 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStep-size Optimization for Continual Learning
Jan 30, 2024In continual learning, a learner has to keep learning from the data over its whole life time. A key issue is to decide what knowledge to keep and what knowledge to let go. In a neural network, this can be implemented by using a step-size vector to scale how much gradient samples change network weights. Common algorithms, like RMSProp and Adam, use heuristics, specifically normalization, to adapt this step-size vector. In this paper, we show that those heuristics ignore the effect of their adaptation on the overall objective function, for example by moving the step-size vector away from better step-size vectors. On the other hand, stochastic meta-gradient descent algorithms, like IDBD (Sutton, 1992), explicitly optimize the step-size vector with respect to the overall objective function. On simple problems, we show that IDBD is able to consistently improve step-size vectors, where RMSProp and Adam do not. We explain the differences between the two approaches and their respective limitations. We conclude by suggesting that combining both approaches could be a promising future direction to improve the performance of neural networks in continual learning.
Measuring and Mitigating Interference in Reinforcement Learning
Jul 10, 2023



Catastrophic interference is common in many network-based learning systems, and many proposals exist for mitigating it. Before overcoming interference we must understand it better. In this work, we provide a definition and novel measure of interference for value-based reinforcement learning methods such as Fitted Q-Iteration and DQN. We systematically evaluate our measure of interference, showing that it correlates with instability in control performance, across a variety of network architectures. Our new interference measure allows us to ask novel scientific questions about commonly used deep learning architectures and study learning algorithms which mitigate interference. Lastly, we outline a class of algorithms which we call online-aware that are designed to mitigate interference, and show they do reduce interference according to our measure and that they improve stability and performance in several classic control environments.
Drawing Inductor Layout with a Reinforcement Learning Agent: Method and Application for VCO Inductors
Feb 25, 2022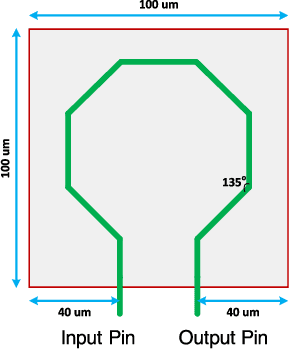
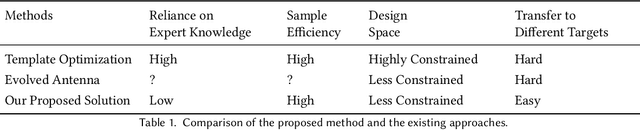
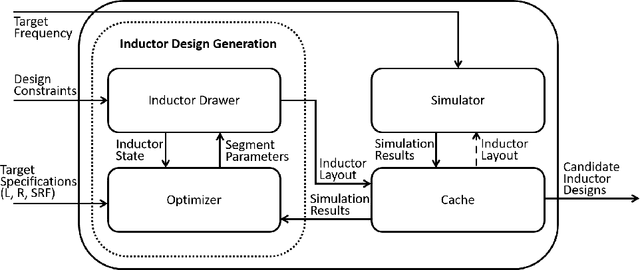
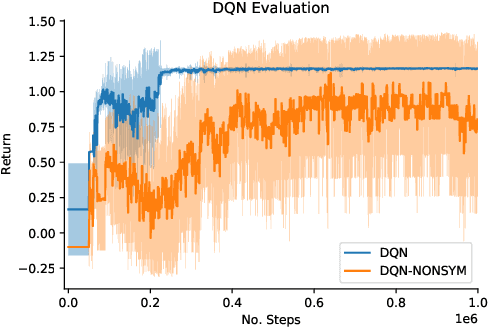
Design of Voltage-Controlled Oscillator (VCO) inductors is a laborious and time-consuming task that is conventionally done manually by human experts. In this paper, we propose a framework for automating the design of VCO inductors, using Reinforcement Learning (RL). We formulate the problem as a sequential procedure, where wire segments are drawn one after another, until a complete inductor is created. We then employ an RL agent to learn to draw inductors that meet certain target specifications. In light of the need to tweak the target specifications throughout the circuit design cycle, we also develop a variant in which the agent can learn to quickly adapt to draw new inductors for moderately different target specifications. Our empirical results show that the proposed framework is successful at automatically generating VCO inductors that meet or exceed the target specification.
