 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Coding Social Science Datasets with Language Models
Jun 03, 2023Researchers often rely on humans to code (label, annotate, etc.) large sets of texts. This kind of human coding forms an important part of social science research, yet the coding process is both resource intensive and highly variable from application to application. In some cases, efforts to automate this process have achieved human-level accuracies, but to achieve this, these attempts frequently rely on thousands of hand-labeled training examples, which makes them inapplicable to small-scale research studies and costly for large ones. Recent advances in a specific kind of artificial intelligence tool - language models (LMs) - provide a solution to this problem. Work in computer science makes it clear that LMs are able to classify text, without the cost (in financial terms and human effort) of alternative methods. To demonstrate the possibilities of LMs in this area of political science, we use GPT-3, one of the most advanced LMs, as a synthetic coder and compare it to human coders. We find that GPT-3 can match the performance of typical human coders and offers benefits over other machine learning methods of coding text. We find this across a variety of domains using very different coding procedures. This provides exciting evidence that language models can serve as a critical advance in the coding of open-ended texts in a variety of applications.
AI Chat Assistants can Improve Conversations about Divisive Topics
Feb 21, 2023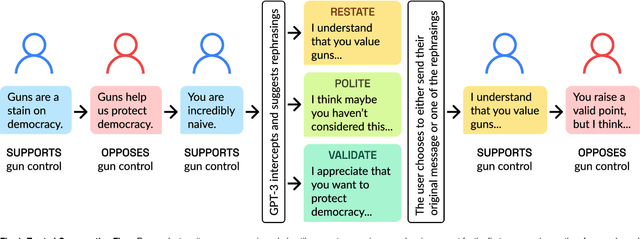
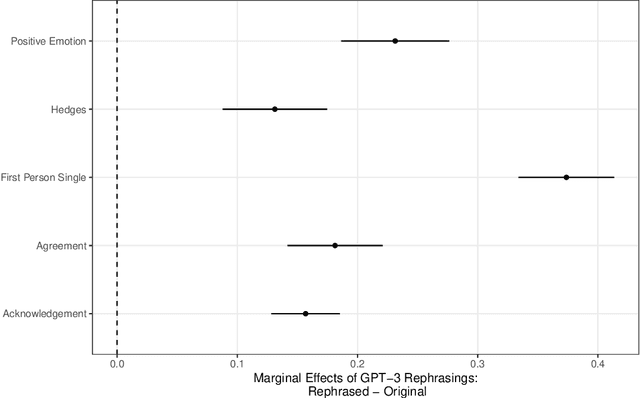
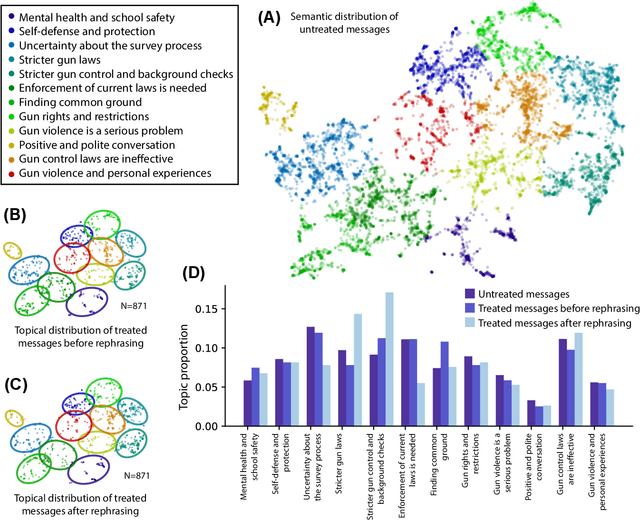
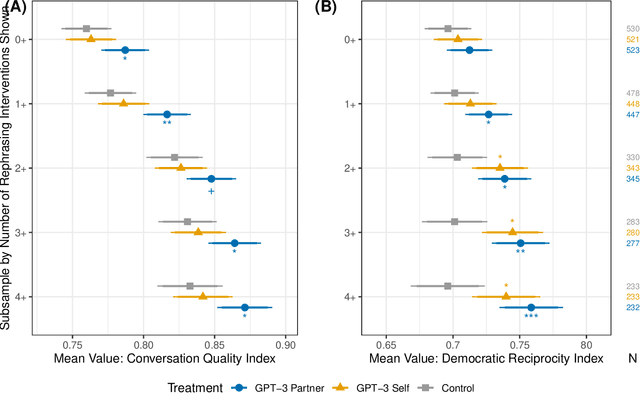
A rapidly increasing amount of human conversation occurs online. But divisiveness and conflict can fester in text-based interactions on social media platforms, in messaging apps, and on other digital forums. Such toxicity increases polarization and, importantly, corrodes the capacity of diverse societies to develop efficient solutions to complex social problems that impact everyone. Scholars and civil society groups promote interventions that can make interpersonal conversations less divisive or more productive in offline settings, but scaling these efforts to the amount of discourse that occurs online is extremely challenging. We present results of a large-scale experiment that demonstrates how online conversations about divisive topics can be improved with artificial intelligence tools. Specifically, we employ a large language model to make real-time, evidence-based recommendations intended to improve participants' perception of feeling understood in conversations. We find that these interventions improve the reported quality of the conversation, reduce political divisiveness, and improve the tone, without systematically changing the content of the conversation or moving people's policy attitudes. These findings have important implications for future research on social media, political deliberation, and the growing community of scholars interested in the place of artificial intelligence within computational social science.