 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGroup-Aware Reinforcement Learning for Output Diversity in Large Language Models
Nov 16, 2025Large Language Models (LLMs) often suffer from mode collapse, repeatedly generating the same few completions even when many valid answers exist, limiting their diversity across a wide range of tasks. We introduce Group-Aware Policy Optimization (GAPO), a simple extension of the recent and popular Group Relative Policy Optimization (GRPO) that computes rewards over the group as a whole. GAPO enables learning from the group-level properties such as diversity and coverage. We demonstrate GAPO using a frequency-aware reward function that encourages uniform sampling over valid LLM completions, and show that GAPO-trained models produce valid and more diverse model responses. Beyond this setup, GAPO generalizes to open-ended prompts and improves response diversity without compromising accuracy on standard LLM benchmarks (GSM8K, MATH, HumanEval, MMLU-Pro). Our code will be made publicly available.
LV-MAE: Learning Long Video Representations through Masked-Embedding Autoencoders
Apr 04, 2025In this work, we introduce long-video masked-embedding autoencoders (LV-MAE), a self-supervised learning framework for long video representation. Our approach treats short- and long-span dependencies as two separate tasks. Such decoupling allows for a more intuitive video processing where short-span spatiotemporal primitives are first encoded and are then used to capture long-range dependencies across consecutive video segments. To achieve this, we leverage advanced off-the-shelf multimodal encoders to extract representations from short segments within the long video, followed by pre-training a masked-embedding autoencoder capturing high-level interactions across segments. LV-MAE is highly efficient to train and enables the processing of much longer videos by alleviating the constraint on the number of input frames. Furthermore, unlike existing methods that typically pre-train on short-video datasets, our approach offers self-supervised pre-training using long video samples (e.g., 20+ minutes video clips) at scale. Using LV-MAE representations, we achieve state-of-the-art results on three long-video benchmarks -- LVU, COIN, and Breakfast -- employing only a simple classification head for either attentive or linear probing. Finally, to assess LV-MAE pre-training and visualize its reconstruction quality, we leverage the video-language aligned space of short video representations to monitor LV-MAE through video-text retrieval.
GLASS: Global to Local Attention for Scene-Text Spotting
Aug 05, 2022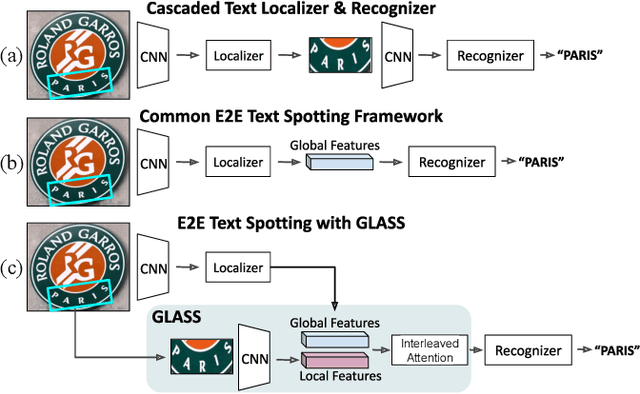
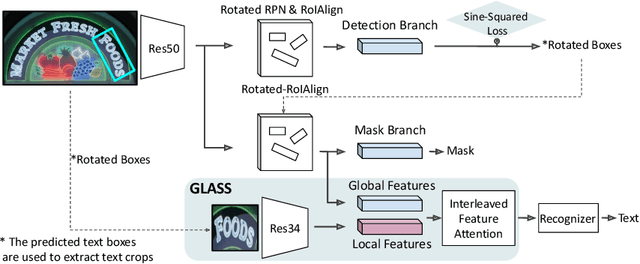
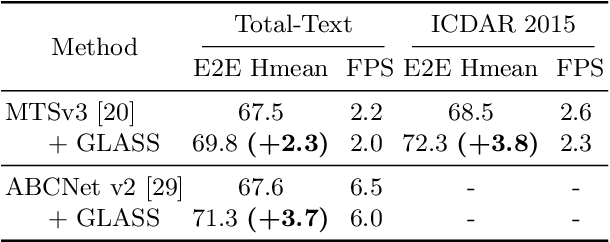
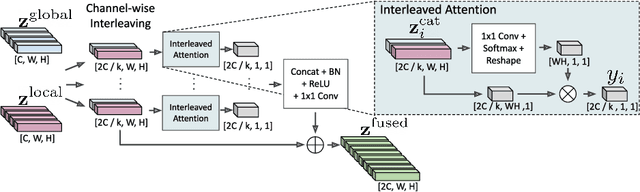
