 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural approaches to spoken content embedding
Aug 28, 2023



Comparing spoken segments is a central operation to speech processing. Traditional approaches in this area have favored frame-level dynamic programming algorithms, such as dynamic time warping, because they require no supervision, but they are limited in performance and efficiency. As an alternative, acoustic word embeddings -- fixed-dimensional vector representations of variable-length spoken word segments -- have begun to be considered for such tasks as well. However, the current space of such discriminative embedding models, training approaches, and their application to real-world downstream tasks is limited. We start by considering ``single-view" training losses where the goal is to learn an acoustic word embedding model that separates same-word and different-word spoken segment pairs. Then, we consider ``multi-view" contrastive losses. In this setting, acoustic word embeddings are learned jointly with embeddings of character sequences to generate acoustically grounded embeddings of written words, or acoustically grounded word embeddings. In this thesis, we contribute new discriminative acoustic word embedding (AWE) and acoustically grounded word embedding (AGWE) approaches based on recurrent neural networks (RNNs). We improve model training in terms of both efficiency and performance. We take these developments beyond English to several low-resource languages and show that multilingual training improves performance when labeled data is limited. We apply our embedding models, both monolingual and multilingual, to the downstream tasks of query-by-example speech search and automatic speech recognition. Finally, we show how our embedding approaches compare with and complement more recent self-supervised speech models.
What do self-supervised speech models know about words?
Jun 30, 2023Many self-supervised speech models (S3Ms) have been introduced over the last few years, producing performance and data efficiency improvements for a variety of speech tasks. Evidence is emerging that different S3Ms encode linguistic information in different layers, and also that some S3Ms appear to learn phone-like sub-word units. However, the extent to which these models capture larger linguistic units, such