 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel-based Adversarial Imitation Learning
Paper and Code
Dec 07, 2016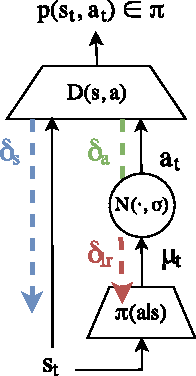
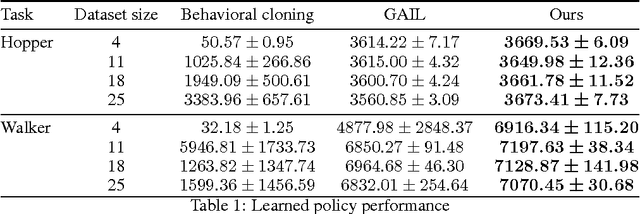
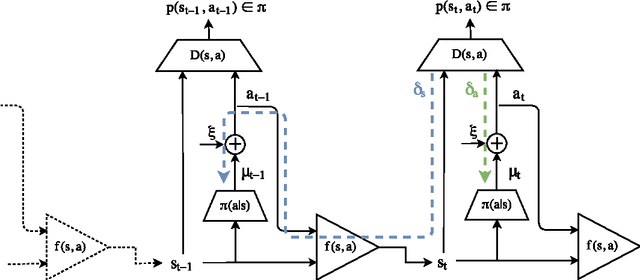

Generative adversarial learning is a popular new approach to training generative models which has been proven successful for other related problems as well. The general idea is to maintain an oracle $D$ that discriminates between the expert's data distribution and that of the generative model $G$. The generative model is trained to capture the expert's distribution by maximizing the probability of $D$ misclassifying the data it generates. Overall, the system is \emph{differentiable} end-to-end and is trained using basic backpropagation. This type of learning was successfully applied to the problem of policy imitation in a model-free setup. However, a model-free approach does not allow the system to be differentiable, which requires the use of high-variance gradient estimations. In this paper we introduce the Model based Adversarial Imitation Learning (MAIL) algorithm. A model-based approach for the problem of adversarial imitation learning. We show how to use a forward model to make the system fully differentiable, which enables us to train policies using the (stochastic) gradient of $D$. Moreover, our approach requires relatively few environment interactions, and fewer hyper-parameters to tune. We test our method on the MuJoCo physics simulator and report initial results that surpass the current state-of-the-art.