 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemiFed: Semi-supervised Federated Learning with Consistency and Pseudo-Labeling
Paper and Code
Aug 21, 2021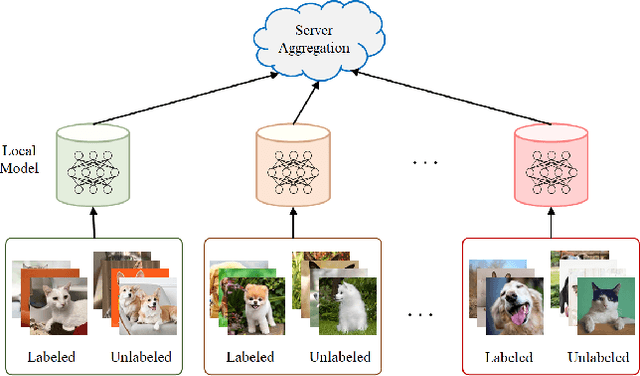
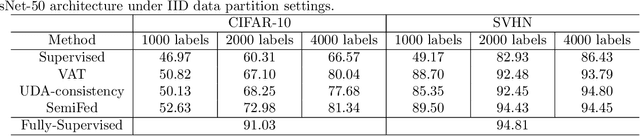
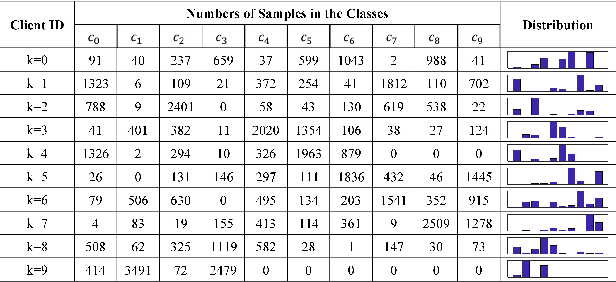
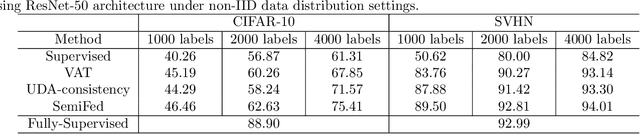
Federated learning enables multiple clients, such as mobile phones and organizations, to collaboratively learn a shared model for prediction while protecting local data privacy. However, most recent research and applications of federated learning assume that all clients have fully labeled data, which is impractical in real-world settings. In this work, we focus on a new scenario for cross-silo federated learning, where data samples of each client are partially labeled. We borrow ideas from semi-supervised learning methods where a large amount of unlabeled data is utilized to improve the model's accuracy despite limited access to labeled examples. We propose a new framework dubbed SemiFed that unifies two dominant approaches for semi-supervised learning: consistency regularization and pseudo-labeling. SemiFed first applies advanced data augmentation techniques to enforce consistency regularization and then generates pseudo-labels using the model's predictions during training. SemiFed takes advantage of the federation so that for a given image, the pseudo-label holds only if multiple models from different clients produce a high-confidence prediction and agree on the same label. Extensive experiments on two image benchmarks demonstrate the effectiveness of our approach under both homogeneous and heterogeneous data distribution settings