as words, and where word-related information is encoded, remains unclear. In this study, we conduct several analyses of word segment representations extracted from different layers of three S3Ms: wav2vec2, HuBERT, and WavLM. We employ canonical correlation analysis (CCA), a lightweight analysis tool, to measure the similarity between these representations and word-level linguistic properties. We find that the maximal word-level linguistic content tends to be found in intermediate model layers, while some lower-level information like pronunciation is also retained in higher layers of HuBERT and WavLM. Syntactic and semantic word attributes have similar layer-wise behavior. We also find that, for all of the models tested, word identity information is concentrated near the center of each word segment. We then test the layer-wise performance of the same models, when used directly with no additional learned parameters, on several tasks: acoustic word discrimination, word segmentation, and semantic sentence similarity. We find similar layer-wise trends in performance, and furthermore, find that when using the best-performing layer of HuBERT or WavLM, it is possible to achieve performance on word segmentation and sentence similarity that rivals more complex existing approaches.
Acoustic span embeddings for multilingual query-by-example search
Nov 24, 2020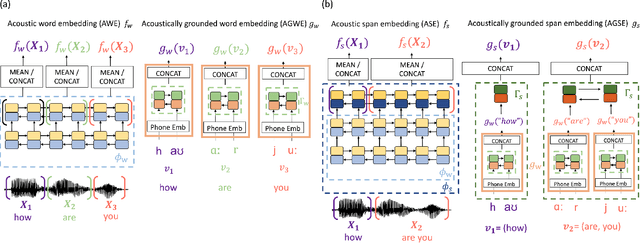
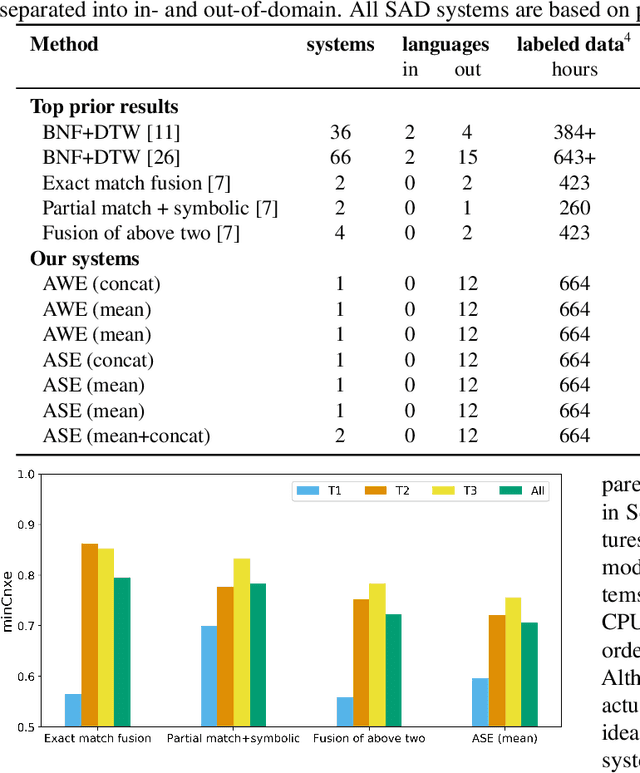

Query-by-example (QbE) speech search is the task of matching spoken queries to utterances within a search collection. In low- or zero-resource settings, QbE search is often addressed with approaches based on dynamic time warping (DTW). Recent work has found that methods based on acoustic word embeddings (AWEs) can improve both performance and search speed. However, prior work on AWE-based QbE has primarily focused on English data and with single-word queries. In this work, we generalize AWE training to spans of words, producing acoustic span embeddings (ASE), and explore the application of ASE to QbE with arbitrary-length queries in multiple unseen languages. We consider the commonly used setting where we have access to labeled data in other languages (in our case, several low-resource languages) distinct from the unseen test languages. We evaluate our approach on the QUESST 2015 QbE tasks, finding that multilingual ASE-based search is much faster than DTW-based search and outperforms the best previously published results on this task.