In recent years, the dominant paradigm for text spotting is to combine the tasks of text detection and recognition into a single end-to-end framework. Under this paradigm, both tasks are accomplished by operating over a shared global feature map extracted from the input image. Among the main challenges that end-to-end approaches face is the performance degradation when recognizing text across scale variations (smaller or larger text), and arbitrary word rotation angles. In this work, we address these challenges by proposing a novel global-to-local attention mechanism for text spotting, termed GLASS, that fuses together global and local features. The global features are extracted from the shared backbone, preserving contextual information from the entire image, while the local features are computed individually on resized, high-resolution rotated word crops. The information extracted from the local crops alleviates much of the inherent difficulties with scale and word rotation. We show a performance analysis across scales and angles, highlighting improvement over scale and angle extremities. In addition, we introduce an orientation-aware loss term supervising the detection task, and show its contribution to both detection and recognition performance across all angles. Finally, we show that GLASS is general by incorporating it into other leading text spotting architectures, improving their text spotting performance. Our method achieves state-of-the-art results on multiple benchmarks, including the newly released TextOCR.
Learning Multimodal Affinities for Textual Editing in Images
Mar 18, 2021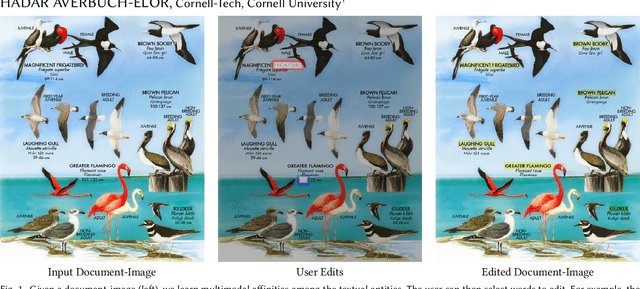
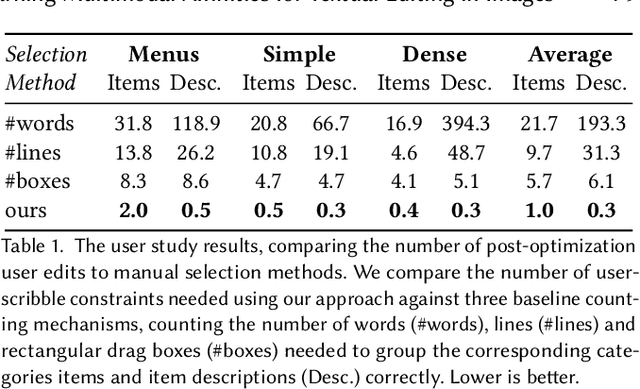
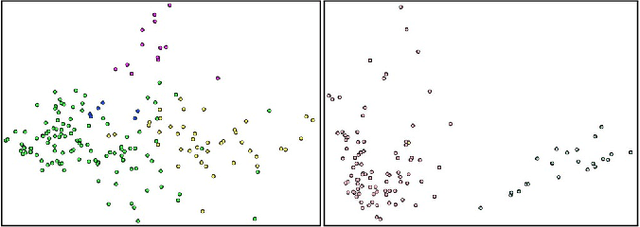
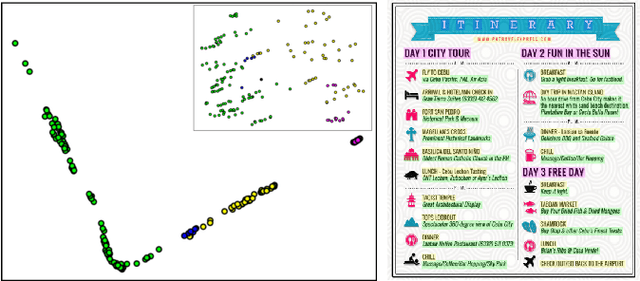
Nowadays, as cameras are rapidly adopted in our daily routine, images of documents are becoming both abundant and prevalent. Unlike natural images that capture physical objects, document-images contain a significant amount of text with critical semantics and complicated layouts. In this work, we devise a generic unsupervised technique to learn multimodal affinities between textual entities in a document-image, considering their visual style, the content of their underlying text and their geometric context within the image. We then use these learned affinities to automatically cluster the textual entities in the image into different semantic groups. The core of our approach is a deep optimization scheme dedicated for an image provided by the user that detects and leverages reliable pairwise connections in the multimodal representation of the textual elements in order to properly learn the affinities. We show that our technique can operate on highly varying images spanning a wide range of documents and demonstrate its applicability for various editing operations manipulating the content, appearance and geometry of the image.
