 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaximum Entropy Reinforcement Learning with Mixture Policies
Mar 18, 2021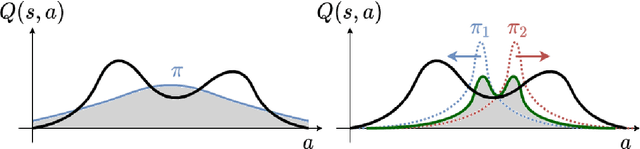

Mixture models are an expressive hypothesis class that can approximate a rich set of policies. However, using mixture policies in the Maximum Entropy (MaxEnt) framework is not straightforward. The entropy of a mixture model is not equal to the sum of its components, nor does it have a closed-form expression in most cases. Using such policies in MaxEnt algorithms, therefore, requires constructing a tractable approximation of the mixture entropy. In this paper, we derive a simple, low-variance mixture-entropy estimator. We show that it is closely related to the sum of marginal entropies. Equipped with our entropy estimator, we derive an algorithmic variant of Soft Actor-Critic (SAC) to the mixture policy case and evaluate it on a series of continuous control tasks.
Action Redundancy in Reinforcement Learning
Feb 22, 2021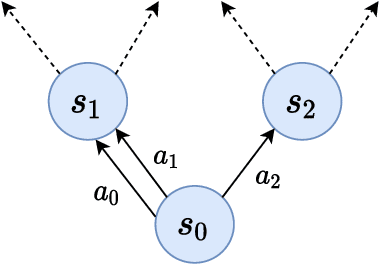

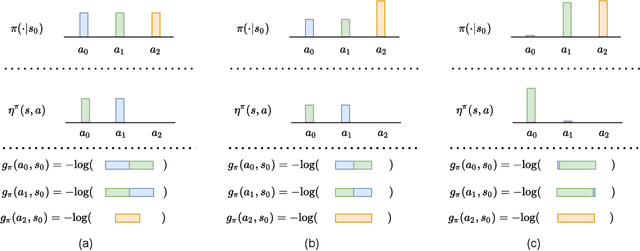

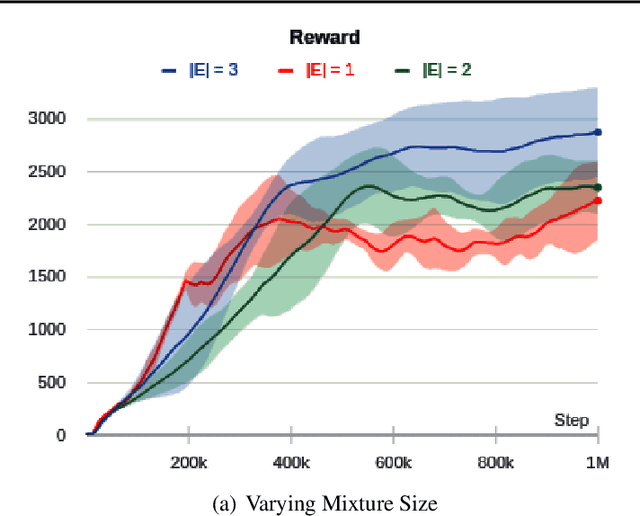
Maximum Entropy (MaxEnt) reinforcement learning is a powerful learning paradigm which seeks to maximize return under entropy regularization. However, action entropy does not necessarily coincide with state entropy, e.g., when multiple actions produce the same transition. Instead, we propose to maximize the transition entropy, i.e., the entropy of next states. We show that transition entropy can be described by two terms; namely, model-dependent transition entropy and action redundancy. Particularly, we explore the latter in both deterministic and stochastic settings and develop tractable approximation methods in a near model-free setup. We construct algorithms to minimize action redundancy and demonstrate their effectiveness on a synthetic environment with multiple redundant actions as well as contemporary benchmarks in Atari and Mujoco. Our results suggest that action redundancy is a fundamental problem in reinforcement learning.
