 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeech-Hands: A Self-Reflection Voice Agentic Approach to Speech Recognition and Audio Reasoning with Omni Perception
Jan 14, 2026We introduce a voice-agentic framework that learns one critical omni-understanding skill: knowing when to trust itself versus when to consult external audio perception. Our work is motivated by a crucial yet counterintuitive finding: naively fine-tuning an omni-model on both speech recognition and external sound understanding tasks often degrades performance, as the model can be easily misled by noisy hypotheses. To address this, our framework, Speech-Hands, recasts the problem as an explicit self-reflection decision. This learnable reflection primitive proves effective in preventing the model from being derailed by flawed external candidates. We show that this agentic action mechanism generalizes naturally from speech recognition to complex, multiple-choice audio reasoning. Across the OpenASR leaderboard, Speech-Hands consistently outperforms strong baselines by 12.1% WER on seven benchmarks. The model also achieves 77.37% accuracy and high F1 on audio QA decisions, showing robust generalization and reliability across diverse audio question answering datasets. By unifying perception and decision-making, our work offers a practical path toward more reliable and resilient audio intelligence.
What do Speech Foundation Models Learn? Analysis and Applications
Aug 17, 2025Speech foundation models (SFMs) are designed to serve as general-purpose representations for a wide range of speech-processing tasks. The last five years have seen an influx of increasingly successful self-supervised and supervised pre-trained models with impressive performance on various downstream tasks. Although the zoo of SFMs continues to grow, our understanding of the knowledge they acquire lags behind. This thesis presents a lightweight analysis framework using statistical tools and training-free tasks to investigate the acoustic and linguistic knowledge encoded in SFM layers. We conduct a comparative study across multiple SFMs and statistical tools. Our study also shows that the analytical insights have concrete implications for downstream task performance. The effectiveness of an SFM is ultimately determined by its performance on speech applications. Yet it remains unclear whether the benefits extend to spoken language understanding (SLU) tasks that require a deeper understanding than widely studied ones, such as speech recognition. The limited exploration of SLU is primarily due to a lack of relevant datasets. To alleviate that, this thesis contributes tasks, specifically spoken named entity recognition (NER) and named entity localization (NEL), to the Spoken Language Understanding Evaluation benchmark. We develop SFM-based approaches for NER and NEL, and find that end-to-end (E2E) models leveraging SFMs can surpass traditional cascaded (speech recognition followed by a text model) approaches. Further, we evaluate E2E SLU models across SFMs and adaptation strategies to assess the impact on task performance. Collectively, this thesis tackles previously unanswered questions about SFMs, providing tools and datasets to further our understanding and to enable the community to make informed design choices for future model development and adoption.