Scalable Online Recurrent Learning Using Columnar Neural Networks
Mar 09, 2021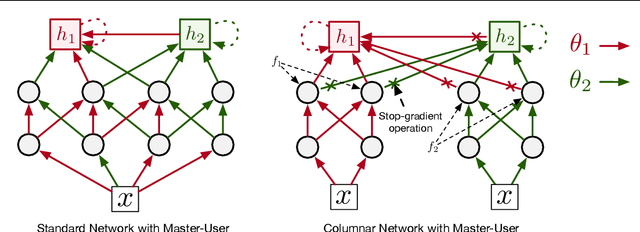
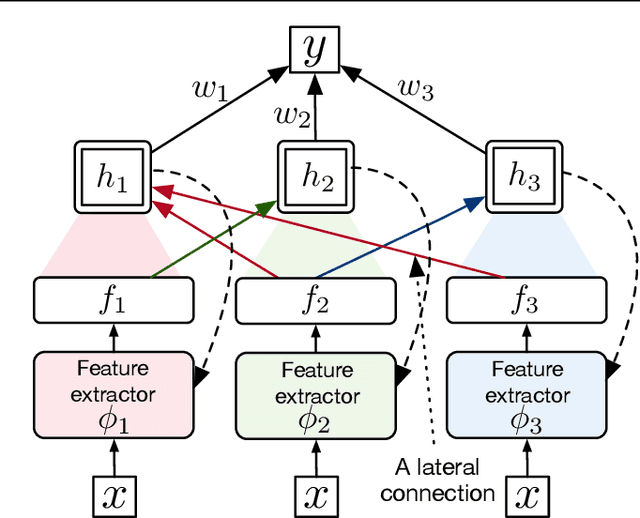
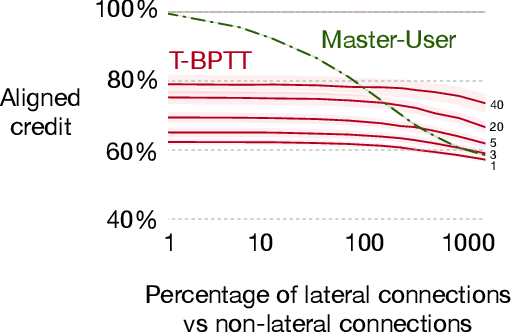
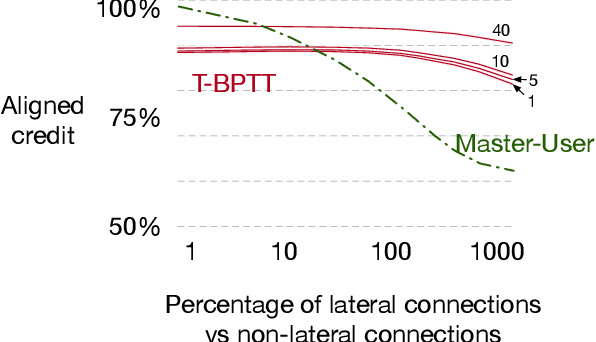
Structural credit assignment for recurrent learning is challenging. An algorithm called RTRL can compute gradients for recurrent networks online but is computationally intractable for large networks. Alternatives, such as BPTT, are not online. In this work, we propose a credit-assignment algorithm -- \algoname{} -- that approximates the gradients for recurrent learning in real-time using $O(n)$ operations and memory per-step. Our method builds on the idea that for modular recurrent networks, composed of columns with scalar states, it is sufficient for a parameter to only track its influence on the state of its column. We empirically show that as long as connections between columns are sparse, our method approximates the true gradient well. In the special case when there are no connections between columns, the $O(n)$ gradient estimate is exact. We demonstrate the utility of the approach for both recurrent state learning and meta-learning by comparing the estimated gradient to the true gradient on a synthetic test-bed.
