 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInspiration Learning through Preferences
Paper and Code
Sep 16, 2018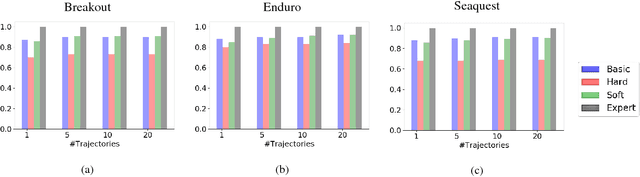
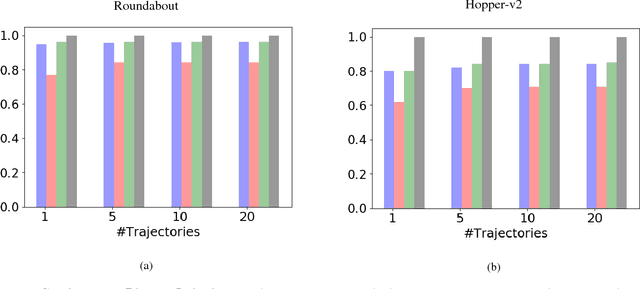
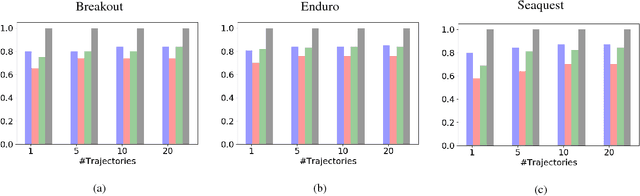
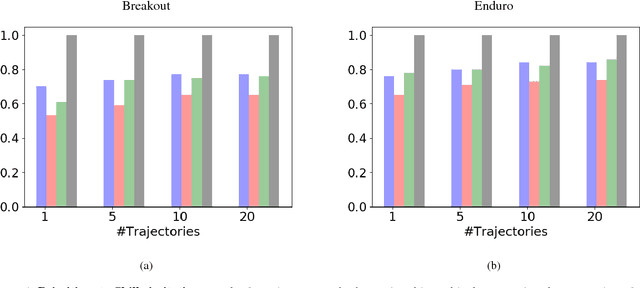
Current imitation learning techniques are too restrictive because they require the agent and expert to share the same action space. However, oftentimes agents that act differently from the expert can solve the task just as good. For example, a person lifting a box can be imitated by a ceiling mounted robot or a desktop-based robotic-arm. In both cases, the end goal of lifting the box is achieved, perhaps using different strategies. We denote this setup as \textit{Inspiration Learning} - knowledge transfer between agents that operate in different action spaces. Since state-action expert demonstrations can no longer be used, Inspiration learning requires novel methods to guide the agent towards the end goal. In this work, we rely on ideas of Preferential based Reinforcement Learning (PbRL) to design Advantage Actor-Critic algorithms for solving inspiration learning tasks. Unlike classic actor-critic architectures, the critic we use consists of two parts: a) a state-value estimation as in common actor-critic algorithms and b) a single step reward function derived from an expert/agent classifier. We show that our method is capable of extending the current imitation framework to new horizons. This includes continuous-to-discrete action imitation, as well as primitive-to-macro action imitation.