 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttention and Autoencoder Hybrid Model for Unsupervised Online Anomaly Detection
Jan 06, 2024This paper introduces a hybrid attention and autoencoder (AE) model for unsupervised online anomaly detection in time series. The autoencoder captures local structural patterns in short embeddings, while the attention model learns long-term features, facilitating parallel computing with positional encoding. Unique in its approach, our proposed hybrid model combines attention and autoencoder for the first time in time series anomaly detection. It employs an attention-based mechanism, akin to the deep transformer model, with key architectural modifications for predicting the next time step window in the autoencoder's latent space. The model utilizes a threshold from the validation dataset for anomaly detection and introduces an alternative method based on analyzing the first statistical moment of error, improving accuracy without dependence on a validation dataset. Evaluation on diverse real-world benchmark datasets and comparing with other well-established models, confirms the effectiveness of our proposed model in anomaly detection.
Interpretable Reinforcement Learning Inspired by Piaget's Theory of Cognitive Development
Feb 01, 2021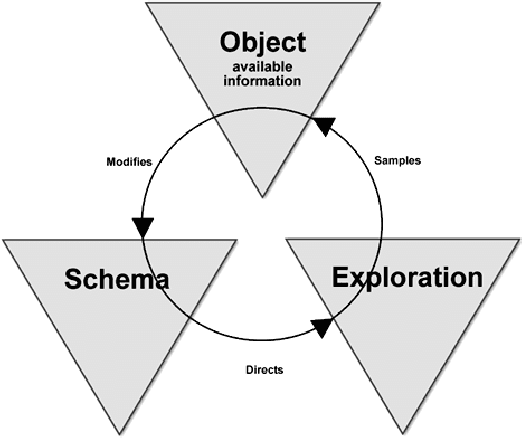

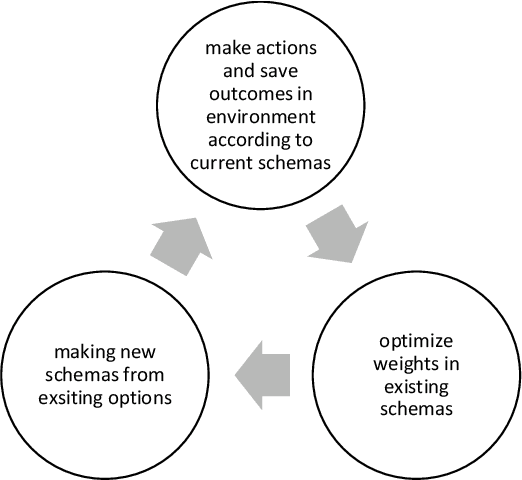
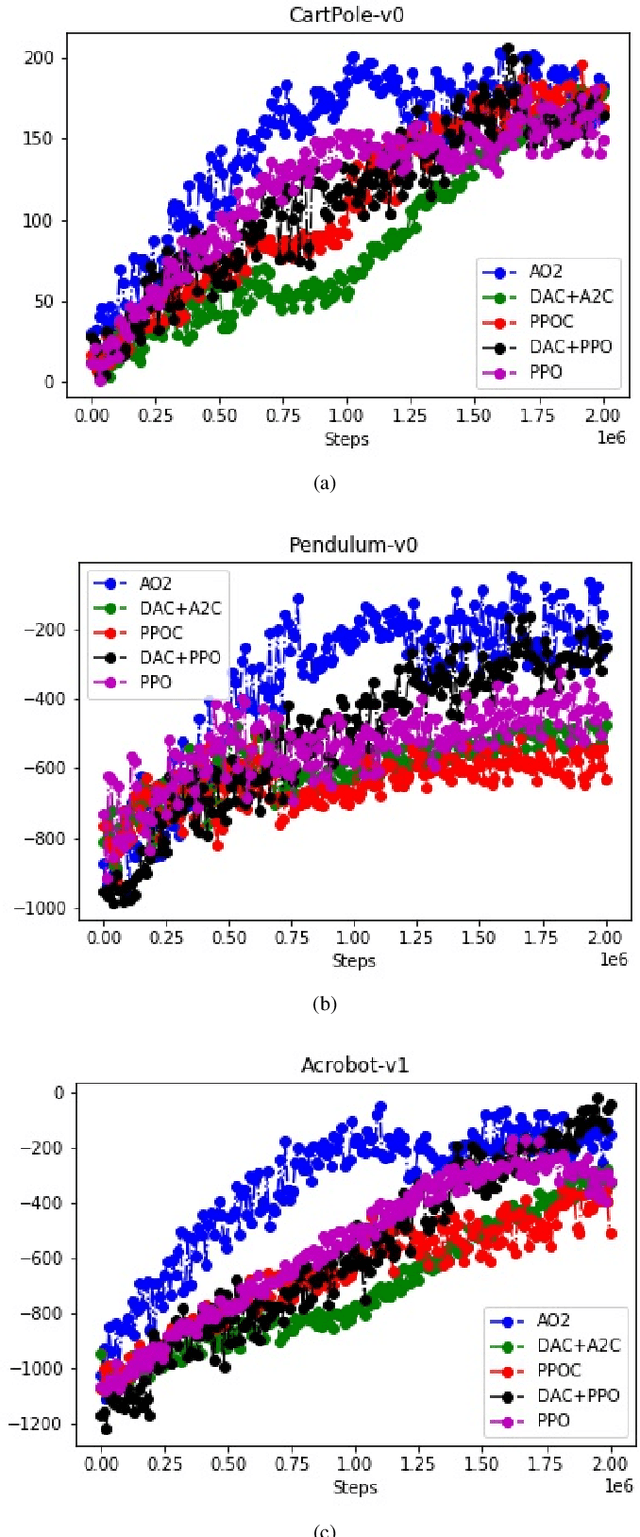
