 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeH-Net: A Multitask Architecture for Simultaneous 3D Force Estimation and Stereo Semantic Segmentation in Intracardiac Catheters
Dec 31, 2024



The success rate of catheterization procedures is closely linked to the sensory data provided to the surgeon. Vision-based deep learning models can deliver both tactile and visual information in a sensor-free manner, while also being cost-effective to produce. Given the complexity of these models for devices with limited computational resources, research has focused on force estimation and catheter segmentation separately. However, there is a lack of a comprehensive architecture capable of simultaneously segmenting the catheter from two different angles and estimating the applied forces in 3D. To bridge this gap, this work proposes a novel, lightweight, multi-input, multi-output encoder-decoder-based architecture. It is designed to segment the catheter from two points of view and concurrently measure the applied forces in the x, y, and z directions. This network processes two simultaneous X-Ray images, intended to be fed by a biplane fluoroscopy system, showing a catheter's deflection from different angles. It uses two parallel sub-networks with shared parameters to output two segmentation maps corresponding to the inputs. Additionally, it leverages stereo vision to estimate the applied forces at the catheter's tip in 3D. The architecture features two input channels, two classification heads for segmentation, and a regression head for force estimation through a single end-to-end architecture. The output of all heads was assessed and compared with the literature, demonstrating state-of-the-art performance in both segmentation and force estimation. To the best of the authors' knowledge, this is the first time such a model has been proposed
Metalearning: Sparse Variable-Structure Automata
Jan 30, 2021
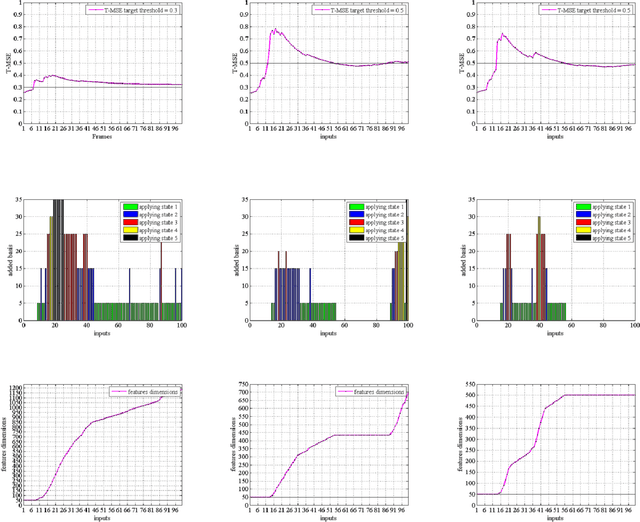
Dimension of the encoder output (i.e., the code layer) in an autoencoder is a key hyper-parameter for representing the input data in a proper space. This dimension must be carefully selected in order to guarantee the desired reconstruction accuracy. Although overcomplete representation can address this dimension issue, the computational complexity will increase with dimension. Inspired by non-parametric methods, here, we propose a metalearning approach to increase the number of basis vectors used in dynamic sparse coding on the fly. An actor-critic algorithm is deployed to automatically choose an appropriate dimension for feature vectors regarding the required level of accuracy. The proposed method benefits from online dictionary learning and fast iterative shrinkage-thresholding algorithm (FISTA) as the optimizer in the inference phase. It aims at choosing the minimum number of bases for the overcomplete representation regarding the reconstruction error threshold. This method allows for online controlling of both the representation dimension and the reconstruction error in a dynamic framework.