 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRedefining AI Red Teaming in the Agentic Era: From Weeks to Hours
May 05, 2026AI systems are entering critical domains like healthcare, finance, and defense, yet remain vulnerable to adversarial attacks. While AI red teaming is a primary defense, current approaches force operators into manual, library-specific workflows. Operators spend weeks hand-crafting workflows - assembling attacks, transforms, and scorers. When results fall short, workflows must be rebuilt. As a result, operators spend more time constructing workflows than probing targets for security and safety vulnerabilities. We introduce an AI red teaming agent built on the open-source Dreadnode SDK. The agent creates workflows grounded in 45+ adversarial attacks, 450+ transforms, and 130+ scorers. Operators can probe multi-agent systems, multilingual, and multimodal targets, focusing on what to probe rather than how to implement it. We make three contributions: 1. Agentic interface. Operators describe goals in natural language via the Dreadnode TUI (Terminal User Interface). The agent handles attack selection, transform composition, execution, and reporting, letting operators focus on red teaming. Weeks compress to hours. 2. Unified framework. A single framework for probing traditional ML models (adversarial examples) and generative AI systems (jailbreaks), removing the need for separate libraries. 3. Llama Scout case study. We red team Meta Llama Scout and achieve an 85% attack success rate with severity up to 1.0, using zero human-developed code
Poisoning Web-Scale Training Datasets is Practical
Feb 20, 2023Deep learning models are often trained on distributed, webscale datasets crawled from the internet. In this paper, we introduce two new dataset poisoning attacks that intentionally introduce malicious examples to a model's performance. Our attacks are immediately practical and could, today, poison 10 popular datasets. Our first attack, split-view poisoning, exploits the mutable nature of internet content to ensure a dataset annotator's initial view of the dataset differs from the view downloaded by subsequent clients. By exploiting specific invalid trust assumptions, we show how we could have poisoned 0.01% of the LAION-400M or COYO-700M datasets for just $60 USD. Our second attack, frontrunning poisoning, targets web-scale datasets that periodically snapshot crowd-sourced content -- such as Wikipedia -- where an attacker only needs a time-limited window to inject malicious examples. In light of both attacks, we notify the maintainers of each affected dataset and recommended several low-overhead defenses.
Machine Learning for Offensive Security: Sandbox Classification Using Decision Trees and Artificial Neural Networks
Jul 14, 2020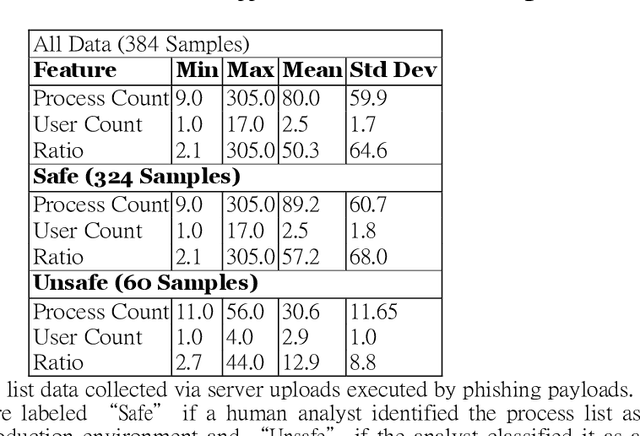
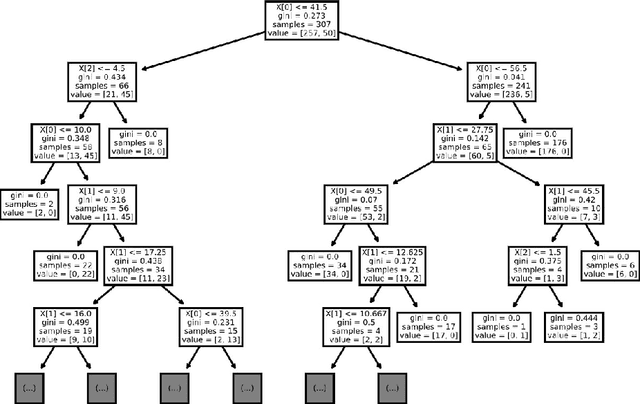
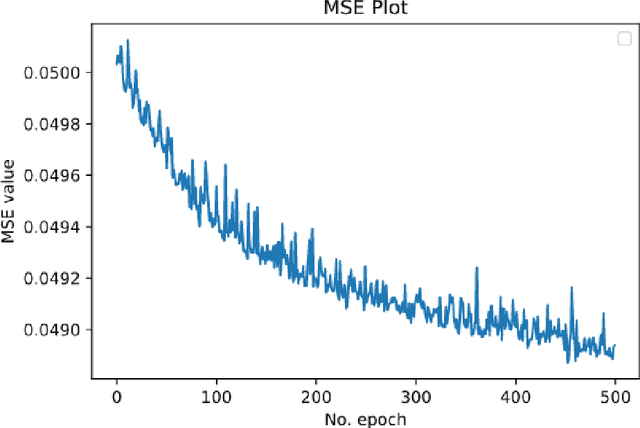
The merits of machine learning in information security have primarily focused on bolstering defenses. However, machine learning (ML) techniques are not reserved for organizations with deep pockets and massive data repositories; the democratization of ML has lead to a rise in the number of security teams using ML to support offensive operations. The research presented here will explore two models that our team has used to solve a single offensive task, detecting a sandbox. Using process list data gathered with phishing emails, we will demonstrate the use of Decision Trees and Artificial Neural Networks to successfully classify sandboxes, thereby avoiding unsafe execution. This paper aims to give unique insight into how a real offensive team is using machine learning to support offensive operations.