 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiViNeT: 3D Reconstruction from Disparate Views via Neural Template Regularization
Jun 15, 2023We present a volume rendering-based neural surface reconstruction method that takes as few as three disparate RGB images as input. Our key idea is to regularize the reconstruction, which is severely ill-posed and leaving significant gaps between the sparse views, by learning a set of neural templates that act as surface priors. Our method coined DiViNet, operates in two stages. The first stage learns the templates, in the form of 3D Gaussian functions, across different scenes, without 3D supervision. In the reconstruction stage, our predicted templates serve as anchors to help "stitch" the surfaces over sparse regions. We demonstrate that our approach is not only able to complete the surface geometry but also reconstructs surface details to a reasonable extent from few disparate input views. On the DTU and BlendedMVS datasets, our approach achieves the best reconstruction quality among existing methods in the presence of such sparse views, and performs on par, if not better, with competing methods when dense views are employed as inputs.
RoSI: Recovering 3D Shape Interiors from Few Articulation Images
Apr 13, 2023



The dominant majority of 3D models that appear in gaming, VR/AR, and those we use to train geometric deep learning algorithms are incomplete, since they are modeled as surface meshes and missing their interior structures. We present a learning framework to recover the shape interiors (RoSI) of existing 3D models with only their exteriors from multi-view and multi-articulation images. Given a set of RGB images that capture a target 3D object in different articulated poses, possibly from only few views, our method infers the interior planes that are observable in the input images. Our neural architecture is trained in a category-agnostic manner and it consists of a motion-aware multi-view analysis phase including pose, depth, and motion estimations, followed by interior plane detection in images and 3D space, and finally multi-view plane fusion. In addition, our method also predicts part articulations and is able to realize and even extrapolate the captured motions on the target 3D object. We evaluate our method by quantitative and qualitative comparisons to baselines and alternative solutions, as well as testing on untrained object categories and real image inputs to assess its generalization capabilities.
Coarse-to-Fine Active Segmentation of Interactable Parts in Real Scene Images
Mar 21, 2023



We introduce the first active learning (AL) framework for high-accuracy instance segmentation of dynamic, interactable parts from RGB images of real indoor scenes. As with most human-in-the-loop approaches, the key criterion for success in AL is to minimize human effort while still attaining high performance. To this end, we employ a transformer-based segmentation network that utilizes a masked-attention mechanism. To enhance the network, tailoring to our task, we introduce a coarse-to-fine model which first uses object-aware masked attention and then a pose-aware one, leveraging a correlation between interactable parts and object poses and leading to improved handling of multiple articulated objects in an image. Our coarse-to-fine active segmentation module learns both 2D instance and 3D pose information using the transformer, which supervises the active segmentation and effectively reduces human effort. Our method achieves close to fully accurate (96% and higher) segmentation results on real images, with 77% time saving over manual effort, where the training data consists of only 16.6% annotated real photographs. At last, we contribute a dataset of 2,550 real photographs with annotated interactable parts, demonstrating its superior quality and diversity over the current best alternative.
LayoutGMN: Neural Graph Matching for Structural Layout Similarity
Dec 11, 2020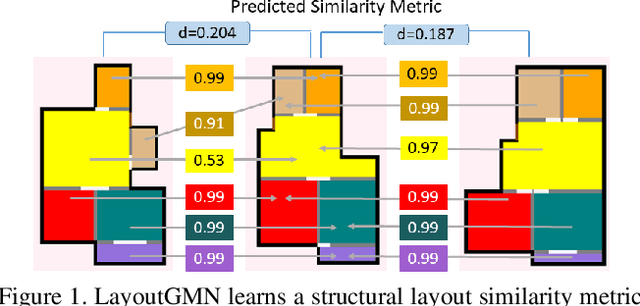
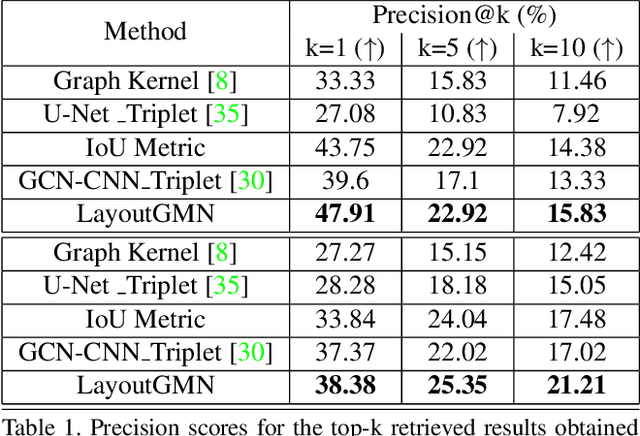
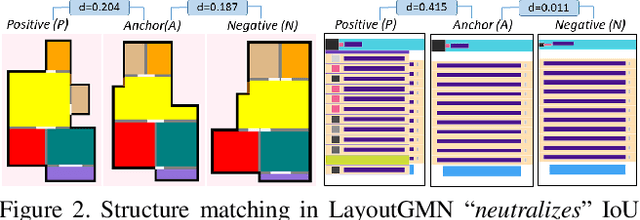