Training and Inference Efficiency of Encoder-Decoder Speech Models
Mar 07, 2025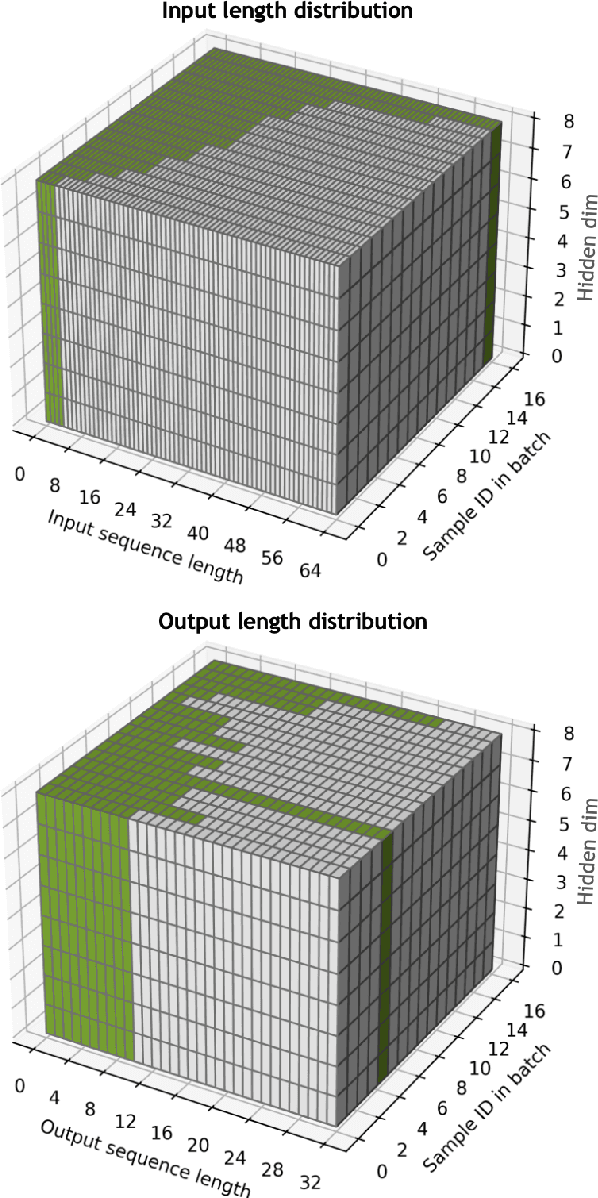

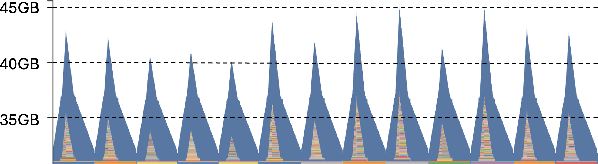
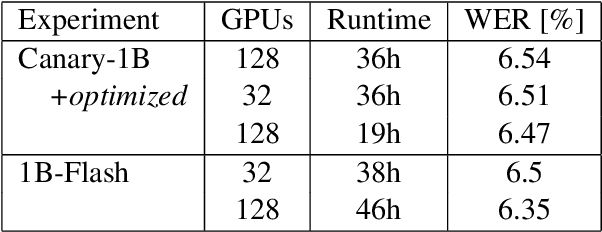
Attention encoder-decoder model architecture is the backbone of several recent top performing foundation speech models: Whisper, Seamless, OWSM, and Canary-1B. However, the reported data and compute requirements for their training are prohibitive for many in the research community. In this work, we focus on the efficiency angle and ask the questions of whether we are training these speech models efficiently, and what can we do to improve? We argue that a major, if not the most severe, detrimental factor for training efficiency is related to the sampling strategy of sequential data. We show that negligence in mini-batch sampling leads to more than 50% computation being spent on padding. To that end, we study, profile, and optimize Canary-1B training to show gradual improvement in GPU utilization leading up to 5x increase in average batch sizes versus its original training settings. This in turn allows us to train an equivalent model using 4x less GPUs in the same wall time, or leverage the original resources and train it in 2x shorter wall time. Finally, we observe that the major inference bottleneck lies in the autoregressive decoder steps. We find that adjusting the model architecture to transfer model parameters from the decoder to the encoder results in a 3x inference speedup as measured by inverse real-time factor (RTFx) while preserving the accuracy and compute requirements for convergence. The training code and models will be available as open-source.
Dynamic-SUPERB Phase-2: A Collaboratively Expanding Benchmark for Measuring the Capabilities of Spoken Language Models with 180 Tasks
Nov 08, 2024



Multimodal foundation models, such as Gemini and ChatGPT, have revolutionized human-machine interactions by seamlessly integrating various forms of data. Developing a universal spoken language model that comprehends a wide range of natural language instructions is critical for bridging communication gaps and facilitating more intuitive interactions. However, the absence of a comprehensive evaluation benchmark poses a significant challenge. We present Dynamic-SUPERB Phase-2, an open and evolving benchmark for the comprehensive evaluation of instruction-based universal speech models. Building upon the first generation, this second version incorporates 125 new tasks contributed collaboratively by the global research community, expanding the benchmark to a total of 180 tasks, making it the largest benchmark for speech and audio evaluation. While the first generation of Dynamic-SUPERB was limited to classification tasks, Dynamic-SUPERB Phase-2 broadens its evaluation capabilities by introducing a wide array of novel and diverse tasks, including regression and sequence generation, across speech, music, and environmental audio. Evaluation results indicate that none of the models performed well universally. SALMONN-13B excelled in English ASR, while WavLLM demonstrated high accuracy in emotion recognition, but current models still require further innovations to handle a broader range of tasks. We will soon open-source all task data and the evaluation pipeline.