Learning Causal Models Online
Jun 12, 2020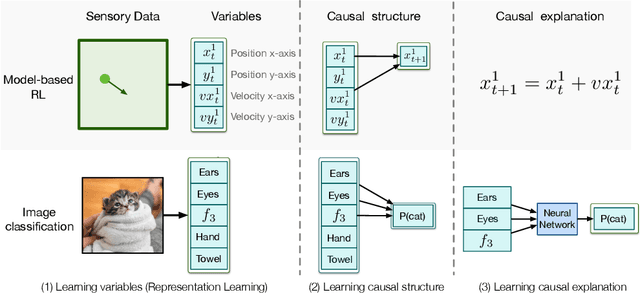
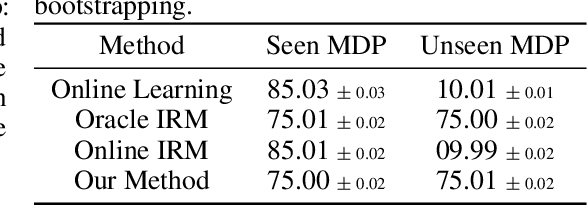
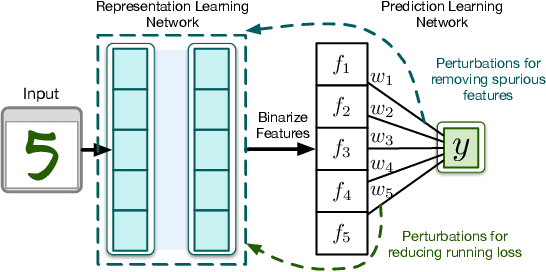
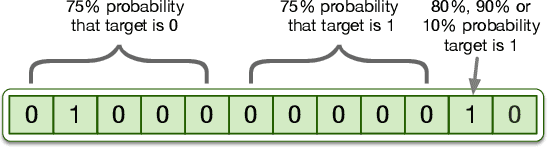
Predictive models -- learned from observational data not covering the complete data distribution -- can rely on spurious correlations in the data for making predictions. These correlations make the models brittle and hinder generalization. One solution for achieving strong generalization is to incorporate causal structures in the models; such structures constrain learning by ignoring correlations that contradict them. However, learning these structures is a hard problem in itself. Moreover, it's not clear how to incorporate the machinery of causality with online continual learning. In this work, we take an indirect approach to discovering causal models. Instead of searching for the true causal model directly, we propose an online algorithm that continually detects and removes spurious features. Our algorithm works on the idea that the correlation of a spurious feature with a target is not constant over-time. As a result, the weight associated with that feature is constantly changing. We show that by continually removing such features, our method converges to solutions that have strong generalization. Moreover, our method combined with random search can also discover non-spurious features from raw sensory data. Finally, our work highlights that the information present in the temporal structure of the problem -- destroyed by shuffling the data -- is essential for detecting spurious features online.
Is Fast Adaptation All You Need?
Oct 03, 2019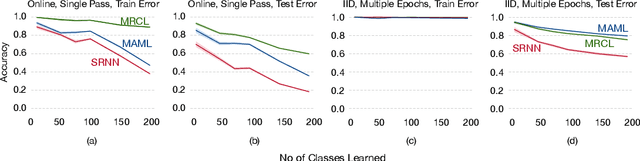

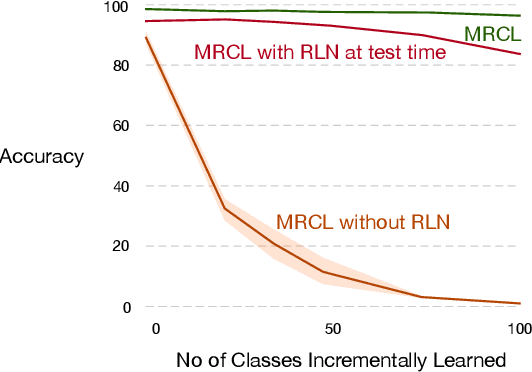
Gradient-based meta-learning has proven to be highly effective at learning model initializations, representations, and update rules that allow fast adaptation from a few samples. The core idea behind these approaches is to use fast adaptation and generalization -- two second-order metrics -- as training signals on a meta-training dataset. However, little attention has been given to other possible second-order metrics. In this paper, we investigate a different training signal -- robustness to catastrophic interference -- and demonstrate that representations learned by directing minimizing interference are more conducive to incremental learning than those learned by just maximizing fast adaptation.
