus on spatial group fairness and we propose a spatial indexing algorithm that accounts for fairness. Our KD-tree inspired approach significantly improves fairness while maintaining high learning accuracy, as shown by extensive experimental results on real data.