 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProfiling Neural Blocks and Design Spaces for Mobile Neural Architecture Search
Sep 25, 2021
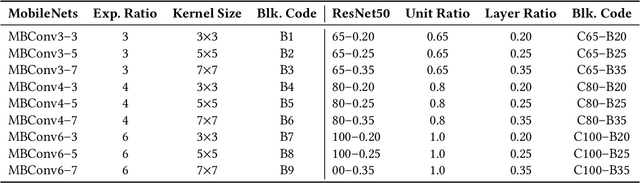
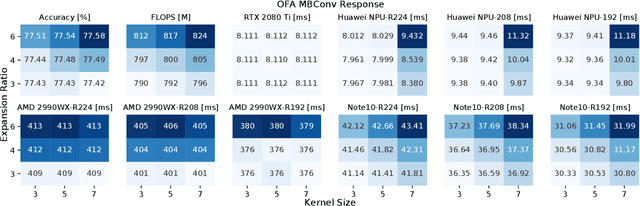
Neural architecture search automates neural network design and has achieved state-of-the-art results in many deep learning applications. While recent literature has focused on designing networks to maximize accuracy, little work has been conducted to understand the compatibility of architecture design spaces to varying hardware. In this paper, we analyze the neural blocks used to build Once-for-All (MobileNetV3), ProxylessNAS and ResNet families, in order to understand their predictive power and inference latency on various devices, including Huawei Kirin 9000 NPU, RTX 2080 Ti, AMD Threadripper 2990WX, and Samsung Note10. We introduce a methodology to quantify the friendliness of neural blocks to hardware and the impact of their placement in a macro network on overall network performance via only end-to-end measurements. Based on extensive profiling results, we derive design insights and apply them to hardware-specific search space reduction. We show that searching in the reduced search space generates better accuracy-latency Pareto frontiers than searching in the original search spaces, customizing architecture search according to the hardware. Moreover, insights derived from measurements lead to notably higher ImageNet top-1 scores on all search spaces investigated.
L$^{2}$NAS: Learning to Optimize Neural Architectures via Continuous-Action Reinforcement Learning
Sep 25, 2021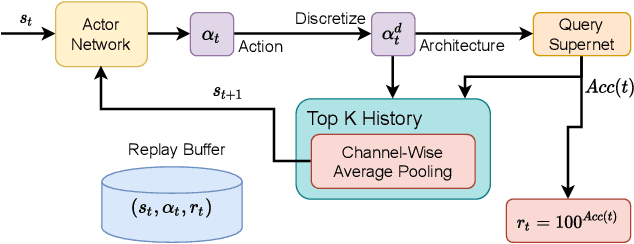
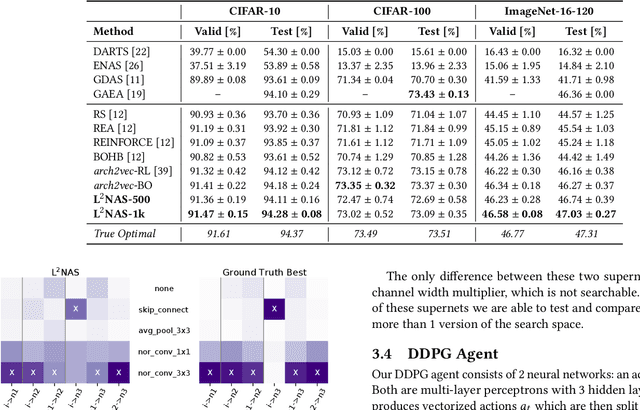
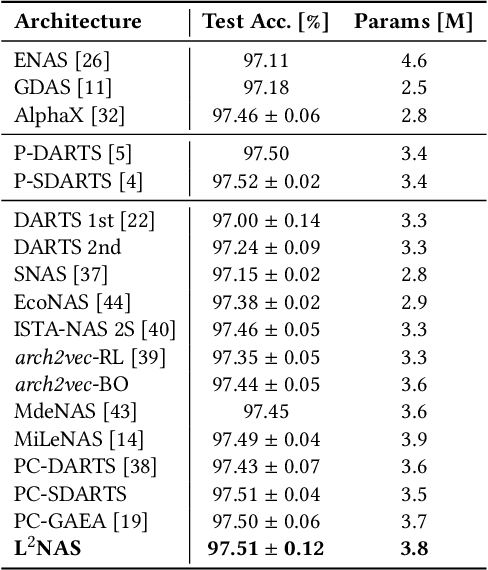
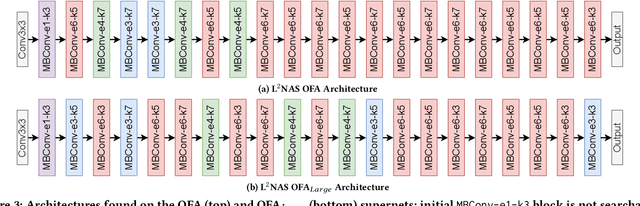
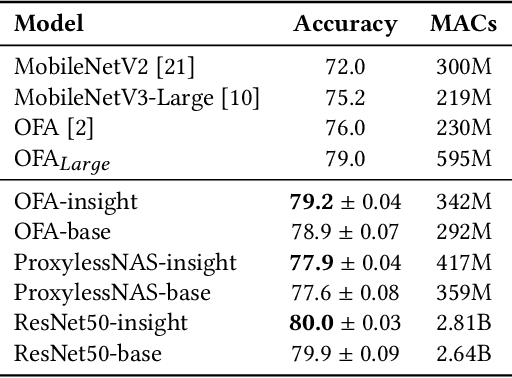
Neural architecture search (NAS) has achieved remarkable results in deep neural network design. Differentiable architecture search converts the search over discrete architectures into a hyperparameter optimization problem which can be solved by gradient descent. However, questions have been raised regarding the effectiveness and generalizability of gradient methods for solving non-convex