On the Evaluation of Speech Foundation Models for Spoken Language Understanding
Jun 14, 2024The Spoken Language Understanding Evaluation (SLUE) suite of benchmark tasks was recently introduced to address the need for open resources and benchmarking of complex spoken language understanding (SLU) tasks, including both classification and sequence generation tasks, on natural speech. The benchmark has demonstrated preliminary success in using pre-trained speech foundation models (SFM) for these SLU tasks. However, the community still lacks a fine-grained understanding of the comparative utility of different SFMs. Inspired by this, we ask: which SFMs offer the most benefits for these complex SLU tasks, and what is the most effective approach for incorporating these SFMs? To answer this, we perform an extensive evaluation of multiple supervised and self-supervised SFMs using several evaluation protocols: (i) frozen SFMs with a lightweight prediction head, (ii) frozen SFMs with a complex prediction head, and (iii) fine-tuned SFMs with a lightweight prediction head. Although the supervised SFMs are pre-trained on much more speech recognition data (with labels), they do not always outperform self-supervised SFMs; the latter tend to perform at least as well as, and sometimes better than, supervised SFMs, especially on the sequence generation tasks in SLUE. While there is no universally optimal way of incorporating SFMs, the complex prediction head gives the best performance for most tasks, although it increases the inference time. We also introduce an open-source toolkit and performance leaderboard, SLUE-PERB, for these tasks and modeling strategies.
Self-Supervised Speech Representations are More Phonetic than Semantic
Jun 12, 2024



Self-supervised speech models (S3Ms) have become an effective backbone for speech applications. Various analyses suggest that S3Ms encode linguistic properties. In this work, we seek a more fine-grained analysis of the word-level linguistic properties encoded in S3Ms. Specifically, we curate a novel dataset of near homophone (phonetically similar) and synonym (semantically similar) word pairs and measure the similarities between S3M word representation pairs. Our study reveals that S3M representations consistently and significantly exhibit more phonetic than semantic similarity. Further, we question whether widely used intent classification datasets such as Fluent Speech Commands and Snips Smartlights are adequate for measuring semantic abilities. Our simple baseline, using only the word identity, surpasses S3M-based models. This corroborates our findings and suggests that high scores on these datasets do not necessarily guarantee the presence of semantic content.
What do self-supervised speech models know about words?
Jun 30, 2023Many self-supervised speech models (S3Ms) have been introduced over the last few years, producing performance and data efficiency improvements for a variety of speech tasks. Evidence is emerging that different S3Ms encode linguistic information in different layers, and also that some S3Ms appear to learn phone-like sub-word units. However, the extent to which these models capture larger linguistic units, such as words, and where word-related information is encoded, remains unclear. In this study, we conduct several analyses of word segment representations extracted from different layers of three S3Ms: wav2vec2, HuBERT, and WavLM. We employ canonical correlation analysis (CCA), a lightweight analysis tool, to measure the similarity between these representations and word-level linguistic properties. We find that the maximal word-level linguistic content tends to be found in intermediate model layers, while some lower-level information like pronunciation is also retained in higher layers of HuBERT and WavLM. Syntactic and semantic word attributes have similar layer-wise behavior. We also find that, for all of the models tested, word identity information is concentrated near the center of each word segment. We then test the layer-wise performance of the same models, when used directly with no additional learned parameters, on several tasks: acoustic word discrimination, word segmentation, and semantic sentence similarity. We find similar layer-wise trends in performance, and furthermore, find that when using the best-performing layer of HuBERT or WavLM, it is possible to achieve performance on word segmentation and sentence similarity that rivals more complex existing approaches.
SLUE Phase-2: A Benchmark Suite of Diverse Spoken Language Understanding Tasks
Dec 20, 2022Spoken language understanding (SLU) tasks have been studied for many decades in the speech research community, but have not received as much attention as lower-level tasks like speech and speaker recognition. In particular, there are not nearly as many SLU task benchmarks, and many of the existing ones use data that is not freely available to all researchers. Recent work has begun to introduce such benchmark datasets for several tasks. In this work, we introduce several new annotated SLU benchmark tasks based on freely available speech data, which complement existing benchmarks and address gaps in the SLU evaluation landscape. We contribute four tasks: question answering and summarization involve inference over longer speech sequences; named entity localization addresses the speech-specific task of locating the targeted content in the signal; dialog act classification identifies the function of a given speech utterance. We follow the blueprint of the Spoken Language Understanding Evaluation (SLUE) benchmark suite. In order to facilitate the development of SLU models that leverage the success of pre-trained speech representations, we will be publishing for each task (i) annotations for a relatively small fine-tuning set, (ii) annotated development and test sets, and (iii) baseline models for easy reproducibility and comparisons. In this work, we present the details of data collection and annotation and the performance of the baseline models. We also perform sensitivity analysis of pipeline models' performance (speech recognizer + text model) to the speech recognition accuracy, using more than 20 state-of-the-art speech recognition models.