Whole-Word Segmental Speech Recognition with Acoustic Word Embeddings
Jul 01, 2020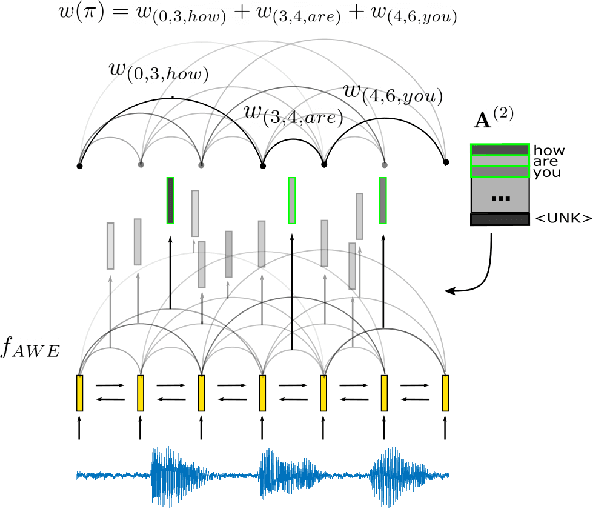
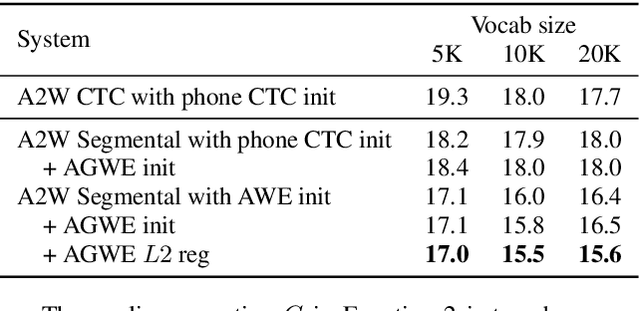
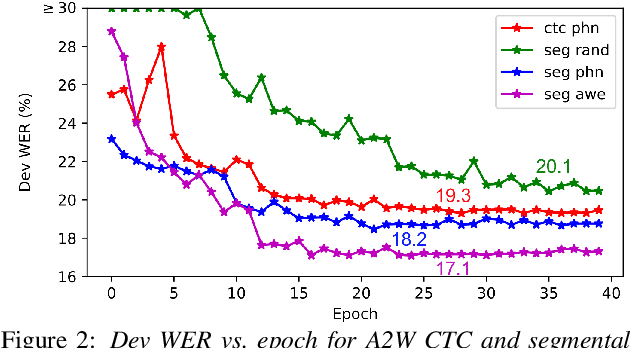
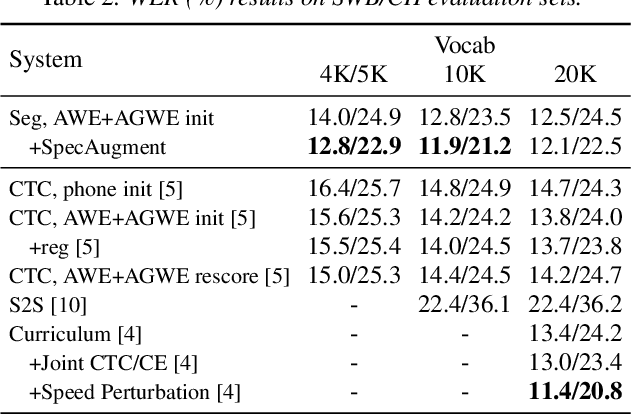
Segmental models are sequence prediction models in which scores of hypotheses are based on entire variable-length segments of frames. We consider segmental models for whole-word ("acoustic-to-word") speech recognition, with the segment feature vectors defined using acoustic word embeddings. Such models are computationally challenging as the number of paths is proportional to the vocabulary size, which can be orders of magnitude larger than when using subword units like phones. We describe an efficient approach for end-to-end whole-word segmental models, with forward-backward and Viterbi decoding performed on a GPU and a simple segment scoring function that reduces space complexity. In addition, we investigate the use of pre-training via jointly trained acoustic word embeddings (AWEs) and acoustically grounded word embeddings (AGWEs) of written word labels. We find that word error rate can be reduced by a large margin by pre-training the acoustic representation with AWEs, and additional (smaller) gains can be obtained by pre-training the word prediction layer with AGWEs. Our final models improve over comparable A2W models.
Multilingual Jointly Trained Acoustic and Written Word Embeddings
Jun 24, 2020
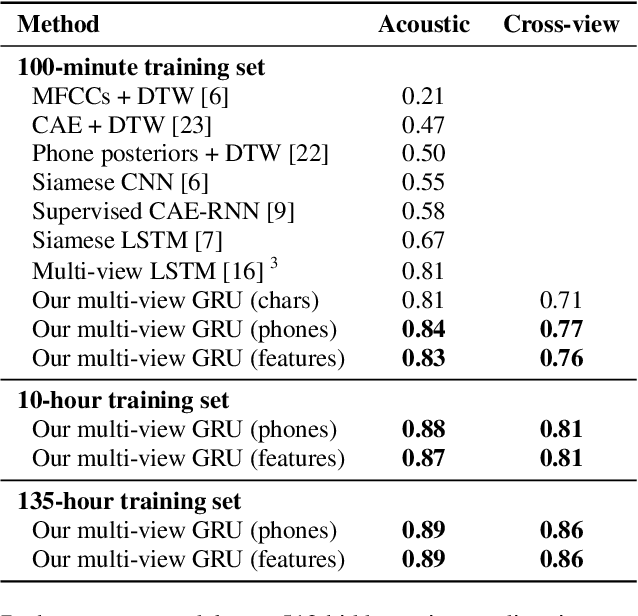
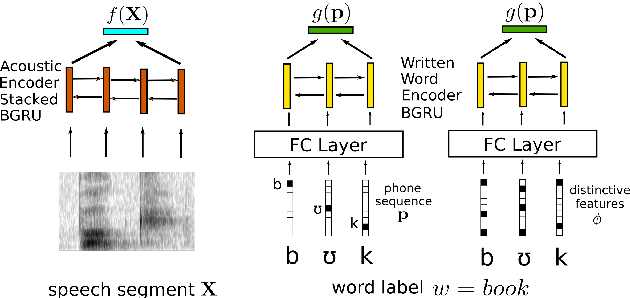
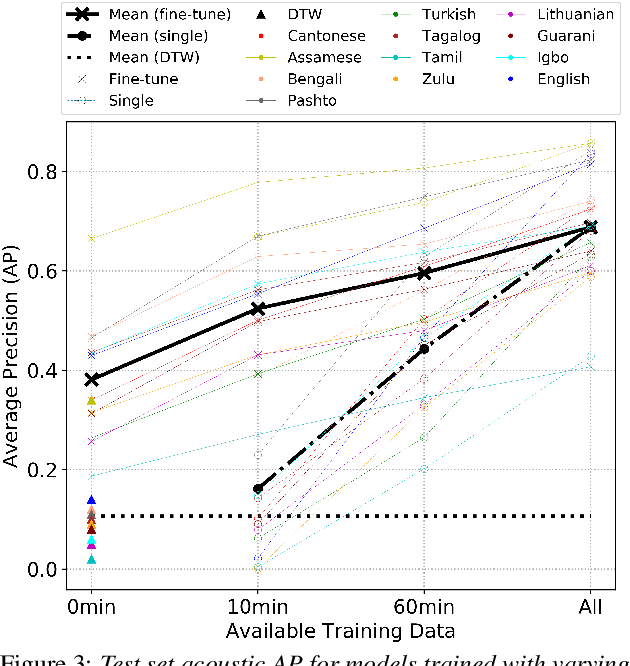
Acoustic word embeddings (AWEs) are vector representations of spoken word segments. AWEs can be learned jointly with embeddings of character sequences, to generate phonetically meaningful embeddings of written words, or acoustically grounded word embeddings (AGWEs). Such embeddings have been used to improve speech retrieval, recognition, and spoken term discovery. In this work, we extend this idea to multiple low-resource languages. We jointly train an AWE model and an AGWE model, using phonetically transcribed data from multiple languages. The pre-trained models can then be used