 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Reinforcement Learning Discovers Internal Models
Paper and Code
Jun 16, 2016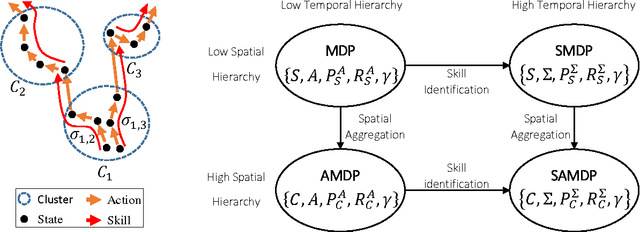

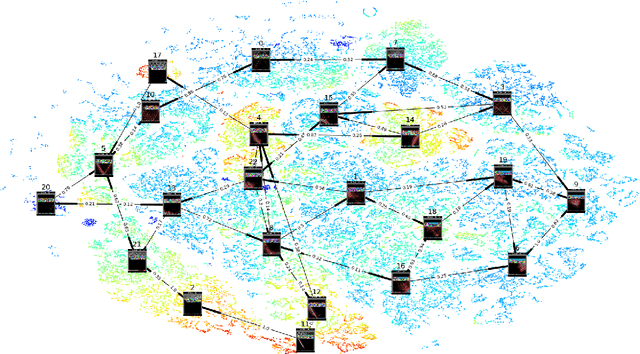
Deep Reinforcement Learning (DRL) is a trending field of research, showing great promise in challenging problems such as playing Atari, solving Go and controlling robots. While DRL agents perform well in practice we are still lacking the tools to analayze their performance. In this work we present the Semi-Aggregated MDP (SAMDP) model. A model best suited to describe policies exhibiting both spatial and temporal hierarchies. We describe its advantages for analyzing trained policies over other modeling approaches, and show that under the right state representation, like that of DQN agents, SAMDP can help to identify skills. We detail the automatic process of creating it from recorded trajectories, up to presenting it on t-SNE maps. We explain how to evaluate its fitness and show surprising results indicating high compatibility with the policy at hand. We conclude by showing how using the SAMDP model, an extra performance gain can be squeezed from the agent.