 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Transformers for Unsupervised 3D Shape Abstraction
Oct 31, 2025We introduce HiT, a novel hierarchical neural field representation for 3D shapes that learns general hierarchies in a coarse-to-fine manner across different shape categories in an unsupervised setting. Our key contribution is a hierarchical transformer (HiT), where each level learns parent-child relationships of the tree hierarchy using a compressed codebook. This codebook enables the network to automatically identify common substructures across potentially diverse shape categories. Unlike previous works that constrain the task to a fixed hierarchical structure (e.g., binary), we impose no such restriction, except for limiting the total number of nodes at each tree level. This flexibility allows our method to infer the hierarchical structure directly from data, over multiple shape categories, and representing more general and complex hierarchies than prior approaches. When trained at scale with a reconstruction loss, our model captures meaningful containment relationships between parent and child nodes. We demonstrate its effectiveness through an unsupervised shape segmentation task over all 55 ShapeNet categories, where our method successfully segments shapes into multiple levels of granularity.
Advances in 4D Representation: Geometry, Motion, and Interaction
Oct 22, 2025We present a survey on 4D generation and reconstruction, a fast-evolving subfield of computer graphics whose developments have been propelled by recent advances in neural fields, geometric and motion deep learning, as well 3D generative artificial intelligence (GenAI). While our survey is not the first of its kind, we build our coverage of the domain from a unique and distinctive perspective of 4D representations\/}, to model 3D geometry evolving over time while exhibiting motion and interaction. Specifically, instead of offering an exhaustive enumeration of many works, we take a more selective approach by focusing on representative works to highlight both the desirable properties and ensuing challenges of each representation under different computation, application, and data scenarios. The main take-away message we aim to convey to the readers is on how to select and then customize the appropriate 4D representations for their tasks. Organizationally, we separate the 4D representations based on three key pillars: geometry, motion, and interaction. Our discourse will not only encompass the most popular representations of today, such as neural radiance fields (NeRFs) and 3D Gaussian Splatting (3DGS), but also bring attention to relatively under-explored representations in the 4D context, such as structured models and long-range motions. Throughout our survey, we will reprise the role of large language models (LLMs) and video foundational models (VFMs) in a variety of 4D applications, while steering our discussion towards their current limitations and how they can be addressed. We also provide a dedicated coverage on what 4D datasets are currently available, as well as what is lacking, in driving the subfield forward. Project page:https://mingrui-zhao.github.io/4DRep-GMI/
Articulate That Object Part (ATOP): 3D Part Articulation from Text and Motion Personalization
Feb 11, 2025



We present ATOP (Articulate That Object Part), a novel method based on motion personalization to articulate a 3D object with respect to a part and its motion as prescribed in a text prompt. Specifically, the text input allows us to tap into the power of modern-day video diffusion to generate plausible motion samples for the right object category and part. In turn, the input 3D object provides image prompting to personalize the generated video to that very object we wish to articulate. Our method starts with a few-shot finetuning for category-specific motion generation, a key first step to compensate for the lack of articulation awareness by current video diffusion models. For this, we finetune a pre-trained multi-view image generation model for controllable multi-view video generation, using a small collection of video samples obtained for the target object category. This is followed by motion video personalization that is realized by multi-view rendered images of the target 3D object. At last, we transfer the personalized video motion to the target 3D object via differentiable rendering to optimize part motion parameters by a score distillation sampling loss. We show that our method is capable of generating realistic motion videos and predict 3D motion parameters in a more accurate and generalizable way, compared to prior works.
DiViNeT: 3D Reconstruction from Disparate Views via Neural Template Regularization
Jun 15, 2023We present a volume rendering-based neural surface reconstruction method that takes as few as three disparate RGB images as input. Our key idea is to regularize the reconstruction, which is severely ill-posed and leaving significant gaps between the sparse views, by learning a set of neural templates that act as surface priors. Our method coined DiViNet, operates in two stages. The first stage learns the templates, in the form of 3D Gaussian functions, across different scenes, without 3D supervision. In the reconstruction stage, our predicted templates serve as anchors to help "stitch" the surfaces over sparse regions. We demonstrate that our approach is not only able to complete the surface geometry but also reconstructs surface details to a reasonable extent from few disparate input views. On the DTU and BlendedMVS datasets, our approach achieves the best reconstruction quality among existing methods in the presence of such sparse views, and performs on par, if not better, with competing methods when dense views are employed as inputs.