for unseen zero-resource languages, or fine-tuned on data from low-resource languages. We also investigate distinctive features, as an alternative to phone labels, to better share cross-lingual information. We test our models on word discrimination tasks for twelve languages. When trained on eleven languages and tested on the remaining unseen language, our model outperforms traditional unsupervised approaches like dynamic time warping. After fine-tuning the pre-trained models on one hour or even ten minutes of data from a new language, performance is typically much better than training on only the target-language data. We also find that phonetic supervision improves performance over character sequences, and that distinctive feature supervision is helpful in handling unseen phones in the target language.
Acoustically Grounded Word Embeddings for Improved Acoustics-to-Word Speech Recognition
Mar 29, 2019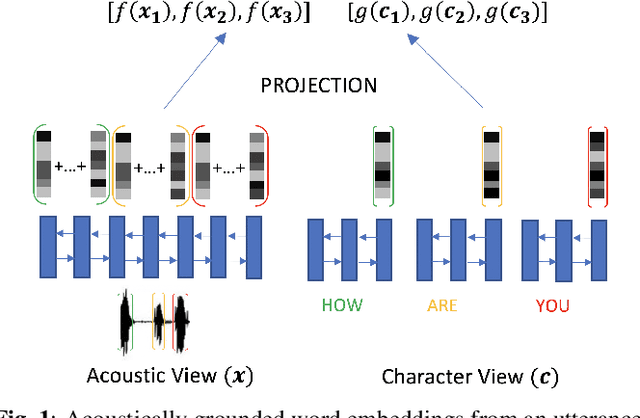

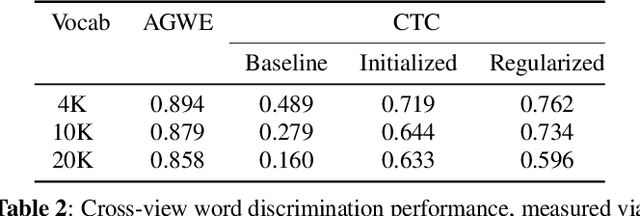
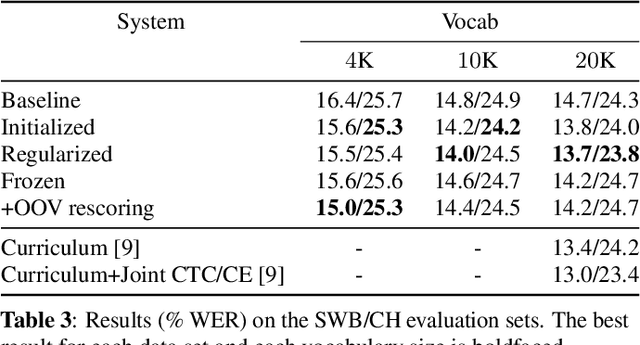
Direct acoustics-to-word (A2W) systems for end-to-end automatic speech recognition are simpler to train, and more efficient to decode with, than sub-word systems. However, A2W systems can have difficulties at training time when data is limited, and at decoding time when recognizing words outside the training vocabulary. To address these shortcomings, we investigate the use of recently proposed acoustic and acoustically grounded word embedding techniques in A2W systems. The idea is based on treating the final pre-softmax weight matrix of an AWE recognizer as a matrix of word embedding vectors, and using an externally trained set of word embeddings to improve the quality of this matrix. In particular we introduce two ideas: (1) Enforcing similarity at training time between the external embeddings and the recognizer weights, and (2) using the word embeddings at test time for predicting out-of-vocabulary words. Our word embedding model is acoustically grounded, that is it is learned jointly with acoustic embeddings so as to encode the words' acoustic-phonetic content; and it is parametric, so that it can embed any arbitrary (potentially out-of-vocabulary) sequence of characters. We find that both techniques improve the performance of an A2W recognizer on conversational telephone speech.