Comparative layer-wise analysis of self-supervised speech models
Nov 08, 2022Many self-supervised speech models, varying in their pre-training objective, input modality, and pre-training data, have been proposed in the last few years. Despite impressive empirical successes on downstream tasks, we still have a limited understanding of the properties encoded by the models and the differences across models. In this work, we examine the intermediate representations for a variety of recent models. Specifically, we measure acoustic, phonetic, and word-level properties encoded in individual layers, using a lightweight analysis tool based on canonical correlation analysis (CCA). We find that these properties evolve across layers differently depending on the model, and the variations relate to the choice of pre-training objective. We further investigate the utility of our analyses for downstream tasks by comparing the property trends with performance on speech recognition and spoken language understanding tasks. We discover that CCA trends provide reliable guidance to choose layers of interest for downstream tasks and that single-layer performance often matches or improves upon using all layers, suggesting implications for more efficient use of pre-trained models.
Hidden State Variability of Pretrained Language Models Can Guide Computation Reduction for Transfer Learning
Oct 19, 2022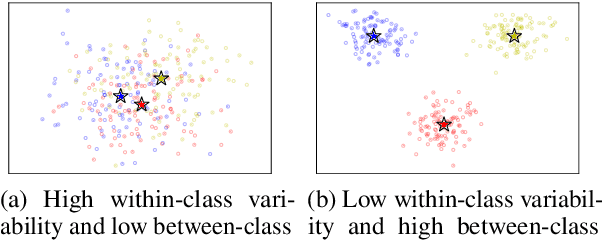
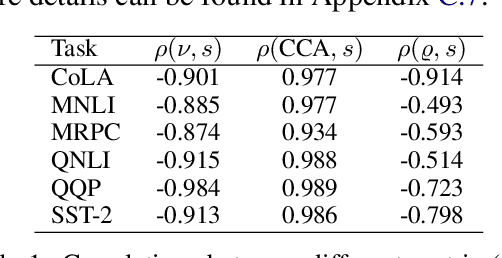
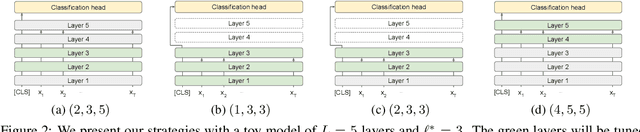
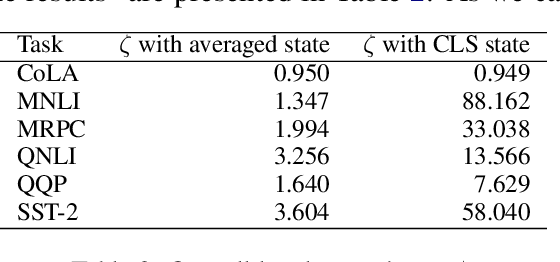
While transferring a pretrained language model, common approaches conventionally attach their task-specific classifiers to the top layer and adapt all the pretrained layers. We investigate whether one could make a task-specific selection on which subset of the layers to adapt and where to place the classifier. The goal is to reduce the computation cost of transfer learning methods (e.g. fine-tuning or adapter-tuning) without sacrificing its performance. We propose to select layers based on the variability of their hidden states given a task-specific corpus. We say a layer is already "well-specialized" in a task if the within-class variability of its hidden states is low relative to the between-class variability. Our variability metric is cheap to compute and doesn't need any training or hyperparameter tuning. It is robust to data imbalance and data scarcity. Extensive experiments on the GLUE benchmark demonstrate that selecting layers based on our metric can yield significantly stronger performance than using the same number of top layers and often match the performance of fine-tuning or adapter-tuning the entire language model.