Endeavors for designing robots with human-level cognitive abilities have led to different categories of learning machines. According to Skinner's theory, reinforcement learning (RL) plays a key role in human intuition and cognition. Majority of the state-of-the-art methods including deep RL algorithms are strongly influenced by the connectionist viewpoint. Such algorithms can significantly benefit from theories of mind and learning in other disciplines. This paper entertains the idea that theories such as language of thought hypothesis (LOTH), script theory, and Piaget's cognitive development theory provide complementary approaches, which will enrich the RL field. Following this line of thinking, a general computational building block is proposed for Piaget's schema theory that supports the notions of productivity, systematicity, and inferential coherence as described by Fodor in contrast with the connectionism theory. Abstraction in the proposed method is completely upon the system itself and is not externally constrained by any predefined architecture. The whole process matches the Neisser's perceptual cycle model. Performed experiments on three typical control problems followed by behavioral analysis confirm the interpretability of the proposed method and its competitiveness compared to the state-of-the-art algorithms. Hence, the proposed framework can be viewed as a step towards achieving human-like cognition in artificial intelligent systems.
Urban Change Detection by Fully Convolutional Siamese Concatenate Network with Attention
Jan 31, 2021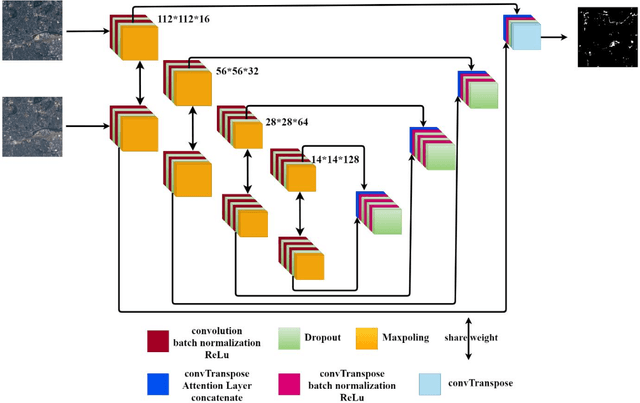
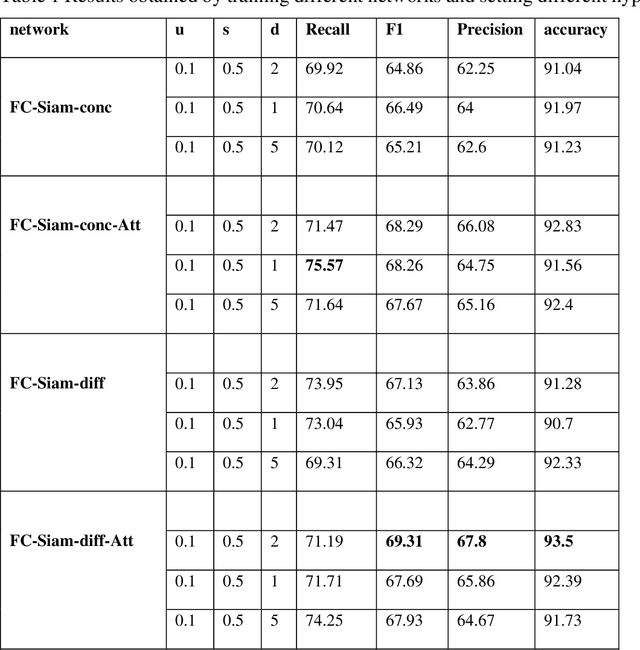
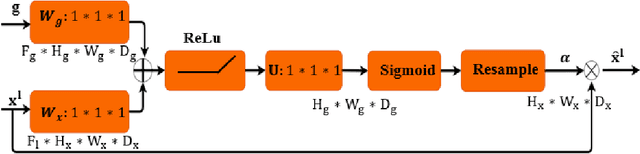
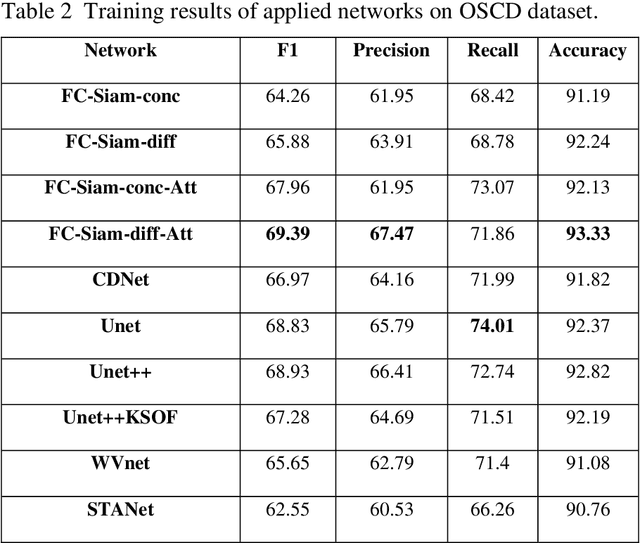
Change detection (CD) is an important problem in remote sensing, especially in disaster time for urban management. Most existing traditional methods for change detection are categorized based on pixel or objects. Object-based models are preferred to pixel-based methods for handling very high-resolution remote sensing (VHR RS) images. Such methods can benefit from the ongoing research on deep learning. In this paper, a fully automatic change-detection algorithm on VHR RS images is proposed that deploys Fully Convolutional Siamese Concatenate networks (FC-Siam-Conc). The proposed method uses preprocessing and an attention gate layer to improve accuracy. Gaussian attention (GA) as a soft visual attention mechanism is used for preprocessing. GA helps the network to handle feature maps like biological visual systems. Since the GA parameters cannot be adjusted during network training, an attention gate layer is introduced to play the role of GA with parameters that can be tuned among other network parameters. Experimental results obtained on Onera Satellite Change Detection (OSCD) and RIVER-CD datasets confirm the superiority of the proposed architecture over the state-of-the-art algorithms.
