 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeveloping Instruction-Following Speech Language Model Without Speech Instruction-Tuning Data
Paper and Code
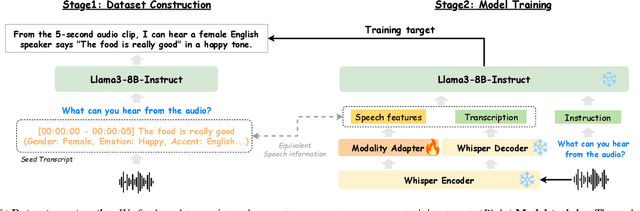
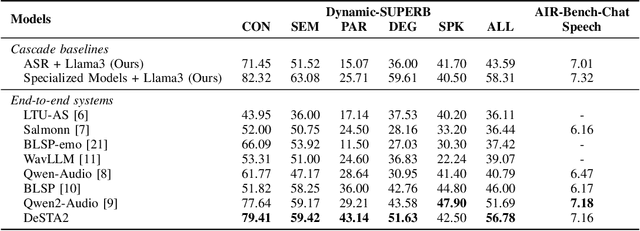
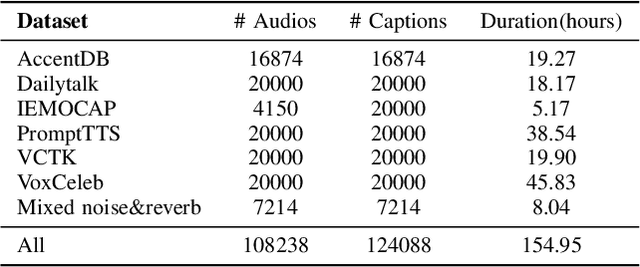
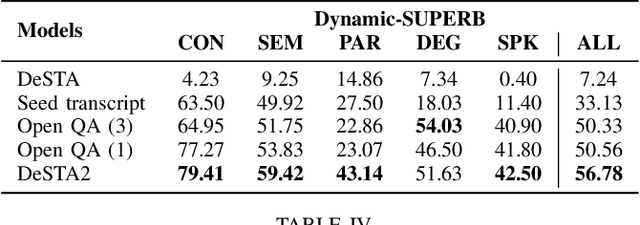
Recent end-to-end speech language models (SLMs) have expanded upon the capabilities of large language models (LLMs) by incorporating pre-trained speech models. However, these SLMs often undergo extensive speech instruction-tuning to bridge the gap between speech and text modalities. This requires significant annotation efforts and risks catastrophic forgetting of the original language capabilities. In this work, we present a simple yet effective automatic process for creating speech-text pair data that carefully injects speech paralinguistic understanding abilities into SLMs while preserving the inherent language capabilities of the text-based LLM. Our model demonstrates general capabilities for speech-related tasks without the need for speech instruction-tuning data, achieving impressive performance on Dynamic-SUPERB and AIR-Bench-Chat benchmarks. Furthermore, our model exhibits the ability to follow complex instructions derived from LLMs, such as specific output formatting and chain-of-thought reasoning. Our approach not only enhances the versatility and effectiveness of SLMs but also reduces reliance on extensive annotated datasets, paving the way for more efficient and capable speech understanding systems.