Simultaneous Prediction Intervals for Patient-Specific Survival Curves
Jun 25, 2019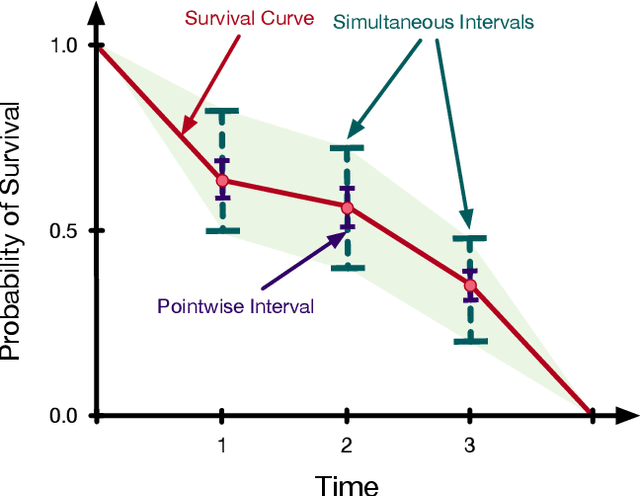
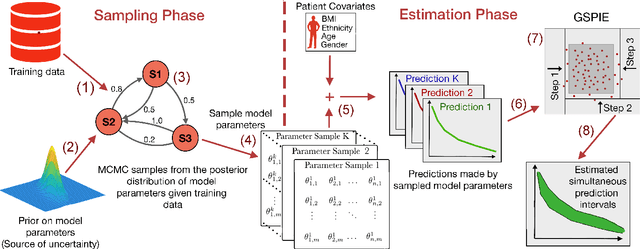
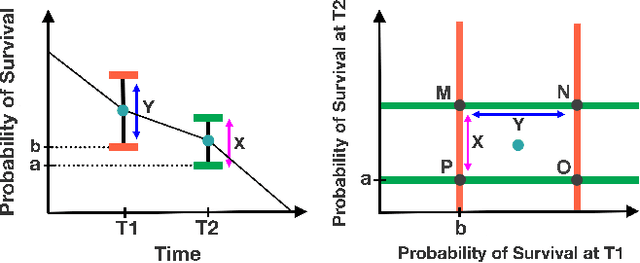
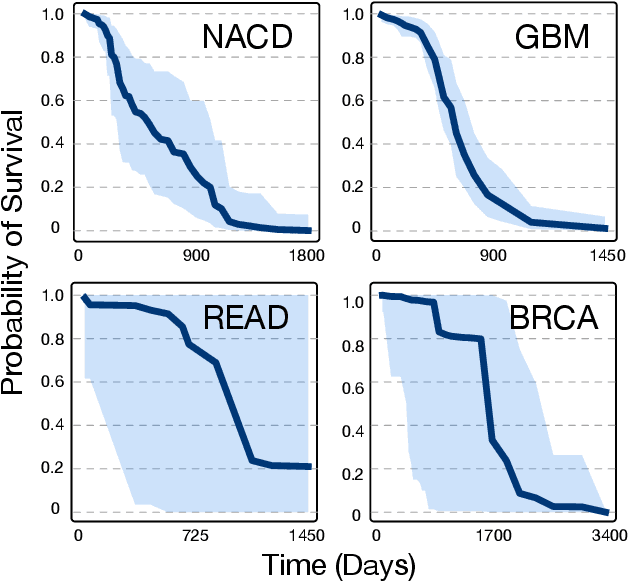
Accurate models of patient survival probabilities provide important information to clinicians prescribing care for life-threatening and terminal ailments. A recently developed class of models - known as individual survival distributions (ISDs) - produces patient-specific survival functions that offer greater descriptive power of patient outcomes than was previously possible. Unfortunately, at the time of writing, ISD models almost universally lack uncertainty quantification. In this paper, we demonstrate that an existing method for estimating simultaneous prediction intervals from samples can easily be adapted for patient-specific survival curve analysis and yields accurate results. Furthermore, we introduce both a modification to the existing method and a novel method for estimating simultaneous prediction intervals and show that they offer competitive performance. It is worth emphasizing that these methods are not limited to survival analysis and can be applied in any context in which sampling the distribution of interest is tractable. Code is available at https://github.com/ssokota/spie .
