 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeoGR: A Generative Retrieval Framework for Spatio-Temporal Aware POI Recommendation
Feb 11, 2026Next Point-of-Interest (POI) prediction is a fundamental task in location-based services, especially critical for large-scale navigation platforms like AMAP that serve billions of users across diverse lifestyle scenarios. While recent POI recommendation approaches based on SIDs have achieved promising, they struggle in complex, sparse real-world environments due to two key limitations: (1) inadequate modeling of high-quality SIDs that capture cross-category spatio-temporal collaborative relationships, and (2) poor alignment between large language models (LLMs) and the POI recommendation task. To this end, we propose GeoGR, a geographic generative recommendation framework tailored for navigation-based LBS like AMAP, which perceives users' contextual state changes and enables intent-aware POI recommendation. GeoGR features a two-stage design: (i) a geo-aware SID tokenization pipeline that explicitly learns spatio-temporal collaborative semantic representations via geographically constrained co-visited POI pairs, contrastive learning, and iterative refinement; and (ii) a multi-stage LLM training strategy that aligns non-native SID tokens through multiple template-based continued pre-training(CPT) and enables autoregressive POI generation via supervised fine-tuning(SFT). Extensive experiments on multiple real-world datasets demonstrate GeoGR's superiority over state-of-the-art baselines. Moreover, deployment on the AMAP platform, serving millions of users with multiple online metrics boosting, confirms its practical effectiveness and scalability in production.
LLM-Driven Multi-step Translation from C to Rust using Static Analysis
Mar 16, 2025

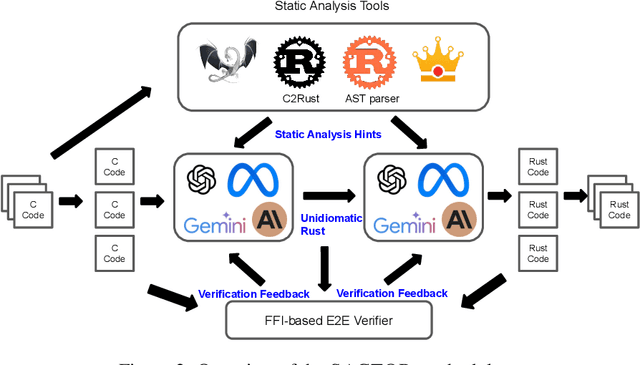

Translating software written in legacy languages to modern languages, such as C to Rust, has significant benefits in improving memory safety while maintaining high performance. However, manual translation is cumbersome, error-prone, and produces unidiomatic code. Large language models (LLMs) have demonstrated promise in producing idiomatic translations, but offer no correctness guarantees as they lack the ability to capture all the semantics differences between the source and target languages. To resolve this issue, we propose SACTOR, an LLM-driven C-to-Rust zero-shot translation tool using a two-step translation methodology: an "unidiomatic" step to translate C into Rust while preserving semantics, and an "idiomatic" step to refine the code to follow Rust's semantic standards. SACTOR utilizes information provided by static analysis of the source C program to address challenges such as pointer semantics and dependency resolution. To validate the correctness of the translated result from each step, we use end-to-end testing via the foreign function interface to embed our translated code segment into the original code. We evaluate the translation of 200 programs from two datasets and two case studies, comparing the performance of GPT-4o, Claude 3.5 Sonnet, Gemini 2.0 Flash, Llama 3.3 70B and DeepSeek-R1 in SACTOR. Our results demonstrate that SACTOR achieves high correctness and improved idiomaticity, with the best-performing model (DeepSeek-R1) reaching 93% and (GPT-4o, Claude 3.5, DeepSeek-R1) reaching 84% correctness (on each dataset, respectively), while producing more natural and Rust-compliant translations compared to existing methods.
Geo-Llama: Leveraging LLMs for Human Mobility Trajectory Generation with Spatiotemporal Constraints
Aug 25, 2024