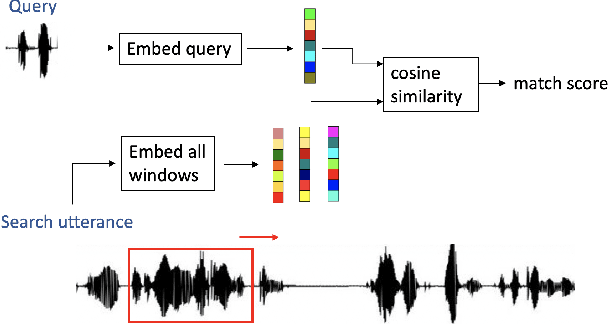
Query-by-Example Search with Discriminative Neural Acoustic Word Embeddings
Jun 12, 2017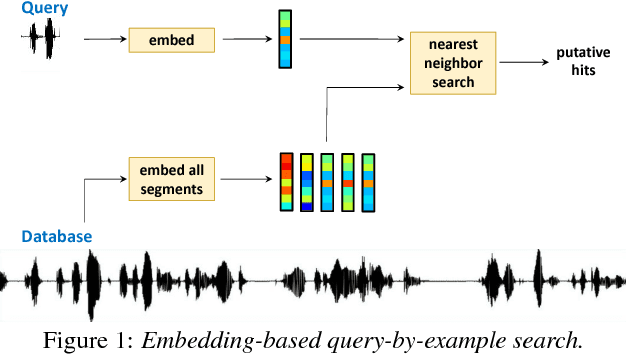
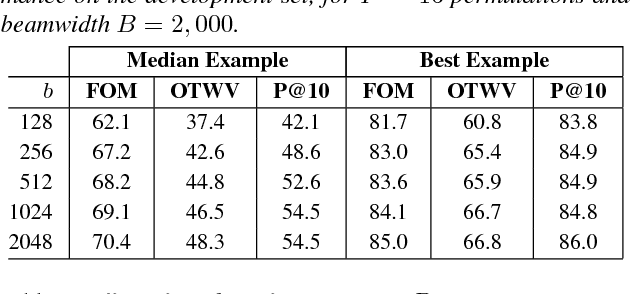
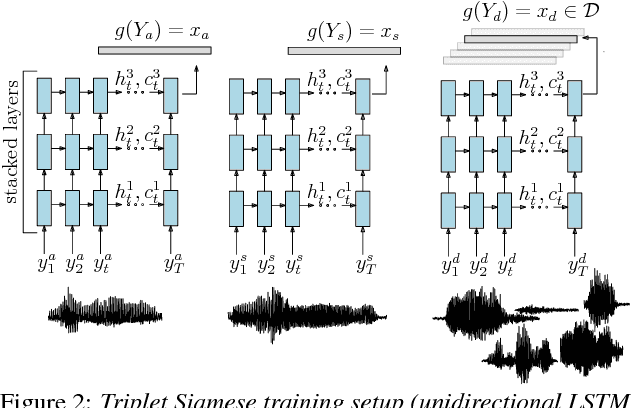
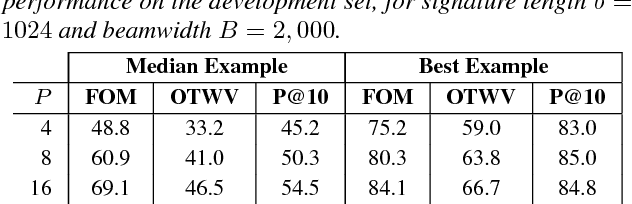
Query-by-example search often uses dynamic time warping (DTW) for comparing queries and proposed matching segments. Recent work has shown that comparing speech segments by representing them as fixed-dimensional vectors --- acoustic word embeddings --- and measuring their vector distance (e.g., cosine distance) can discriminate between words more accurately than DTW-based approaches. We consider an approach to query-by-example search that embeds both the query and database segments according to a neural model, followed by nearest-neighbor search to find the matching segments. Earlier work on embedding-based query-by-example, using template-based acoustic word embeddings, achieved competitive performance. We find that our embeddings, based on recurrent neural networks trained to optimize word discrimination, achieve substantial improvements in performance and run-time efficiency over the previous approaches.