We present a deep neural network to predict structural similarity between 2D layouts by leveraging Graph Matching Networks (GMN). Our network, coined LayoutGMN, learns the layout metric via neural graph matching, using an attention-based GMN designed under a triplet network setting. To train our network, we utilize weak labels obtained by pixel-wise Intersection-over-Union (IoUs) to define the triplet loss. Importantly, LayoutGMN is built with a structural bias which can effectively compensate for the lack of structure awareness in IoUs. We demonstrate this on two prominent forms of layouts, viz., floorplans and UI designs, via retrieval experiments on large-scale datasets. In particular, retrieval results by our network better match human judgement of structural layout similarity compared to both IoUs and other baselines including a state-of-the-art method based on graph neural networks and image convolution. In addition, LayoutGMN is the first deep model to offer both metric learning of structural layout similarity and structural matching between layout elements.
DR-KFD: A Differentiable Visual Metric for 3D Shape Reconstruction
Nov 28, 2019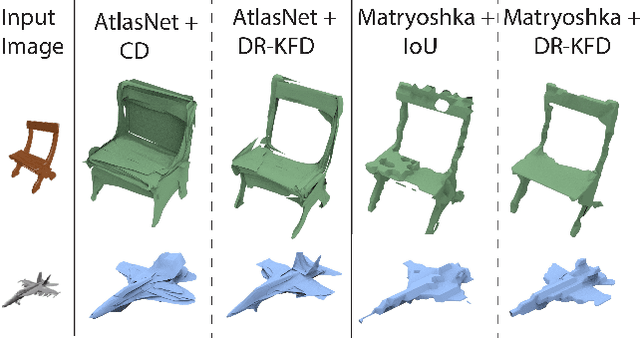
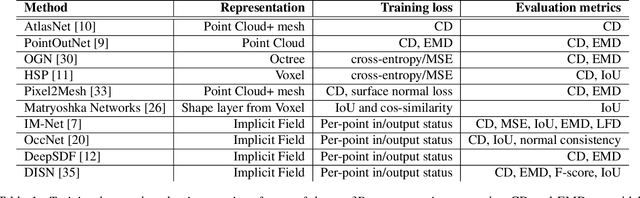
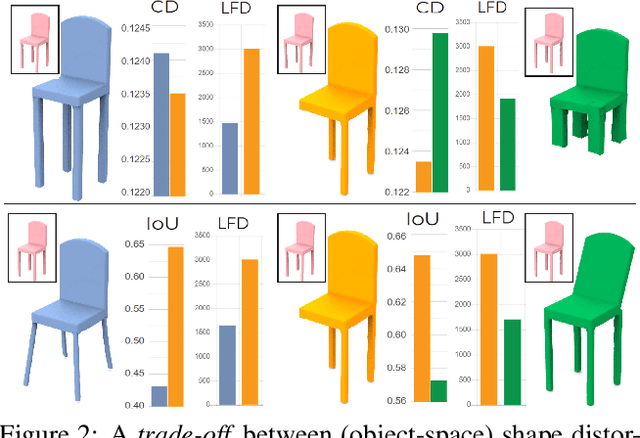
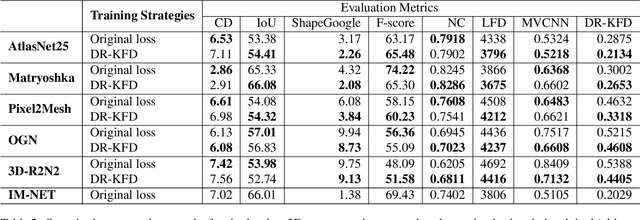
We advocate the use of differential visual shape metrics to train deep neural networks for 3D reconstruction. We introduce such a metric which compares two 3D shapes by measuring visual, image-space differences between multiview images differentiably rendered from the shapes. Furthermore, we develop a differentiable image-space distance based on mean-squared errors defined over Hard- Net features computed from probabilistic keypoint maps of the compared images. Our differential visual shape metric can be easily plugged into various reconstruction networks, replacing the object-space distortion measures, such as Chamfer or Earth Mover distances, so as to optimize the network weights to produce reconstruction results with better structural fidelity and visual quality. We demonstrate this both objectively, using well-known visual shape metrics for retrieval and classification tasks that are independent from our new metric, and subjectively through a perceptual study.
READ: Recursive Autoencoders for Document Layout Generation
Oct 10, 2019