Simulating human mobility data is essential for various application domains, including transportation, urban planning, and epidemic control, since real data are often inaccessible to researchers due to expensive costs and privacy issues. Several existing deep generative solutions propose learning from real trajectories to generate synthetic ones. Despite the progress, most of them suffer from training stability issues and scale poorly with growing data size. More importantly, they generally lack control mechanisms to steer the generated trajectories based on spatiotemporal constraints such as fixing specific visits. To address such limitations, we formally define the controlled trajectory generation problem with spatiotemporal constraints and propose Geo-Llama. This novel LLM-inspired framework enforces explicit visit constraints in a contextually coherent way. It fine-tunes pre-trained LLMs on trajectories with a visit-wise permutation strategy where each visit corresponds to a time and location. This enables the model to capture the spatiotemporal patterns regardless of visit orders and allows flexible and in-context constraint integration through prompts during generation. Extensive experiments on real-world and synthetic datasets validate the effectiveness of Geo-Llama, demonstrating its versatility and robustness in handling a broad range of constraints to generate more realistic trajectories compared to existing methods.
Dynamic GNNs for Precise Seizure Detection and Classification from EEG Data
May 08, 2024Diagnosing epilepsy requires accurate seizure detection and classification, but traditional manual EEG signal analysis is resource-intensive. Meanwhile, automated algorithms often overlook EEG's geometric and semantic properties critical for interpreting brain activity. This paper introduces NeuroGNN, a dynamic Graph Neural Network (GNN) framework that captures the dynamic interplay between the EEG electrode locations and the semantics of their corresponding brain regions. The specific brain region where an electrode is placed critically shapes the nature of captured EEG signals. Each brain region governs distinct cognitive functions, emotions, and sensory processing, influencing both the semantic and spatial relationships within the EEG data. Understanding and modeling these intricate brain relationships are essential for accurate and meaningful insights into brain activity. This is precisely where the proposed NeuroGNN framework excels by dynamically constructing a graph that encapsulates these evolving spatial, temporal, semantic, and taxonomic correlations to improve precision in seizure detection and classification. Our extensive experiments with real-world data demonstrate that NeuroGNN significantly outperforms existing state-of-the-art models.
* This preprint has not undergone any post-submission improvements or corrections. The Version of Record of this contribution is published in the proceedings of the 28th Pacific-Asia Conference on Knowledge Discovery and Data Mining (PAKDD 2024), Taipei, Taiwan, May 7-10, 2024, and is available online at https://doi.org/10.1007/978-981-97-2238-9_16
Learning Dynamic Graphs from All Contextual Information for Accurate Point-of-Interest Visit Forecasting
Jun 28, 2023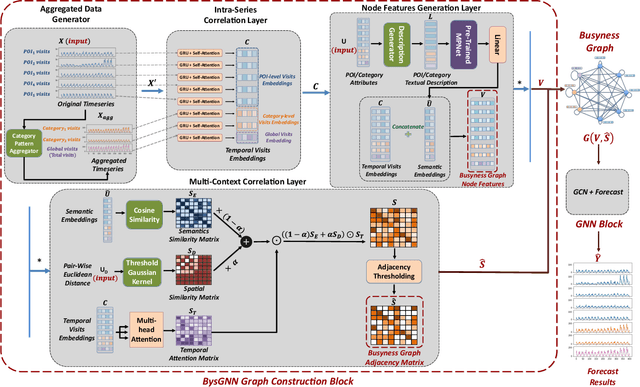

