 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAcoustically Grounded Word Embeddings for Improved Acoustics-to-Word Speech Recognition
Paper and Code
Mar 29, 2019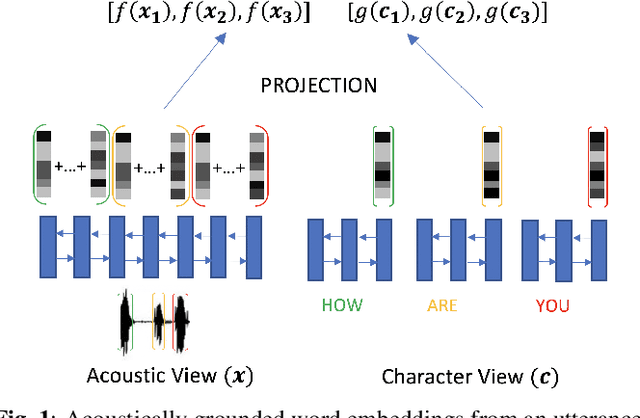

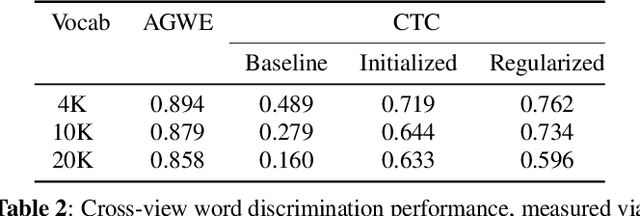
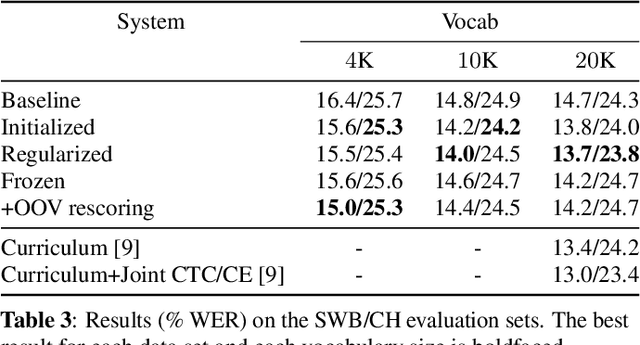
Direct acoustics-to-word (A2W) systems for end-to-end automatic speech recognition are simpler to train, and more efficient to decode with, than sub-word systems. However, A2W systems can have difficulties at training time when data is limited, and at decoding time when recognizing words outside the training vocabulary. To address these shortcomings, we investigate the use of recently proposed acoustic and acoustically grounded word embedding techniques in A2W systems. The idea is based on treating the final pre-softmax weight matrix of an AWE recognizer as a matrix of word embedding vectors, and using an externally trained set of word embeddings to improve the quality of this matrix. In particular we introduce two ideas: (1) Enforcing similarity at training time between the external embeddings and the recognizer weights, and (2) using the word embeddings at test time for predicting out-of-vocabulary words. Our word embedding model is acoustically grounded, that is it is learned jointly with acoustic embeddings so as to encode the words' acoustic-phonetic content; and it is parametric, so that it can embed any arbitrary (potentially out-of-vocabulary) sequence of characters. We find that both techniques improve the performance of an A2W recognizer on conversational telephone speech.