On Calibration of Scene-Text Recognition Models
Dec 23, 2020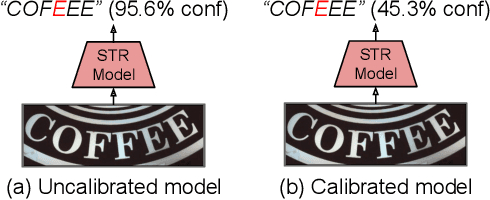
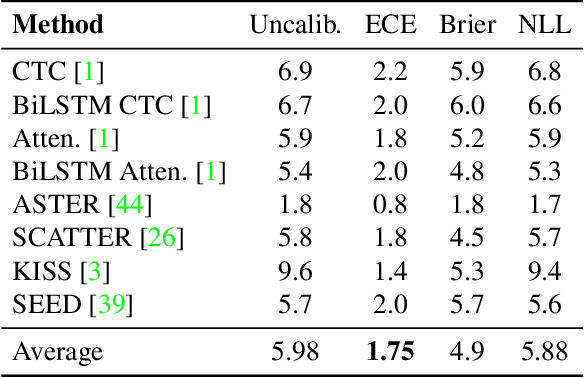
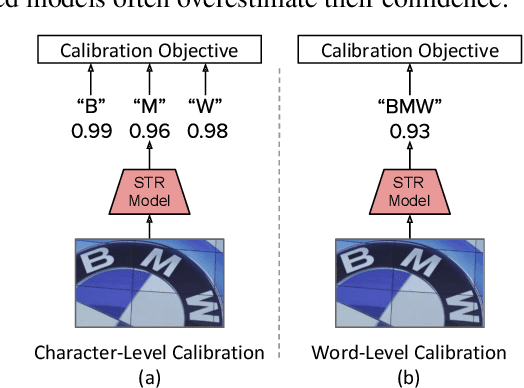
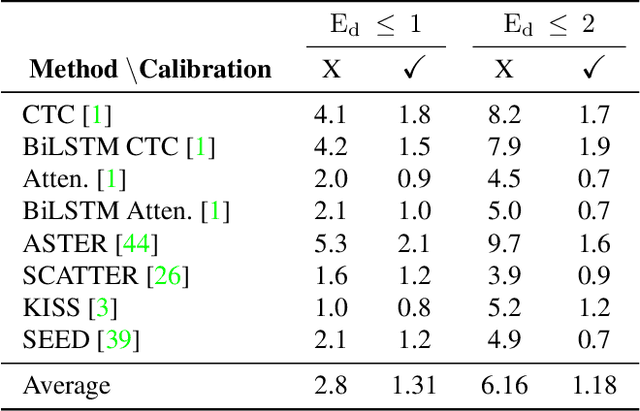
In this work, we study the problem of word-level confidence calibration for scene-text recognition (STR). Although the topic of confidence calibration has been an active research area for the last several decades, the case of structured and sequence prediction calibration has been scarcely explored. We analyze several recent STR methods and show that they are consistently overconfident. We then focus on the calibration of STR models on the word rather than the character level. In particular, we demonstrate that for attention based decoders, calibration of individual character predictions increases word-level calibration error compared to an uncalibrated model. In addition, we apply existing calibration methodologies as well as new sequence-based extensions to numerous STR models, demonstrating reduced calibration error by up to a factor of nearly 7. Finally, we show consistently improved accuracy results by applying our proposed sequence calibration method as a preprocessing step to beam-search.