Visually grounded learning of keyword prediction from untranscribed speech
May 25, 2017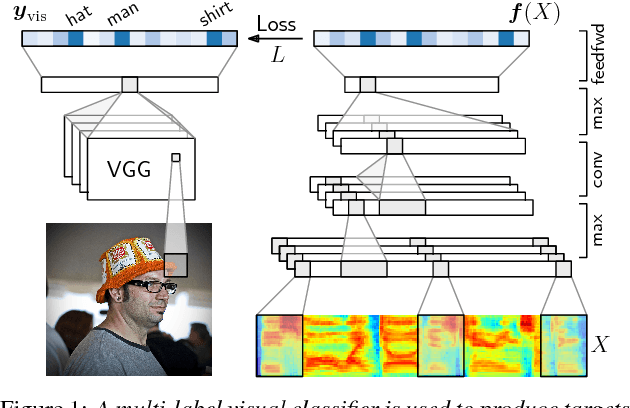
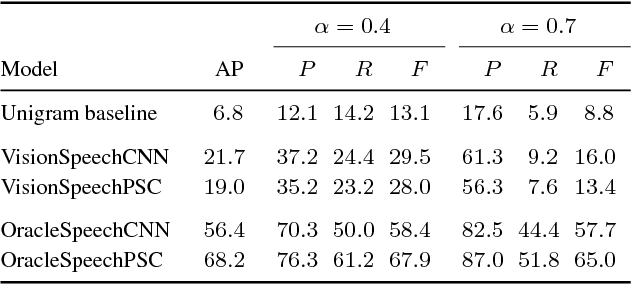
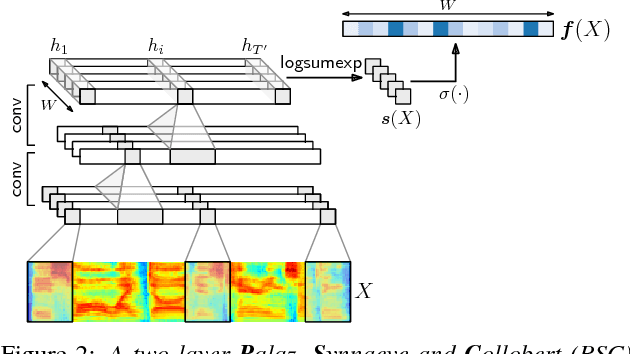

During language acquisition, infants have the benefit of visual cues to ground spoken language. Robots similarly have access to audio and visual sensors. Recent work has shown that images and spoken captions can be mapped into a meaningful common space, allowing images to be retrieved using speech and vice versa. In this setting of images paired with untranscribed spoken captions, we consider whether computer vision systems can be used to obtain textual labels for the speech. Concretely, we use an image-to-words multi-label visual classifier to tag images with soft textual labels, and then train a neural network to map from the speech to these soft targets. We show that the resulting speech system is able to predict which words occur in an utterance---acting as a spoken bag-of-words classifier---without seeing any parallel speech and text. We find that the model often confuses semantically related words, e.g. "man" and "person", making it even more effective as a semantic keyword spotter.
