 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAcoustic span embeddings for multilingual query-by-example search
Paper and Code
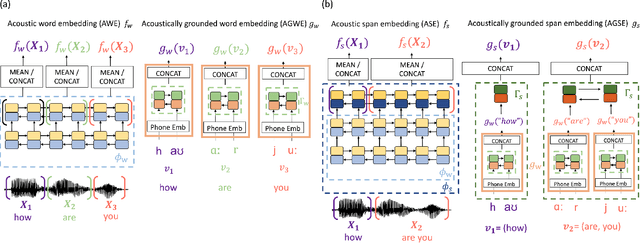
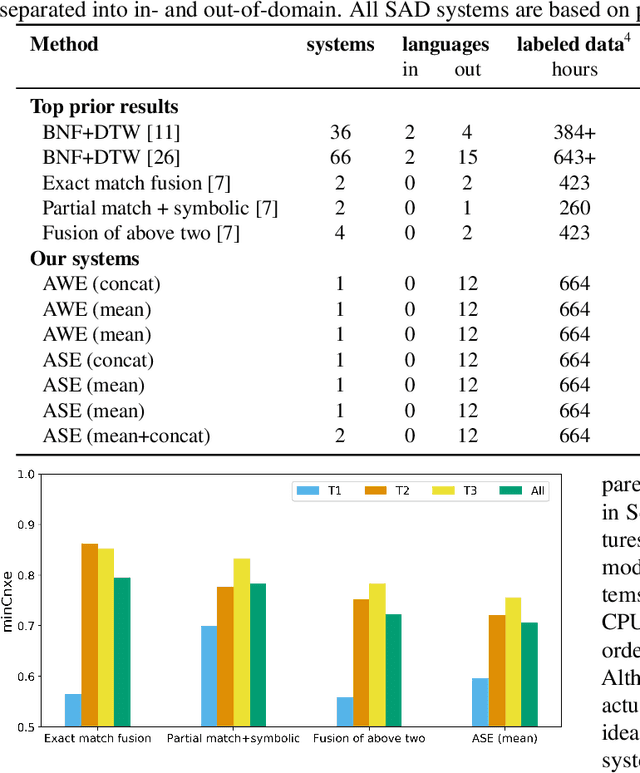
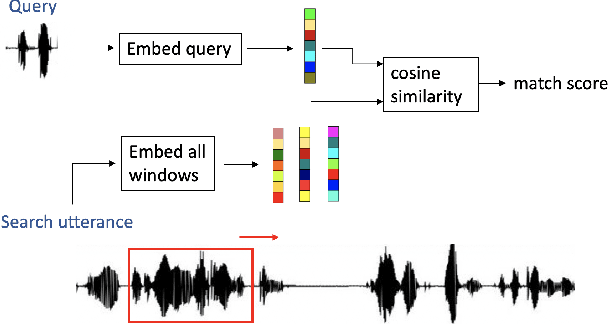

Query-by-example (QbE) speech search is the task of matching spoken queries to utterances within a search collection. In low- or zero-resource settings, QbE search is often addressed with approaches based on dynamic time warping (DTW). Recent work has found that methods based on acoustic word embeddings (AWEs) can improve both performance and search speed. However, prior work on AWE-based QbE has primarily focused on English data and with single-word queries. In this work, we generalize AWE training to spans of words, producing acoustic span embeddings (ASE), and explore the application of ASE to QbE with arbitrary-length queries in multiple unseen languages. We consider the commonly used setting where we have access to labeled data in other languages (in our case, several low-resource languages) distinct from the unseen test languages. We evaluate our approach on the QUESST 2015 QbE tasks, finding that multilingual ASE-based search is much faster than DTW-based search and outperforms the best previously published results on this task.