Meta-Learning Representations for Continual Learning
May 29, 2019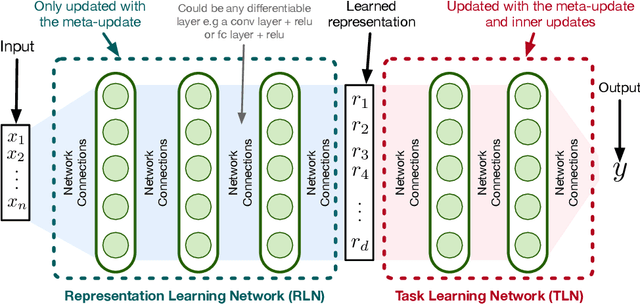
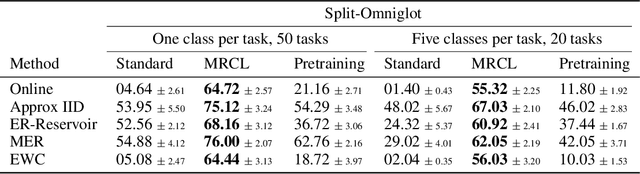
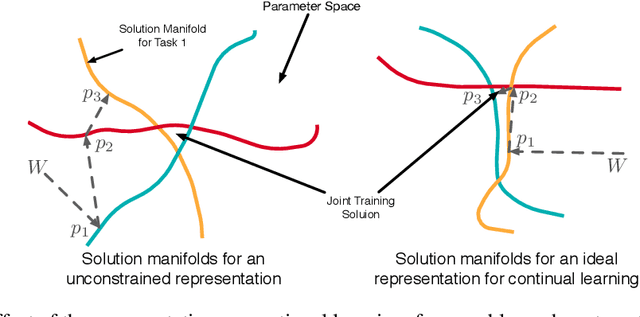

A continual learning agent should be able to build on top of existing knowledge to learn on new data quickly while minimizing forgetting. Current intelligent systems based on neural network function approximators arguably do the opposite---they are highly prone to forgetting and rarely trained to facilitate future learning. One reason for this poor behavior is that they learn from a representation that is not explicitly trained for these two goals. In this paper, we propose MRCL, an objective to explicitly learn representations that accelerate future learning and are robust to forgetting under online updates in continual learning. The idea is to optimize the representation such that online updates minimize error on all samples with little forgetting. We show that it is possible to learn representations that are more effective for online updating and that sparsity naturally emerges in these representations. Moreover, our method is complementary to existing continual learning strategies, like MER, which can learn more effectively from representations learned by our objective. Finally, we demonstrate that a basic online updating strategy with our learned representation is competitive with rehearsal based methods for continual learning. We release an implementation of our method at https://github.com/khurramjaved96/mrcl .
Distillation Techniques for Pseudo-rehearsal Based Incremental Learning
Jul 11, 2018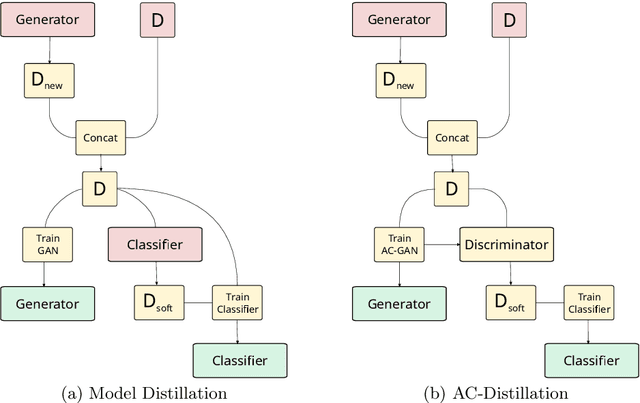
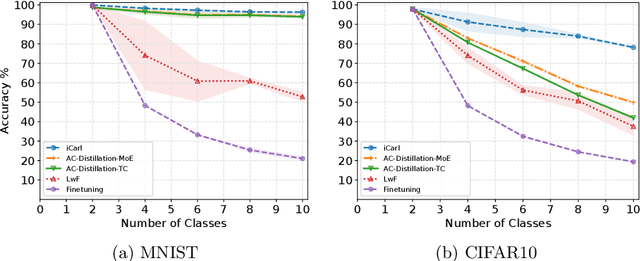
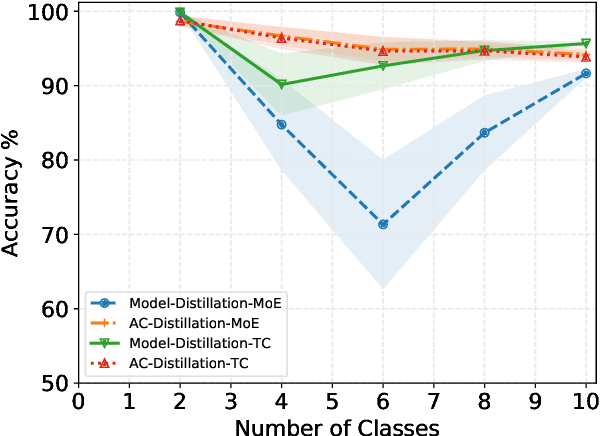
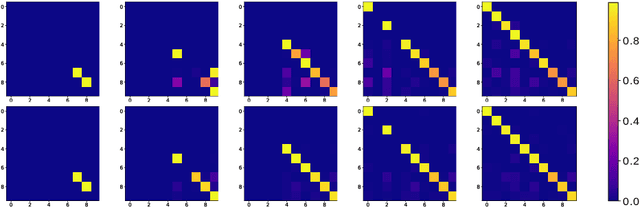