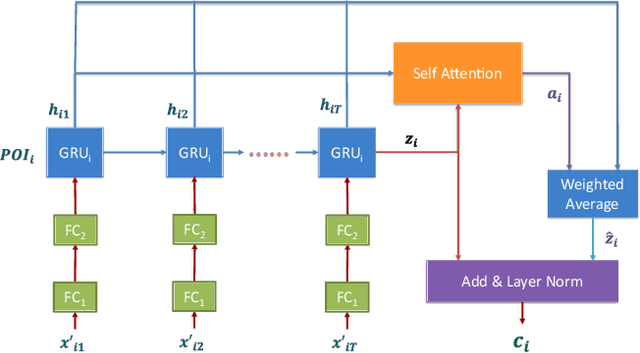

Forecasting the number of visits to Points-of-Interest (POI) in an urban area is critical for planning and decision-making for various application domains, from urban planning and transportation management to public health and social studies. Although this forecasting problem can be formulated as a multivariate time-series forecasting task, the current approaches cannot fully exploit the ever-changing multi-context correlations among POIs. Therefore, we propose Busyness Graph Neural Network (BysGNN), a temporal graph neural network designed to learn and uncover the underlying multi-context correlations between POIs for accurate visit forecasting. Unlike other approaches where only time-series data is used to learn a dynamic graph, BysGNN utilizes all contextual information and time-series data to learn an accurate dynamic graph representation. By incorporating all contextual, temporal, and spatial signals, we observe a significant improvement in our forecasting accuracy over state-of-the-art forecasting models in our experiments with real-world datasets across the United States.
Clustering Human Mobility with Multiple Spaces
Jan 20, 2023Human mobility clustering is an important problem for understanding human mobility behaviors (e.g., work and school commutes). Existing methods typically contain two steps: choosing or learning a mobility representation and applying a clustering algorithm to the representation. However, these methods rely on strict visiting orders in trajectories and cannot take advantage of multiple types of mobility representations. This paper proposes a novel mobility clustering method for mobility behavior detection. First, the proposed method contains a permutation-equivalent operation to handle sub-trajectories that might have different visiting orders but similar impacts on mobility behaviors. Second, the proposed method utilizes a variational autoencoder architecture to simultaneously perform clustering in both latent and original spaces. Also, in order to handle the bias of a single latent space, our clustering assignment prediction considers multiple learned latent spaces at different epochs. This way, the proposed method produces accurate results and can provide reliability estimates of each trajectory's cluster assignment. The experiment shows that the proposed method outperformed state-of-the-art methods in mobility behavior detection from trajectories with better accuracy and more interpretability.
Integer-arithmetic-only Certified Robustness for Quantized Neural Networks
Aug 21, 2021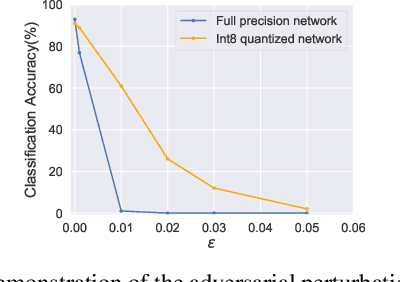