GELATO: Geometrically Enriched Latent Model for Offline Reinforcement Learning
Feb 22, 2021
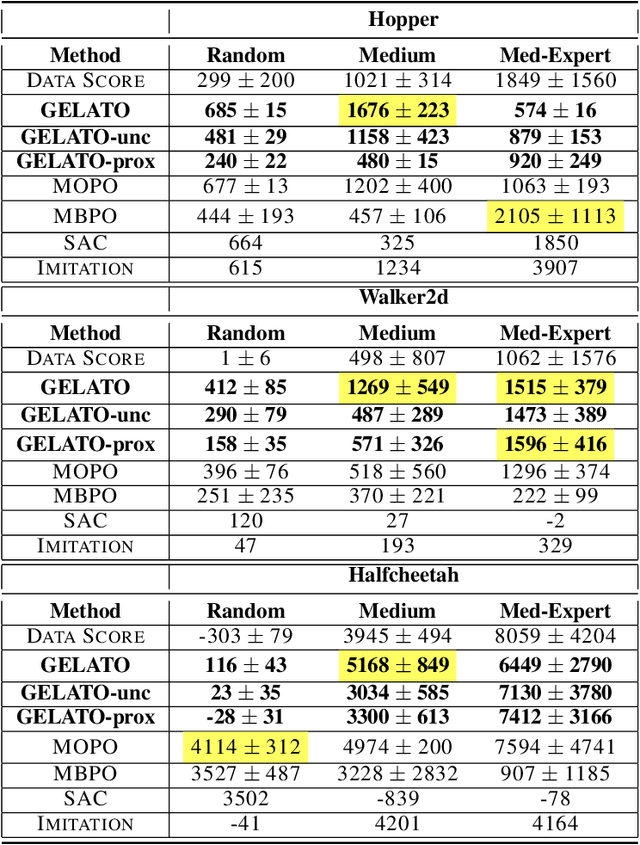
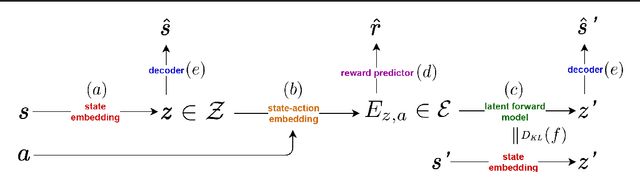
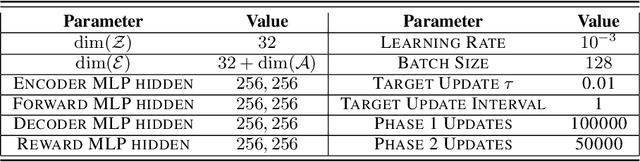
Offline reinforcement learning approaches can generally be divided to proximal and uncertainty-aware methods. In this work, we demonstrate the benefit of combining the two in a latent variational model. We impose a latent representation of states and actions and leverage its intrinsic Riemannian geometry to measure distance of latent samples to the data. Our proposed metrics measure both the quality of out of distribution samples as well as the discrepancy of examples in the data. We integrate our metrics in a model-based offline optimization framework, in which proximity and uncertainty can be carefully controlled. We illustrate the geodesics on a simple grid-like environment, depicting its natural inherent topology. Finally, we analyze our approach and improve upon contemporary offline RL benchmarks.
Inspiration Learning through Preferences
Sep 16, 2018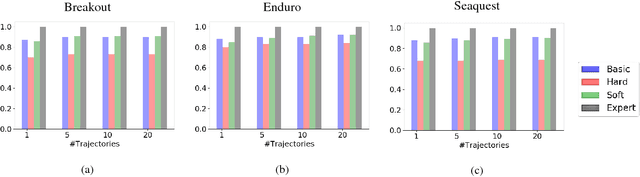
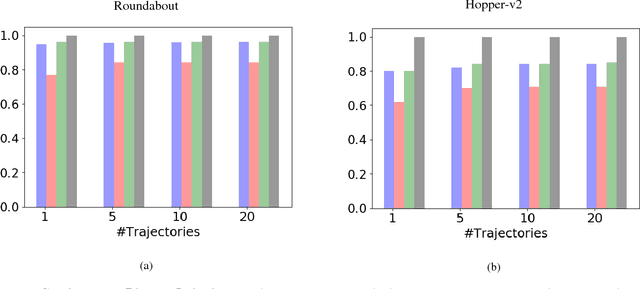
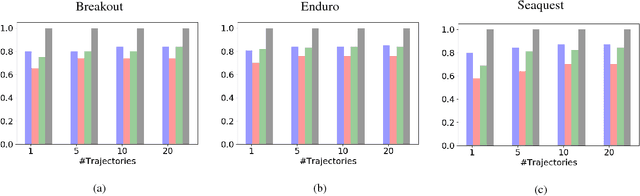
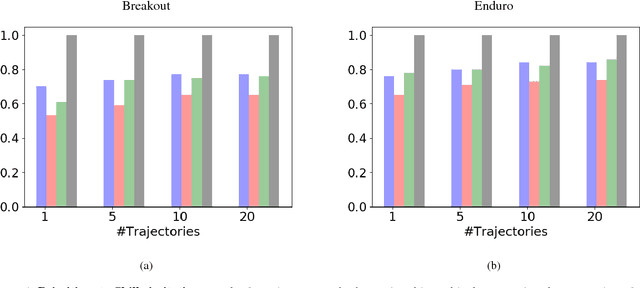
Current imitation learning techniques are too restrictive because they require the agent and expert to share the same action space. However, oftentimes agents that act differently from the expert can solve the task just as good. For example, a person lifting a box can be imitated by a ceiling mounted robot or a desktop-based robotic-arm. In both cases, the end goal of lifting the box is achieved, perhaps using different strategies. We denote this setup as \textit{Inspiration Learning} - knowledge