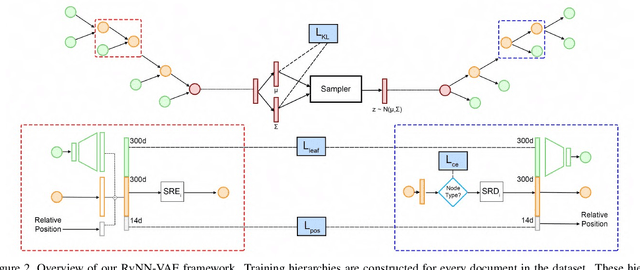
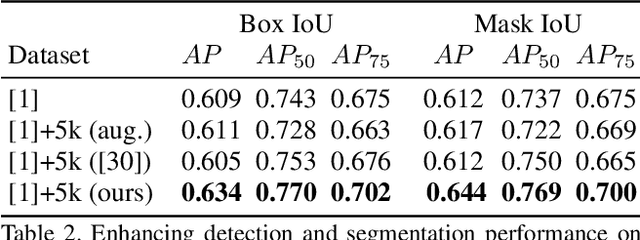
Layout is a fundamental component of any graphic design. Creating large varieties of plausible document layouts can be a tedious task, requiring numerous constraints to be satisfied, including local ones relating different semantic elements and global constraints on the general appearance and spacing. In this paper, we present a novel framework, coined READ, for REcursive Autoencoders for Document layout generation, to generate plausible 2D layouts of documents in large quantities and varieties. First, we devise an exploratory recursive method to extract a structural decomposition of a single document. Leveraging a dataset of documents annotated with labeled bounding boxes, our recursive neural network learns to map the structural representation, given in the form of a simple hierarchy, to a compact code, the space of which is approximated by a Gaussian distribution. Novel hierarchies can be sampled from this space, obtaining new document layouts. Moreover, we introduce a combinatorial metric to measure structural similarity among document layouts. We deploy it to show that our method is able to generate highly variable and realistic layouts. We further demonstrate the utility of our generated layouts in the context of standard detection tasks on documents, showing that detection performance improves when the training data is augmented with generated documents whose layouts are produced by READ.
Automatic Content-aware Non-Photorealistic Rendering of Images
Apr 19, 2016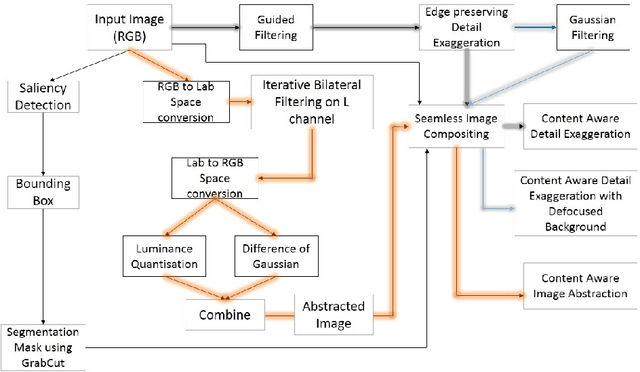


Non-photorealistic rendering techniques work on image features and often manipulate a set of characteristics such as edges and texture to achieve a desired depiction of the scene. Most computational photography methods decompose an image using edge preserving filters and work on the resulting base and detail layers independently to achieve desired visual effects. We propose a new approach for content-aware non-photorealistic rendering of images where we manipulate the visually salient and the non-salient regions separately. We propose a novel content-aware framework in order to render an image for applications such as detail exaggeration, artificial blurring and image abstraction. The processed regions of the image are blended seamlessly for all these applications. We demonstrate that content awareness of the proposed method leads to automatic generation of non-photorealistic rendering of the same image for the different applications mentioned above.