FCHD: A fast and accurate head detector
Sep 26, 2018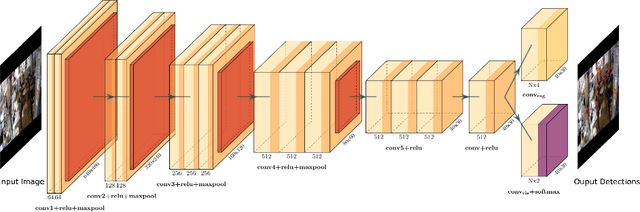
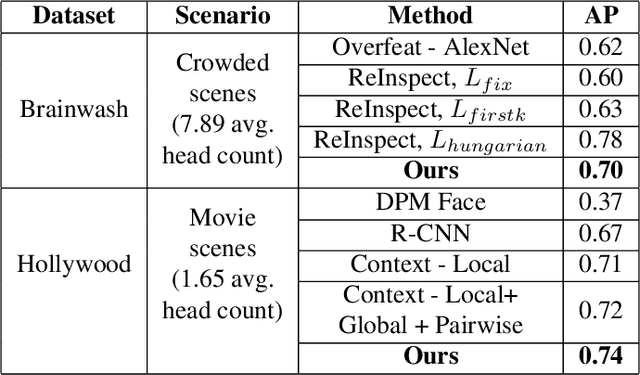
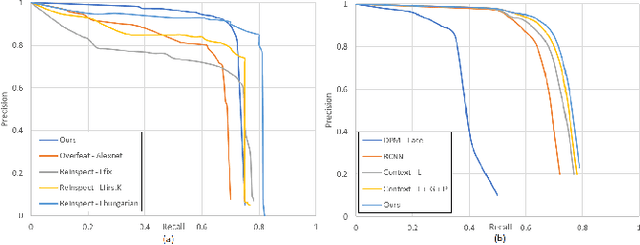

In this paper, we propose FCHD-Fully Convolutional Head Detector, which is an end-to-end trainable head detection model, which runs at 5 fps and with 0.70 average precision (AP), on a very modest GPU. Recent head detection techniques have avoided using anchors as a starting point for detection especially in the cases where the detection has to happen in the wild. The reason is poor performance of anchor-based techniques under scenarios where the object size is small. We argue that a good AP can be obtained with carefully designed anchors, where the anchor design choices are made based on the receptive field size of the hidden layers. Our contribution is two folds. 1) A simple fully convolutional anchor based model which is end-to-end trainable and has a very low inference time. 2) Carefully chosen anchor sizes which play a key role in getting good average precision. Our model achieves comparable results than many other baselines on challenging head detection dataset like BRAINWASH. Along with accuracy, our model has least runtime among all the baselines along with modest hardware requirements which makes it suitable for edge deployments in surveillance applications. The code is made open-source at https://github.com/aditya-vora/FCHD-Fully-Convolutional-Head-Detector.
