 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeta-Whisper: Speech-Based Meta-ICL for ASR on Low-Resource Languages
Sep 16, 2024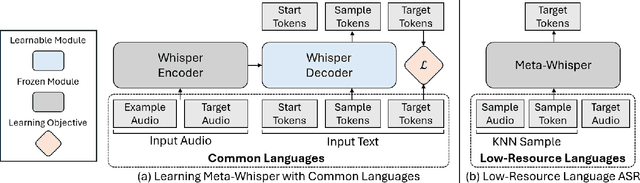
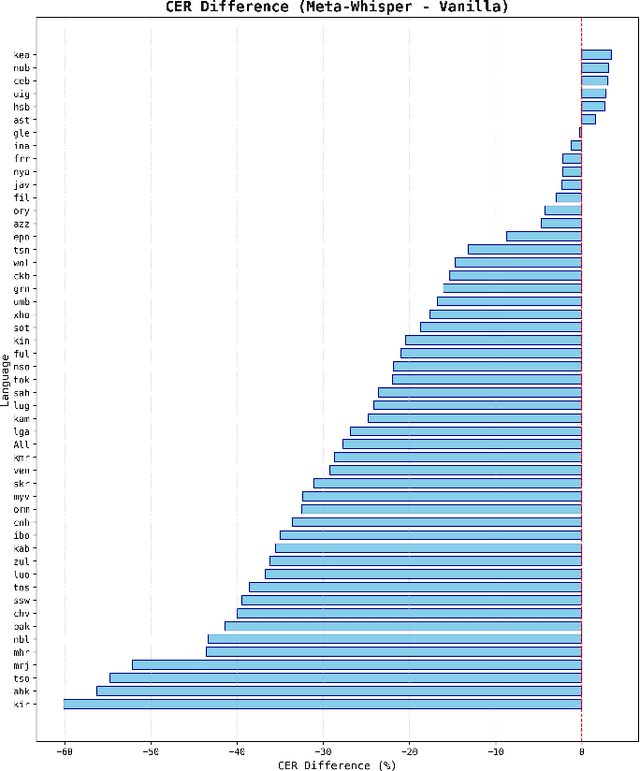


This paper presents Meta-Whisper, a novel approach to improve automatic speech recognition (ASR) for low-resource languages using the Whisper model. By leveraging Meta In-Context Learning (Meta-ICL) and a k-Nearest Neighbors (KNN) algorithm for sample selection, Meta-Whisper enhances Whisper's ability to recognize speech in unfamiliar languages without extensive fine-tuning. Experiments on the ML-SUPERB dataset show that Meta-Whisper significantly reduces the Character Error Rate (CER) for low-resource languages compared to the original Whisper model. This method offers a promising solution for developing more adaptable multilingual ASR systems, particularly for languages with limited resources.
Improving Distortion Robustness of Self-supervised Speech Processing Tasks with Domain Adaptation
Mar 30, 2022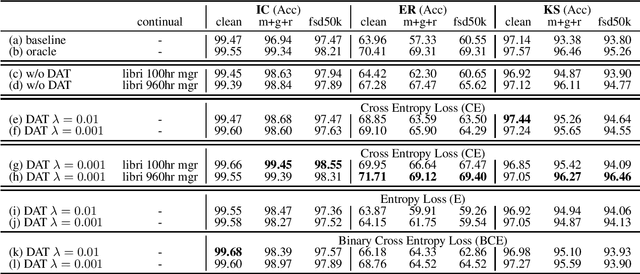
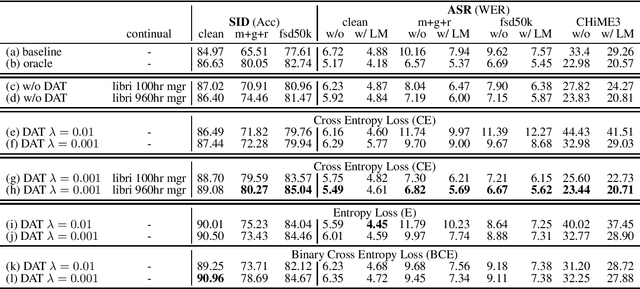
Speech distortions are a long-standing problem that degrades the performance of supervisely trained speech processing models. It is high time that we enhance the robustness of speech processing models to obtain good performance when encountering speech distortions while not hurting the original performance on clean speech. In this work, we propose to improve the robustness of speech processing models by domain adversarial training (DAT). We conducted experiments based on the SUPERB framework on five different speech processing tasks. In case we do not always have knowledge of the distortion types for speech data, we analyzed the binary-domain and multi-domain settings, where the former treats all distorted speech as one domain, and the latter views different distortions as different domains. In contrast to supervised training methods, we obtained promising results in target domains where speech data is distorted with different distortions including new unseen distortions introduced during testing.