 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvent Outcome Prediction using Sentiment Analysis and Crowd Wisdom in Microblog Feeds
Dec 11, 2019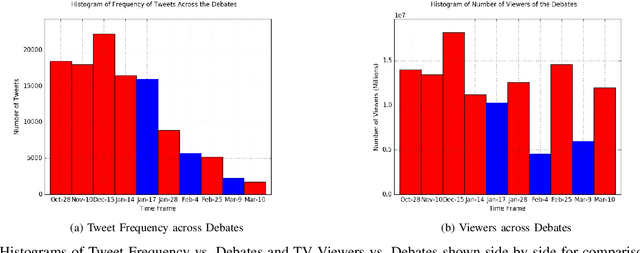
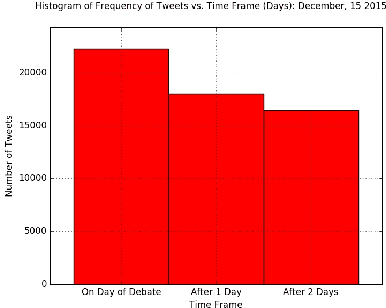
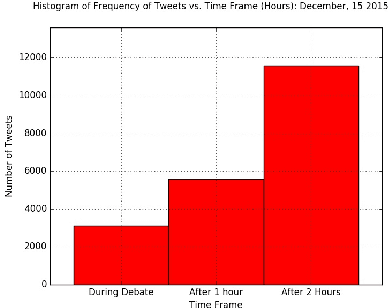
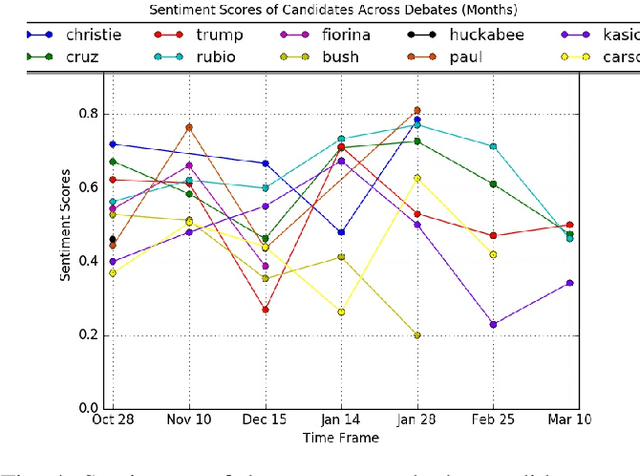
Sentiment Analysis of microblog feeds has attracted considerable interest in recent times. Most of the current work focuses on tweet sentiment classification. But not much work has been done to explore how reliable the opinions of the mass (crowd wisdom) in social network microblogs such as twitter are in predicting outcomes of certain events such as election debates. In this work, we investigate whether crowd wisdom is useful in predicting such outcomes and whether their opinions are influenced by the experts in the field. We work in the domain of multi-label classification to perform sentiment classification of tweets and obtain the opinion of the crowd. This learnt sentiment is then used to predict outcomes of events such as: US Presidential Debate winners, Grammy Award winners, Super Bowl Winners. We find that in most of the cases, the wisdom of the crowd does indeed match with that of the experts, and in cases where they don't (particularly in the case of debates), we see that the crowd's opinion is actually influenced by that of the experts.
Communication-Free Parallel Supervised Topic Models
Aug 10, 2017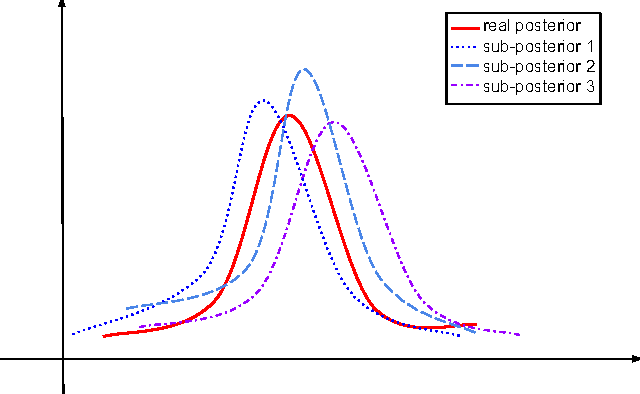
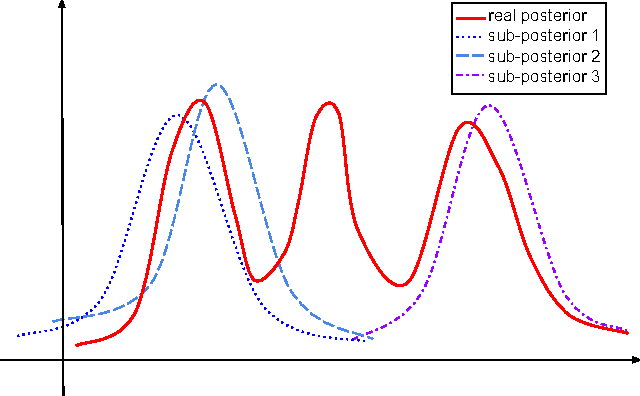


Embarrassingly (communication-free) parallel Markov chain Monte Carlo (MCMC) methods are commonly used in learning graphical models. However, MCMC cannot be directly applied in learning topic models because of the quasi-ergodicity problem caused by multimodal distribution of topics. In this paper, we develop an embarrassingly parallel MCMC algorithm for sLDA. Our algorithm works by switching the order of sampled topics combination and labeling variable prediction in sLDA, in which it overcomes the quasi-ergodicity problem because high-dimension topics that follow a multimodal distribution are projected into one-dimension document labels that follow a unimodal distribution. Our empirical experiments confirm that the out-of-sample prediction performance using our embarrassingly parallel algorithm is comparable to non-parallel sLDA while the computation time is significantly reduced.