Sequence-to-Sequence Contrastive Learning for Text Recognition
Dec 20, 2020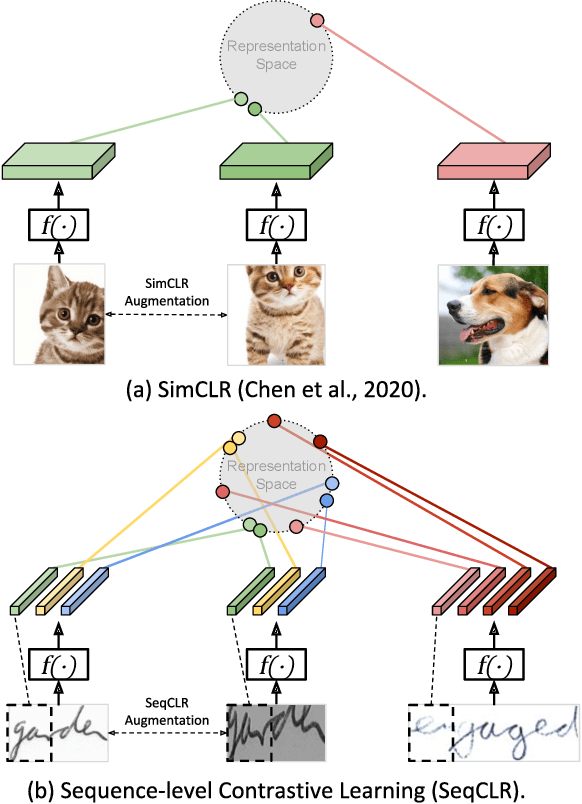
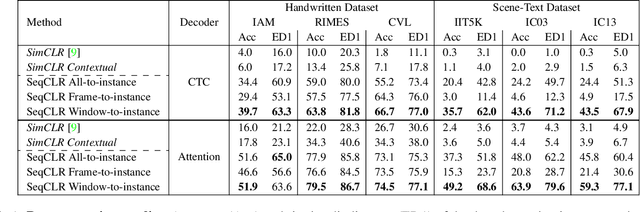
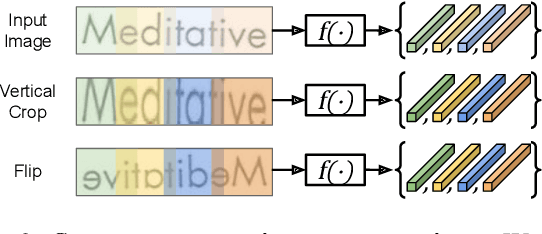
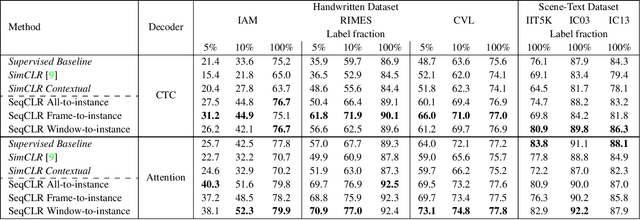
We propose a framework for sequence-to-sequence contrastive learning (SeqCLR) of visual representations, which we apply to text recognition. To account for the sequence-to-sequence structure, each feature map is divided into different instances over which the contrastive loss is computed. This operation enables us to contrast in a sub-word level, where from each image we extract several positive pairs and multiple negative examples. To yield effective visual representations for text recognition, we further suggest novel augmentation heuristics, different encoder architectures and custom projection heads. Experiments on handwritten text and on scene text show that when a text decoder is trained on the learned representations, our method outperforms non-sequential contrastive methods. In addition, when the amount of supervision is reduced, SeqCLR significantly improves performance compared with supervised training, and when fine-tuned with 100% of the labels, our method achieves state-of-the-art results on standard handwritten text recognition benchmarks.