transfer between agents that operate in different action spaces. Since state-action expert demonstrations can no longer be used, Inspiration learning requires novel methods to guide the agent towards the end goal. In this work, we rely on ideas of Preferential based Reinforcement Learning (PbRL) to design Advantage Actor-Critic algorithms for solving inspiration learning tasks. Unlike classic actor-critic architectures, the critic we use consists of two parts: a) a state-value estimation as in common actor-critic algorithms and b) a single step reward function derived from an expert/agent classifier. We show that our method is capable of extending the current imitation framework to new horizons. This includes continuous-to-discrete action imitation, as well as primitive-to-macro action imitation.
Averaged-DQN: Variance Reduction and Stabilization for Deep Reinforcement Learning
Mar 10, 2017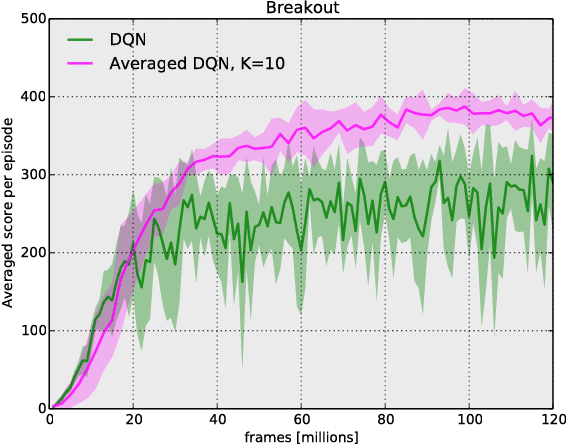
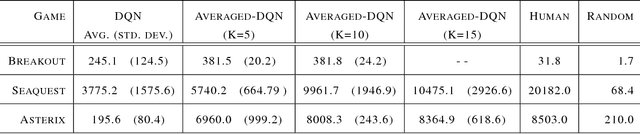
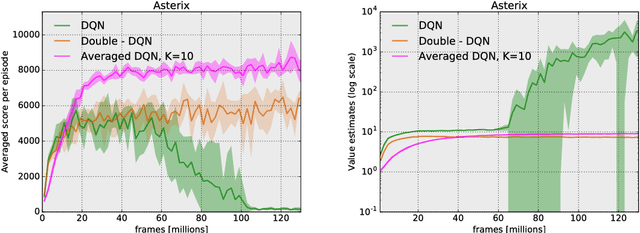

Instability and variability of Deep Reinforcement Learning (DRL) algorithms tend to adversely affect their performance. Averaged-DQN is a simple extension to the DQN algorithm, based on averaging previously learned Q-values estimates, which leads to a more stable training procedure and improved performance by reducing approximation error variance in the target values. To understand the effect of the algorithm, we examine the source of value function estimation errors and provide an analytical comparison within a simplified model. We further present experiments on the Arcade Learning Environment benchmark that demonstrate significantly improved stability and performance due to the proposed extension.