Joint Embedding of Hierarchical Categories and Entities for Concept Categorization and Dataless Classification
Jul 27, 2016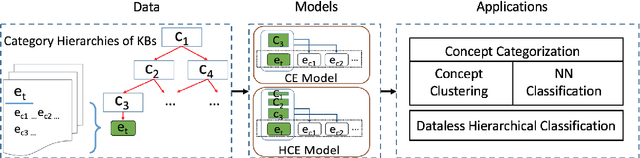
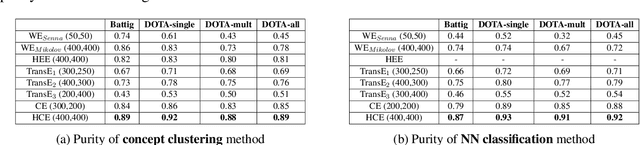
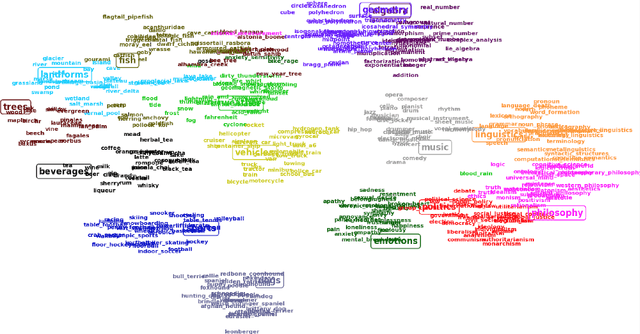
Due to the lack of structured knowledge applied in learning distributed representation of cate- gories, existing work cannot incorporate category hierarchies into entity information. We propose a framework that embeds entities and categories into a semantic space by integrating structured knowledge and taxonomy hierarchy from large knowledge bases. The framework allows to com- pute meaningful semantic relatedness between entities and categories. Our framework can han- dle both single-word concepts and multiple-word concepts with superior performance on concept categorization and yield state of the art results on dataless hierarchical classification.
Joint Embeddings of Hierarchical Categories and Entities
May 13, 2016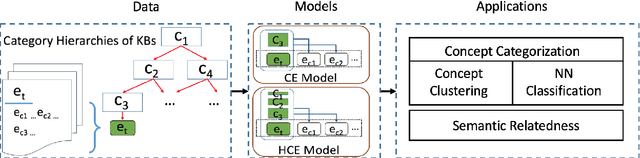
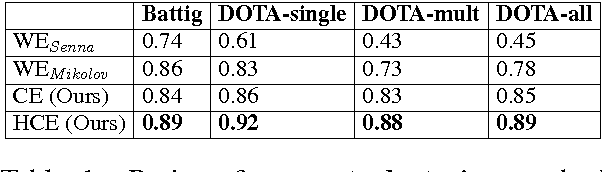
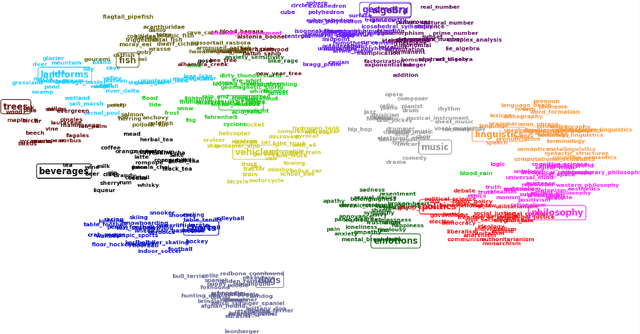
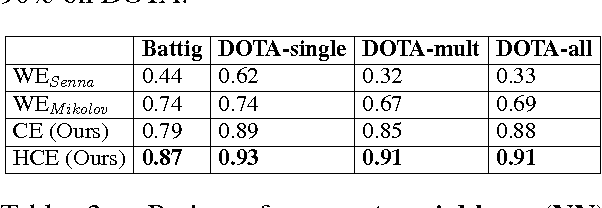
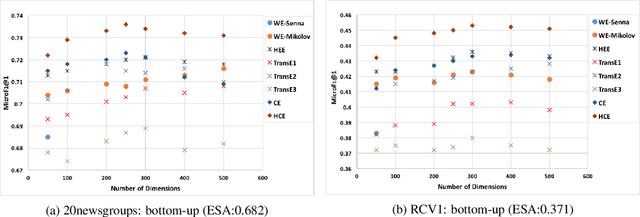
Due to the lack of structured knowledge applied in learning distributed representation of categories, existing work cannot incorporate category hierarchies into entity information.~We propose a framework that embeds entities and categories into a semantic space by integrating structured knowledge and taxonomy hierarchy from large knowledge bases. The framework allows to compute meaningful semantic relatedness between entities and categories.~Compared with the previous state of the art, our framework can handle both single-word concepts and multiple-word concepts with superior performance in concept categorization and semantic relatedness.