SCATTER: Selective Context Attentional Scene Text Recognizer
Mar 25, 2020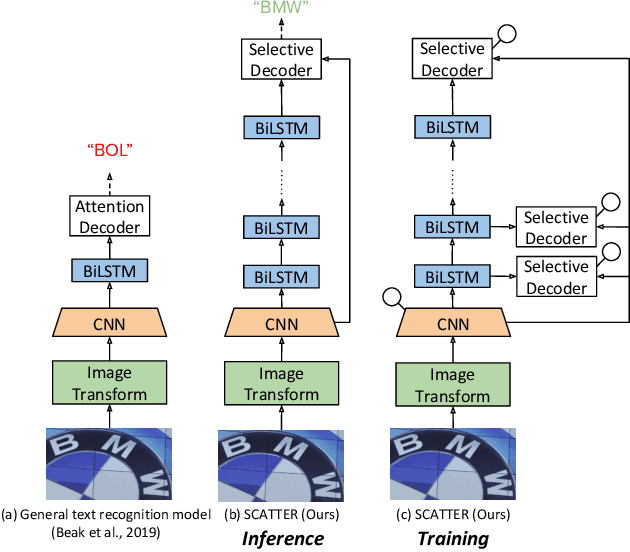
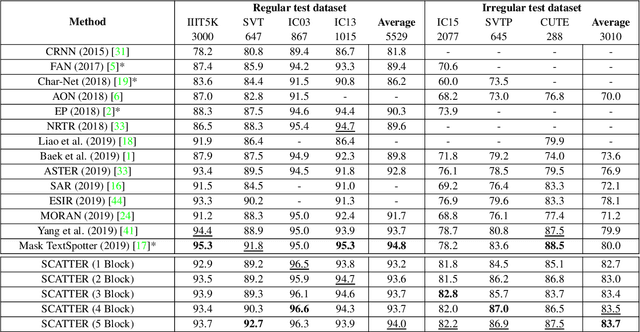
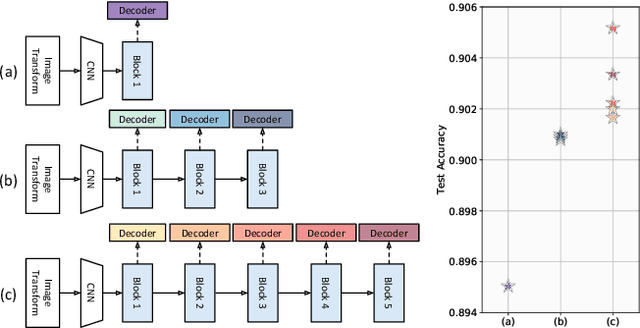
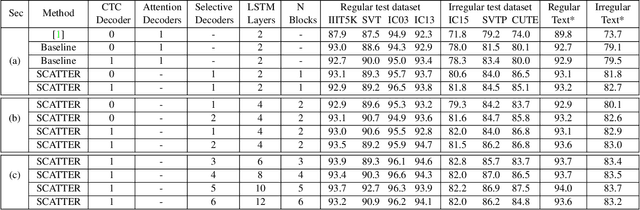
Scene Text Recognition (STR), the task of recognizing text against complex image backgrounds, is an active area of research. Current state-of-the-art (SOTA) methods still struggle to recognize text written in arbitrary shapes. In this paper, we introduce a novel architecture for STR, named Selective Context ATtentional Text Recognizer (SCATTER). SCATTER utilizes a stacked block architecture with intermediate supervision during training, that paves the way to successfully train a deep BiLSTM encoder, thus improving the encoding of contextual dependencies. Decoding is done using a two-step 1D attention mechanism. The first attention step re-weights visual features from a CNN backbone together with contextual features computed by a BiLSTM layer. The second attention step, similar to previous papers, treats the features as a sequence and attends to the intra-sequence relationships. Experiments show that the proposed approach surpasses SOTA performance on irregular text recognition benchmarks by 3.7\% on average.