Discriminative Acoustic Word Embeddings: Recurrent Neural Network-Based Approaches
Nov 08, 2016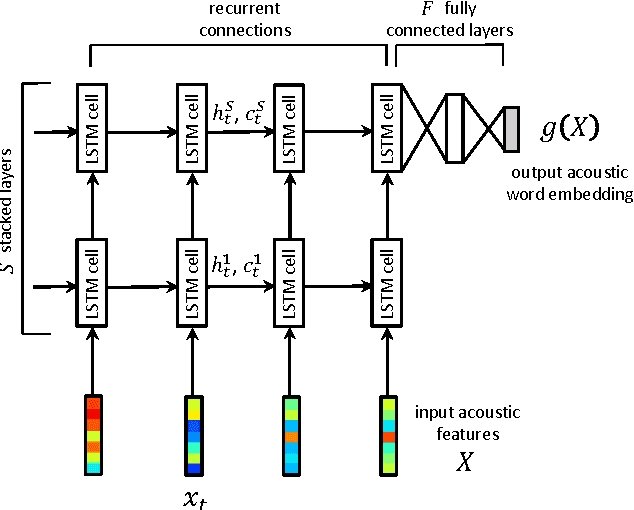
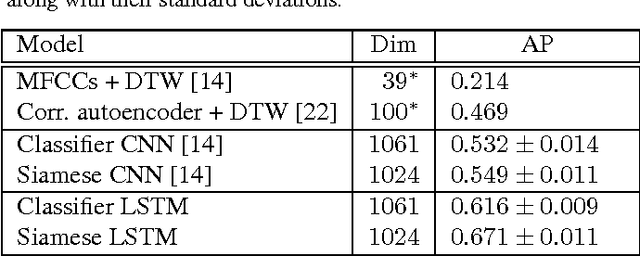
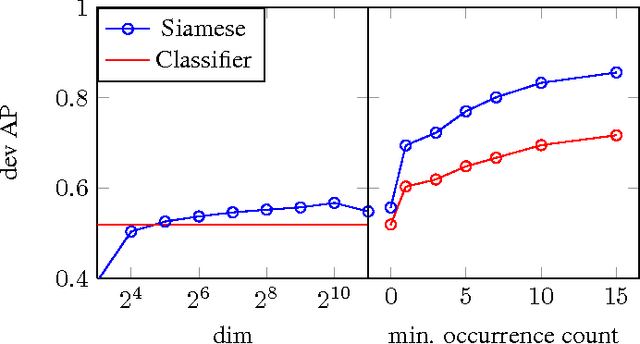
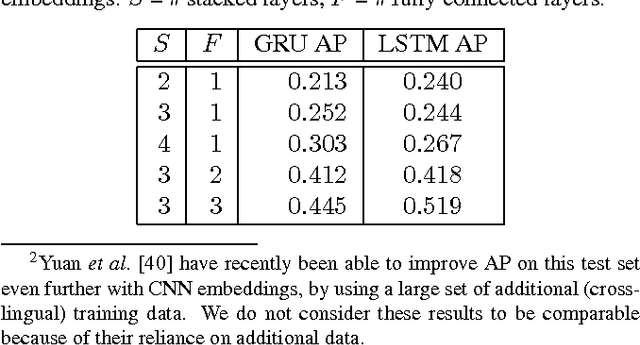
Acoustic word embeddings --- fixed-dimensional vector representations of variable-length spoken word segments --- have begun to be considered for tasks such as speech recognition and query-by-example search. Such embeddings can be learned discriminatively so that they are similar for speech segments corresponding to the same word, while being dissimilar for segments corresponding to different words. Recent work has found that acoustic word embeddings can outperform dynamic time warping on query-by-example search and related word discrimination tasks. However, the space of embedding models and training approaches is still relatively unexplored. In this paper we present new discriminative embedding models based on recurrent neural networks (RNNs). We consider training losses that have been successful in prior work, in particular a cross entropy loss for word classification and a contrastive loss that explicitly aims to separate same-word and different-word pairs in a "Siamese network" training setting. We find that both classifier-based and Siamese RNN embeddings improve over previously reported results on a word discrimination task, with Siamese RNNs outperforming classification models. In addition, we present analyses of the learned embeddings and the effects of variables such as dimensionality and network structure.