The ability to learn from incrementally arriving data is essential for any life-long learning system. However, standard deep neural networks forget the knowledge about the old tasks, a phenomenon called catastrophic forgetting, when trained on incrementally arriving data. We discuss the biases in current Generative Adversarial Networks (GAN) based approaches that learn the classifier by knowledge distillation from previously trained classifiers. These biases cause the trained classifier to perform poorly. We propose an approach to remove these biases by distilling knowledge from the classifier of AC-GAN. Experiments on MNIST and CIFAR10 show that this method is comparable to current state of the art rehearsal based approaches. The code for this paper is available at https://bit.ly/incremental-learning
Revisiting Distillation and Incremental Classifier Learning
Jul 08, 2018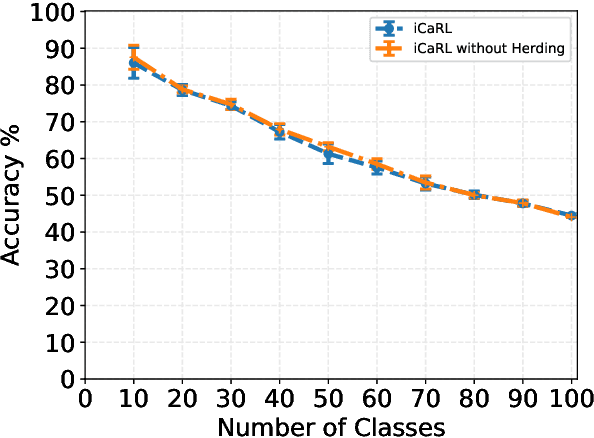

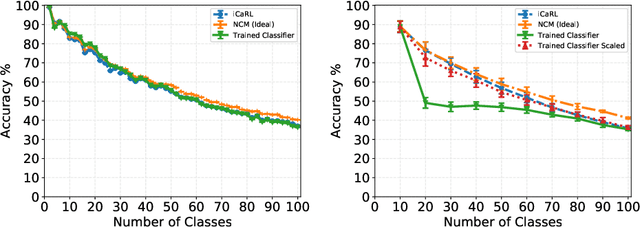
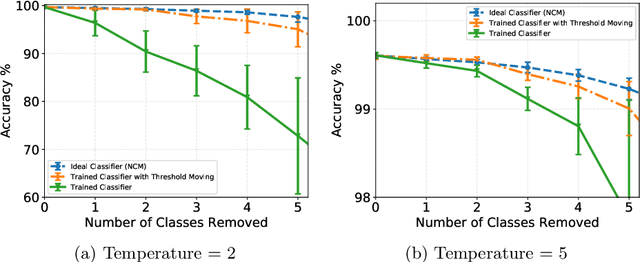
One of the key differences between the learning mechanism of humans and Artificial Neural Networks (ANNs) is the ability of humans to learn one task at a time. ANNs, on the other hand, can only learn multiple tasks simultaneously. Any attempts at learning new tasks incrementally cause them to completely forget about previous tasks. This lack of ability to learn incrementally, called Catastrophic Forgetting, is considered a major hurdle in building a true AI system. In this paper, our goal is to isolate the truly effective existing ideas for incremental learning from those that only work under certain conditions. To this end, we first thoroughly analyze the current state of the art (iCaRL) method for incremental learning and demonstrate that the good performance of the system is not because of the reasons presented in the existing literature. We conclude that the success of iCaRL is primarily due to knowledge distillation and recognize a key limitation of knowledge distillation, i.e, it often leads to bias in classifiers. Finally, we propose a dynamic threshold moving algorithm that is able to successfully remove this bias. We demonstrate the effectiveness of our algorithm on CIFAR100 and MNIST datasets showing near-optimal results. Our implementation is available at https://github.com/Khurramjaved96/incremental-learning.