 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscriminative Acoustic Word Embeddings: Recurrent Neural Network-Based Approaches
Paper and Code
Nov 08, 2016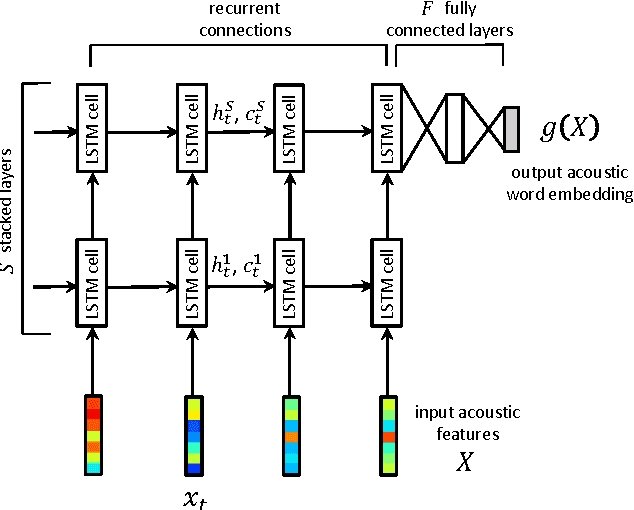
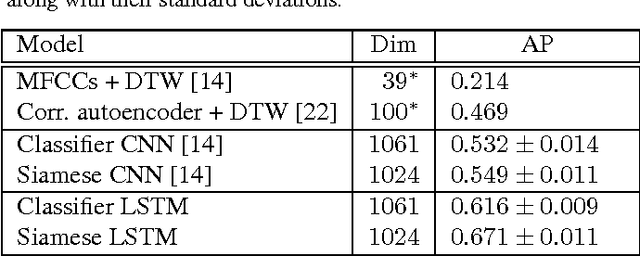
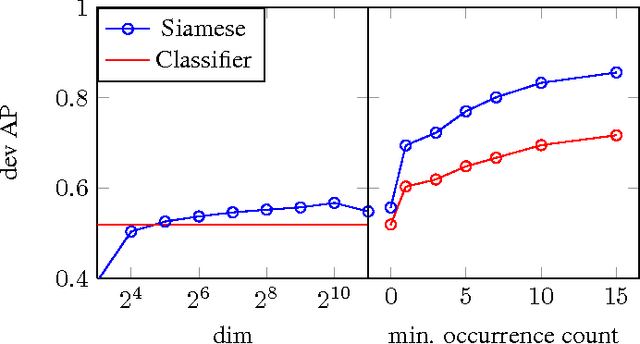
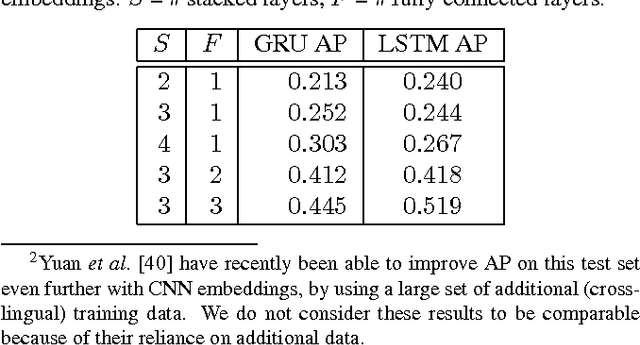
Acoustic word embeddings --- fixed-dimensional vector representations of variable-length spoken word segments --- have begun to be considered for tasks such as speech recognition and query-by-example search. Such embeddings can be learned discriminatively so that they are similar for speech segments corresponding to the same word, while being dissimilar for segments corresponding to different words. Recent work has found that acoustic word embeddings can outperform dynamic time warping on query-by-example search and related word discrimination tasks. However, the space of embedding models and training approaches is still relatively unexplored. In this paper we present new discriminative embedding models based on recurrent neural networks (RNNs). We consider training losses that have been successful in prior work, in particular a cross entropy loss for word classification and a contrastive loss that explicitly aims to separate same-word and different-word pairs in a "Siamese network" training setting. We find that both classifier-based and Siamese RNN embeddings improve over previously reported results on a word discrimination task, with Siamese RNNs outperforming classification models. In addition, we present analyses of the learned embeddings and the effects of variables such as dimensionality and network structure.