Averaged-DQN: Variance Reduction and Stabilization for Deep Reinforcement Learning
Mar 10, 2017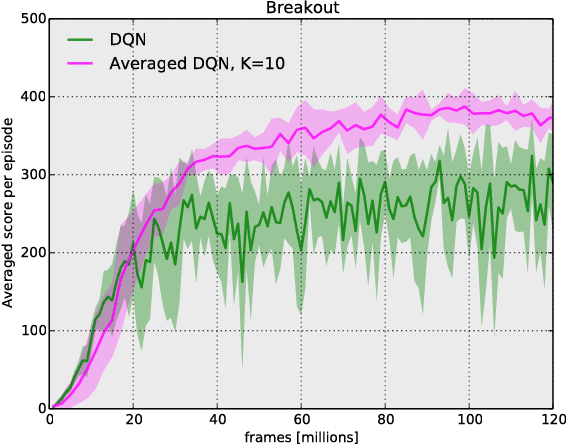
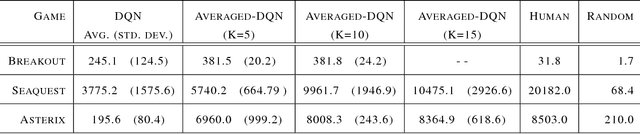
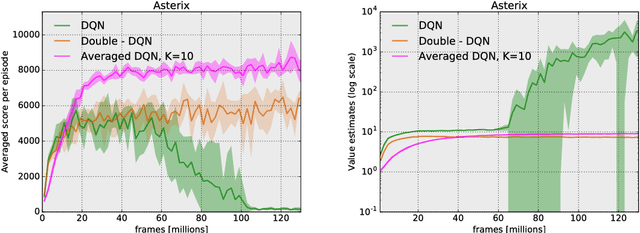

Instability and variability of Deep Reinforcement Learning (DRL) algorithms tend to adversely affect their performance. Averaged-DQN is a simple extension to the DQN algorithm, based on averaging previously learned Q-values estimates, which leads to a more stable training procedure and improved performance by reducing approximation error variance in the target values. To understand the effect of the algorithm, we examine the source of value function estimation errors and provide an analytical comparison within a simplified model. We further present experiments on the Arcade Learning Environment benchmark that demonstrate significantly improved stability and performance due to the proposed extension.
Model-based Adversarial Imitation Learning
Dec 07, 2016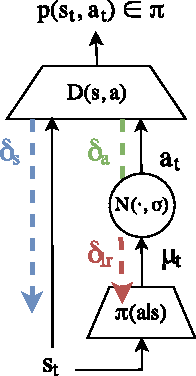
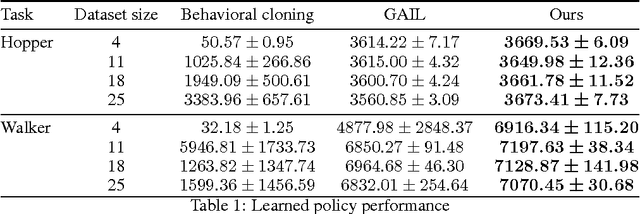
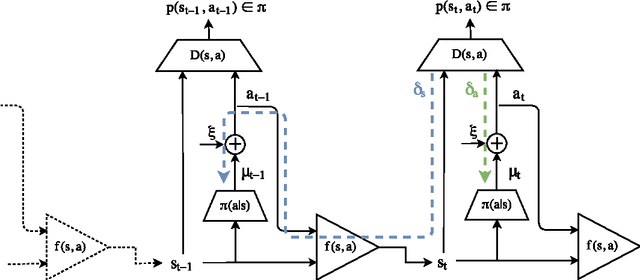

Generative adversarial learning is a popular new approach to training generative models which has been proven successful for other related problems as well. The general idea is to maintain an oracle $D$ that discriminates between the expert's data distribution and that of the generative model $G$. The generative model is trained to capture the expert's distribution by maximizing the probability of $D$ misclassifying the data it generates. Overall, the system is \emph{differentiable} end-to-end and is trained using basic backpropagation. This type of learning was successfully applied to the problem of policy imitation in a model-free setup. However, a model-free approach does not allow the system to be differentiable, which requires the use of high-variance gradient estimations. In this paper we introduce the Model based Adversarial Imitation Learning (MAIL) algorithm. A model-based approach for the problem of adversarial imitation learning. We show how to use a forward model to make the system fully differentiable, which enables us to train policies using the (stochastic) gradient of $D$. Moreover, our approach requires relatively few environment interactions, and fewer hyper-parameters to tune. We test our method on the MuJoCo physics simulator and report initial results that surpass the current state-of-the-art.