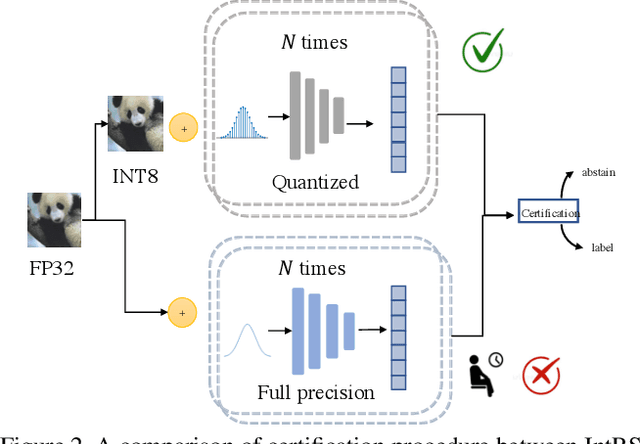

Adversarial data examples have drawn significant attention from the machine learning and security communities. A line of work on tackling adversarial examples is certified robustness via randomized smoothing that can provide a theoretical robustness guarantee. However, such a mechanism usually uses floating-point arithmetic for calculations in inference and requires large memory footprints and daunting computational costs. These defensive models cannot run efficiently on edge devices nor be deployed on integer-only logical units such as Turing Tensor Cores or integer-only ARM processors. To overcome these challenges, we propose an integer randomized smoothing approach with quantization to convert any classifier into a new smoothed classifier, which uses integer-only arithmetic for certified robustness against adversarial perturbations. We prove a tight robustness guarantee under L2-norm for the proposed approach. We show our approach can obtain a comparable accuracy and 4x~5x speedup over floating-point arithmetic certified robust methods on general-purpose CPUs and mobile devices on two distinct datasets (CIFAR-10 and Caltech-101).
SemiFed: Semi-supervised Federated Learning with Consistency and Pseudo-Labeling
Aug 21, 2021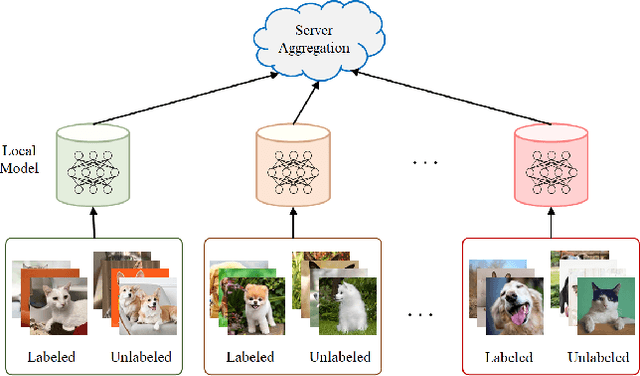
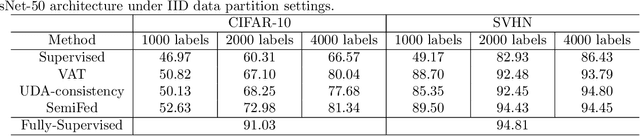
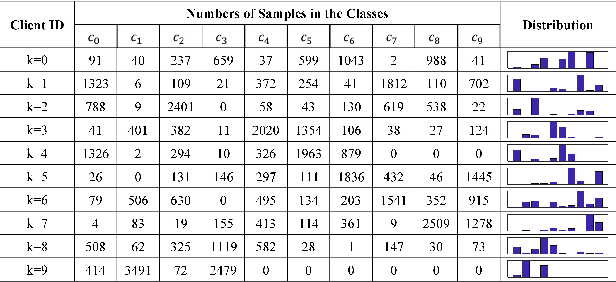
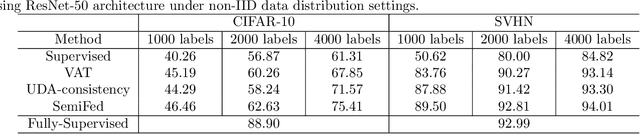
Federated learning enables multiple clients, such as mobile phones and organizations, to collaboratively learn a shared model for prediction while protecting local data privacy. However, most recent research and applications of federated learning assume that all clients have fully labeled data, which is impractical in real-world settings. In this work, we focus on a new scenario for cross-silo federated learning, where data samples of each client are partially labeled. We borrow ideas from semi-supervised learning methods where a large amount of unlabeled data is utilized to improve the model's accuracy despite limited access to labeled examples. We propose a new framework dubbed SemiFed that unifies two dominant approaches for semi-supervised learning: consistency regularization and pseudo-labeling. SemiFed first applies advanced data augmentation techniques to enforce consistency regularization and then generates pseudo-labels using the model's predictions during training. SemiFed takes advantage of the federation so that for a given image, the pseudo-label holds only if multiple models from different clients produce a high-confidence prediction and agree on the same label. Extensive experiments on two image benchmarks demonstrate the effectiveness of our approach under both homogeneous and heterogeneous data distribution settings