Model-based Adversarial Imitation Learning
Dec 07, 2016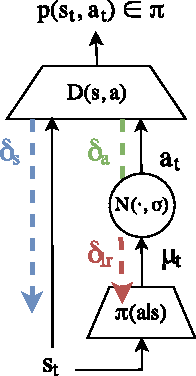
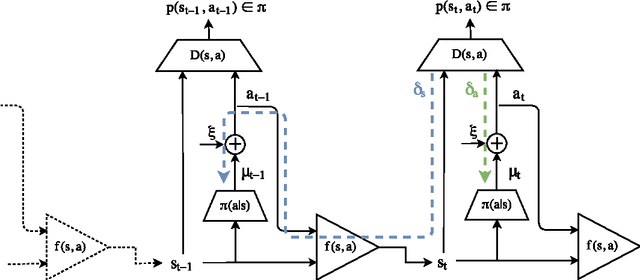

Generative adversarial learning is a popular new approach to training generative models which has been proven successful for other related problems as well. The general idea is to maintain an oracle $D$ that discriminates between the expert's data distribution and that of the generative model $G$. The generative model is trained to capture the expert's distribution by maximizing the probability of $D$ misclassifying the data it generates. Overall, the system is \emph{differentiable} end-to-end and is trained using basic backpropagation. This type of learning was successfully applied to the problem of policy imitation in a model-free setup. However, a model-free approach does not allow the system to be differentiable, which requires the use of high-variance gradient estimations. In this paper we introduce the Model based Adversarial Imitation Learning (MAIL) algorithm. A model-based approach for the problem of adversarial imitation learning. We show how to use a forward model to make the system fully differentiable, which enables us to train policies using the (stochastic) gradient of $D$. Moreover, our approach requires relatively few environment interactions, and fewer hyper-parameters to tune. We test our method on the MuJoCo physics simulator and report initial results that surpass the current state-of-the-art.
Deep Reinforcement Learning Discovers Internal Models
Jun 16, 2016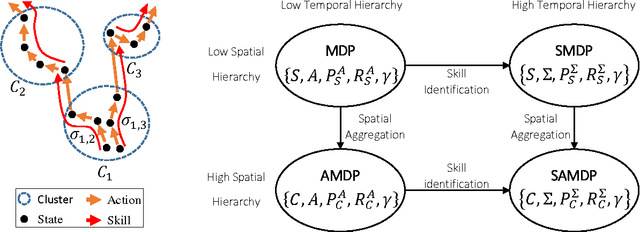

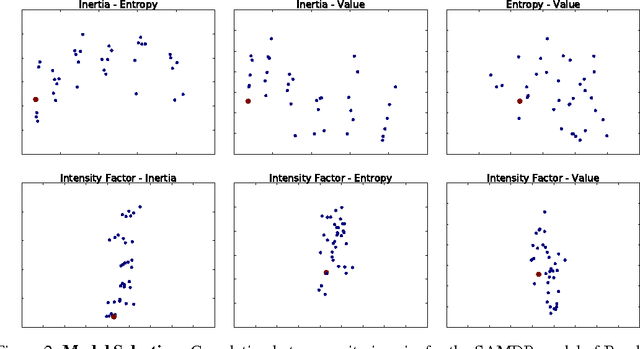
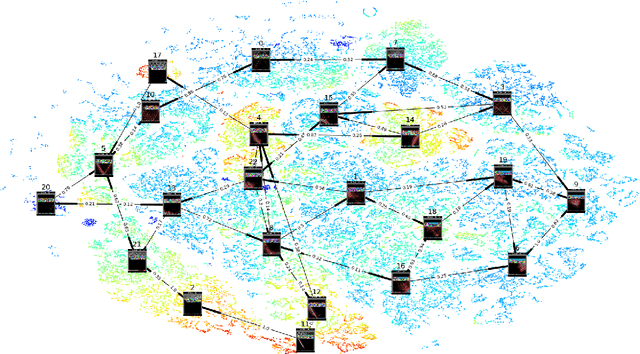
Deep Reinforcement Learning (DRL) is a trending field of research, showing great promise in challenging problems such as playing Atari, solving Go and controlling robots. While DRL agents perform well in practice we are still lacking the tools to analayze their performance. In this work we present the Semi-Aggregated MDP (SAMDP) model. A model best suited to describe policies exhibiting both spatial and temporal hierarchies. We describe its advantages for analyzing trained policies over other modeling approaches, and show that under the right state representation, like that of DQN agents, SAMDP can help to identify skills. We detail the automatic process of creating it from recorded trajectories, up to presenting it on t-SNE maps. We explain how to evaluate its fitness and show surprising results indicating high compatibility with the policy at hand. We conclude by showing how using the SAMDP model, an extra performance gain can be squeezed from the agent.