architecture hyperparameter optimization problems. In this paper, we propose L$^{2}$NAS, which learns to intelligently optimize and update architecture hyperparameters via an actor neural network based on the distribution of high-performing architectures in the search history. We introduce a quantile-driven training procedure which efficiently trains L$^{2}$NAS in an actor-critic framework via continuous-action reinforcement learning. Experiments show that L$^{2}$NAS achieves state-of-the-art results on NAS-Bench-201 benchmark as well as DARTS search space and Once-for-All MobileNetV3 search space. We also show that search policies generated by L$^{2}$NAS are generalizable and transferable across different training datasets with minimal fine-tuning.
Generative Adversarial Neural Architecture Search
May 19, 2021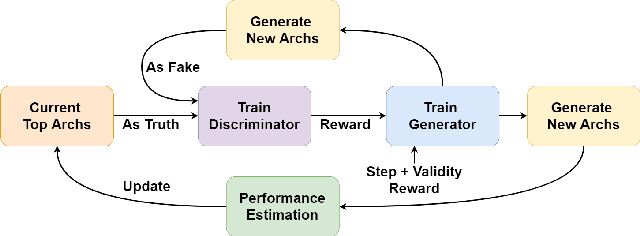
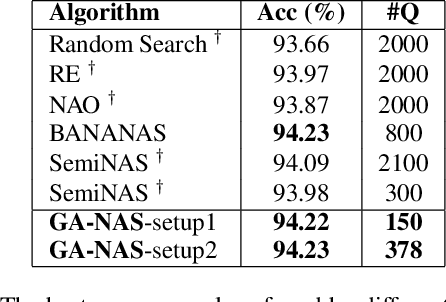
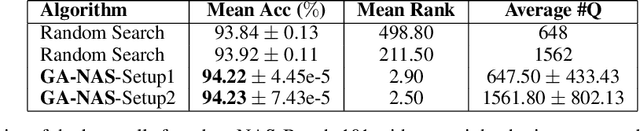
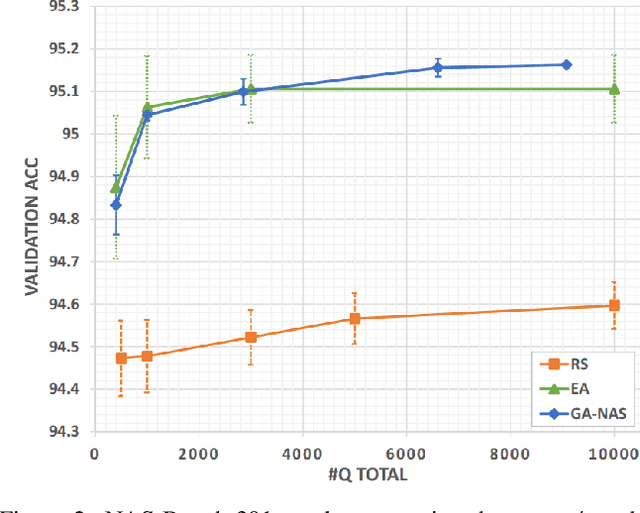
Despite the empirical success of neural architecture search (NAS) in deep learning applications, the optimality, reproducibility and cost of NAS schemes remain hard to assess. In this paper, we propose Generative Adversarial NAS (GA-NAS) with theoretically provable convergence guarantees, promoting stability and reproducibility in neural architecture search. Inspired by importance sampling, GA-NAS iteratively fits a generator to previously discovered top architectures, thus increasingly focusing on important parts of a large search space. Furthermore, we propose an efficient adversarial learning approach, where the generator is trained by reinforcement learning based on rewards provided by a discriminator, thus being able to explore the search space without evaluating a large number of architectures. Extensive experiments show that GA-NAS beats the best published results under several cases on three public NAS benchmarks. In the meantime, GA-NAS can handle ad-hoc search constraints and search spaces. We show that GA-NAS can be used to improve already optimized baselines found by other NAS methods, including EfficientNet and ProxylessNAS, in terms of ImageNet accuracy or the number of parameters, in their original search space.