A Classification approach towards Unsupervised Learning of Visual Representations
Jun 01, 2018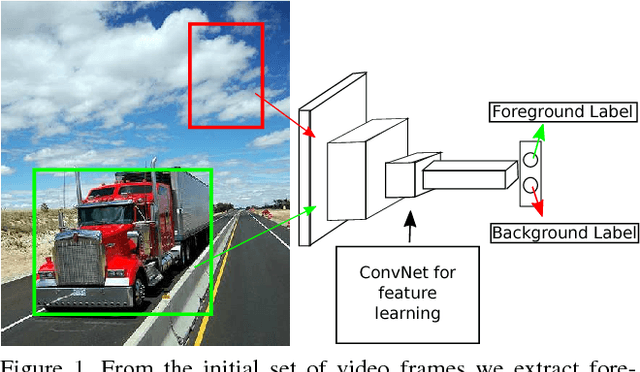
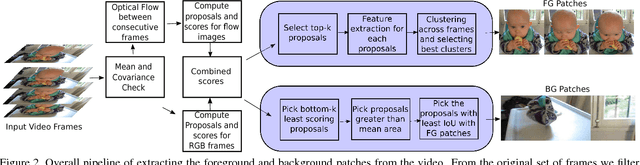
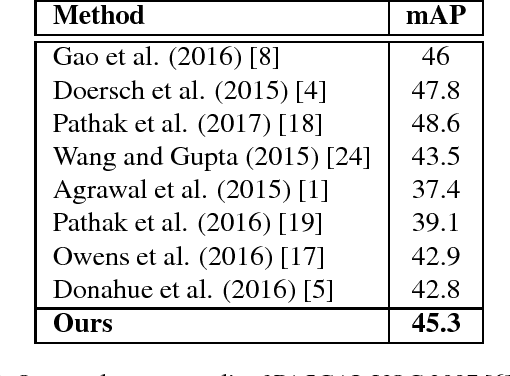
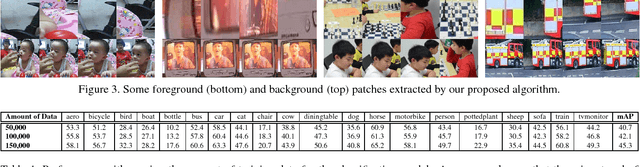
In this paper, we present a technique for unsupervised learning of visual representations. Specifically, we train a model for foreground and background classification task, in the process of which it learns visual representations. Foreground and background patches for training come af- ter mining for such patches from hundreds and thousands of unlabelled videos available on the web which we ex- tract using a proposed patch extraction algorithm. With- out using any supervision, with just using 150, 000 unla- belled videos and the PASCAL VOC 2007 dataset, we train a object recognition model that achieves 45.3 mAP which is close to the best performing unsupervised feature learn- ing technique whereas better than many other proposed al- gorithms. The code for patch extraction is implemented in Matlab and available open source at the following link .
Iterative Spectral Clustering for Unsupervised Object Localization
Jun 29, 2017



This paper addresses the problem of unsupervised object localization in an image. Unlike previous supervised and weakly supervised algorithms that require bounding box or image level annotations for training classifiers in order to learn features representing the object, we propose a simple yet effective technique for localization using iterative spectral clustering. This iterative spectral clustering approach along with appropriate cluster selection strategy in each iteration naturally helps in searching of object region in the image. In order to estimate the final localization window, we group the proposals obtained from the iterative spectral clustering step based on the perceptual similarity, and average the coordinates of the proposals from the top scoring groups. We benchmark our algorithm on challenging datasets like Object Discovery and PASCAL VOC 2007, achieving an average CorLoc percentage of 51% and 35% respectively which is comparable to various other weakly supervised algorithms despite being completely unsupervised.
Flow-free Video Object Segmentation
Jun 29, 2017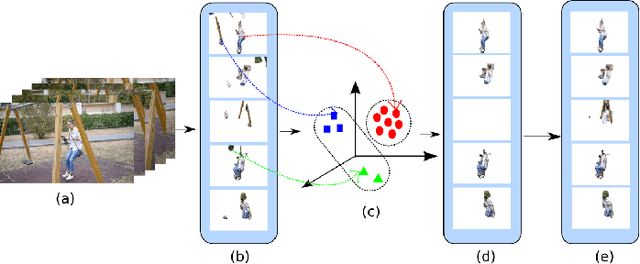


Segmenting foreground object from a video is a challenging task because of the large deformations of the objects, occlusions, and background clutter. In this paper, we propose a frame-by-frame but computationally efficient approach for video object segmentation by clustering visually similar generic object segments throughout the video. Our algorithm segments various object instances appearing in the video and then perform clustering in order to group visually similar segments into one cluster. Since the object that needs to be segmented appears in most part of the video, we can retrieve the foreground segments from the cluster having maximum number of segments, thus filtering out noisy segments that do not represent any object. We then apply a track and fill approach in order to localize the objects in the frames where the object segmentation framework fails to segment any object. Our algorithm performs comparably to the recent automatic methods for video object segmentation when benchmarked on DAVIS dataset while being computationally much faster.