Enacted Visual Perception: A Computational Model based on Piaget Equilibrium
Jan 30, 2021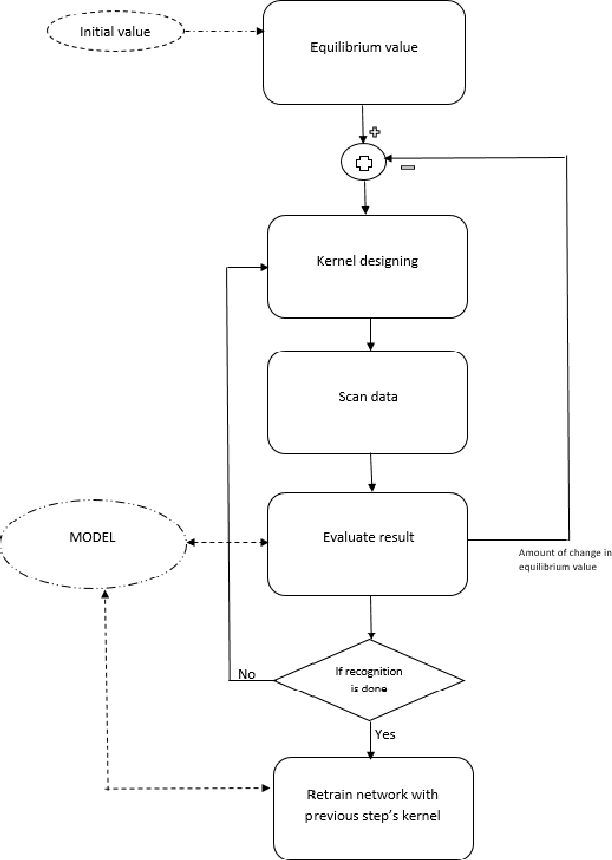
In Maurice Merleau-Ponty's phenomenology of perception, analysis of perception accounts for an element of intentionality, and in effect therefore, perception and action cannot be viewed as distinct procedures. In the same line of thinking, Alva No\"{e} considers perception as a thoughtful activity that relies on capacities for action and thought. Here, by looking into psychology as a source of inspiration, we propose a computational model for the action involved in visual perception based on the notion of equilibrium as defined by Jean Piaget. In such a model, Piaget's equilibrium reflects the mind's status, which is used to control the observation process. The proposed model is built around a modified version of convolutional neural networks (CNNs) with enhanced filter performance, where characteristics of filters are adaptively adjusted via a high-level control signal that accounts for the thoughtful activity in perception. While the CNN plays the role of the visual system, the control signal is assumed to be a product of mind.
Deep Reinforcement Learning-Based Product Recommender for Online Advertising
Jan 30, 2021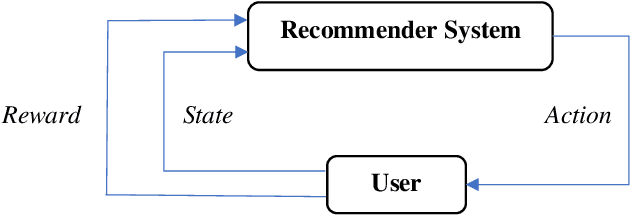
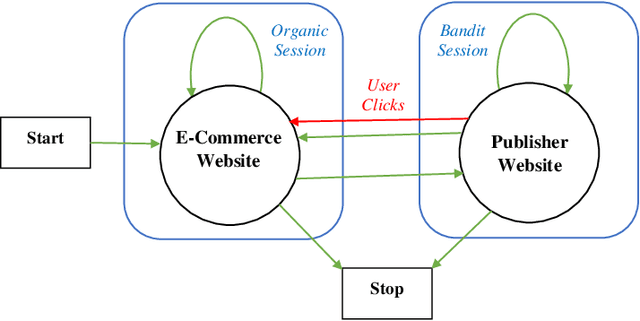
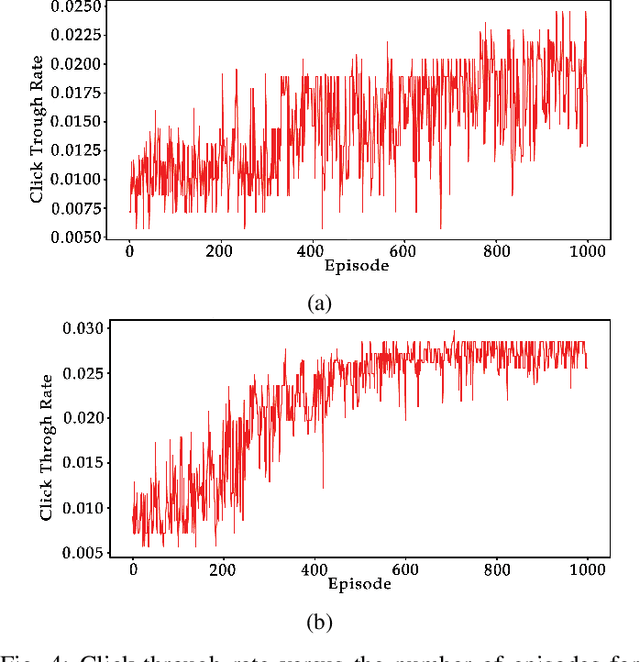
In online advertising, recommender systems try to propose items from a list of products to potential customers according to their interests. Such systems have been increasingly deployed in E-commerce due to the rapid growth of information technology and availability of large datasets. The ever-increasing progress in the field of artificial intelligence has provided powerful tools for dealing with such real-life problems. Deep reinforcement learning (RL) that deploys deep neural networks as universal function approximators can be viewed as a valid approach for design and implementation of recommender systems. This paper provides a comparative study between value-based and policy-based deep RL algorithms for designing recommender systems for online advertising. The RecoGym environment is adopted for training these RL-based recommender systems, where the long short term memory (LSTM) is deployed to build value and policy networks in these two approaches, respectively. LSTM is used to take account of the key role that order plays in the sequence of item observations by users. The designed recommender systems aim at maximising the click-through rate (CTR) for the recommended items. Finally, guidelines are provided for choosing proper RL algorithms for different scenarios that the recommender system is expected to handle.
Metalearning: Sparse Variable-Structure Automata
Jan 30, 2021
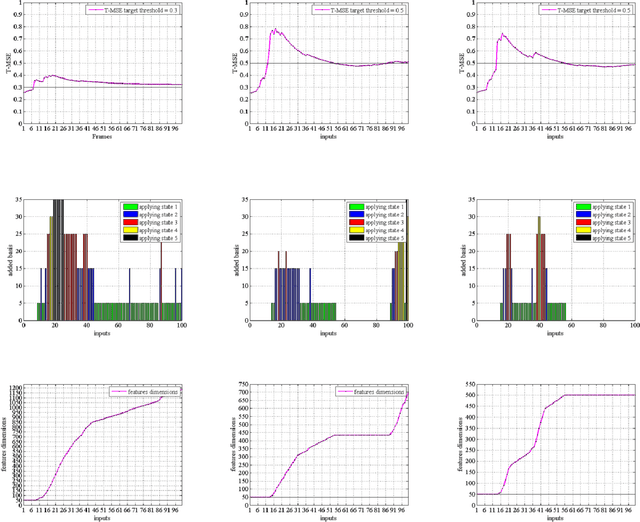
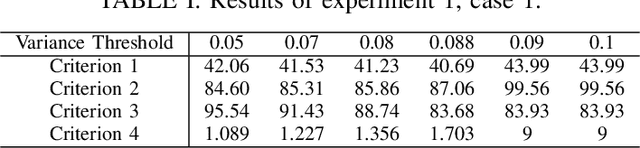
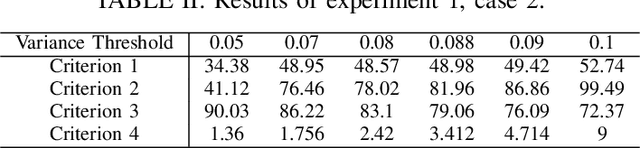
Dimension of the encoder output (i.e., the code layer) in an autoencoder is a key hyper-parameter for representing the input data in a proper space. This dimension must be carefully selected in order to guarantee the desired reconstruction accuracy. Although overcomplete representation can address this dimension issue, the computational complexity will increase with dimension. Inspired by non-parametric methods, here, we propose a metalearning approach to increase the number of basis vectors used in dynamic sparse coding on the fly. An actor-critic algorithm is deployed to automatically choose an appropriate dimension for feature vectors regarding the required level of accuracy. The proposed method benefits from online dictionary learning and fast iterative shrinkage-thresholding algorithm (FISTA) as the optimizer in the inference phase. It aims at choosing the minimum number of bases for the overcomplete representation regarding the reconstruction error threshold. This method allows for online controlling of both the representation dimension and the reconstruction error in a dynamic framework.