 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Dynamic Strategy Planning for Efficient Question Answering with Large Language Models
Oct 30, 2024
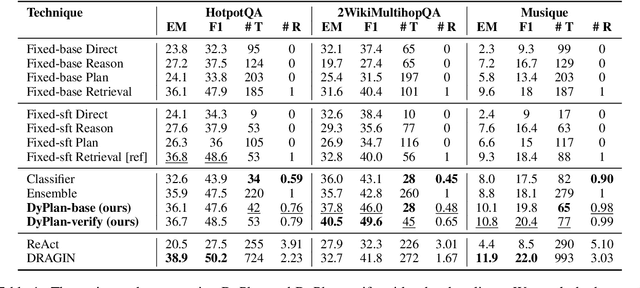
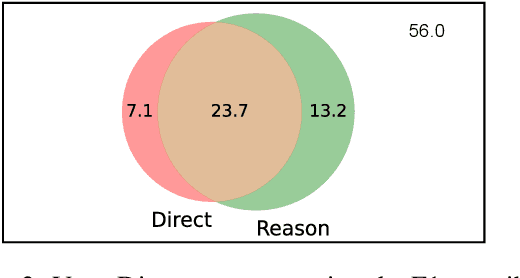
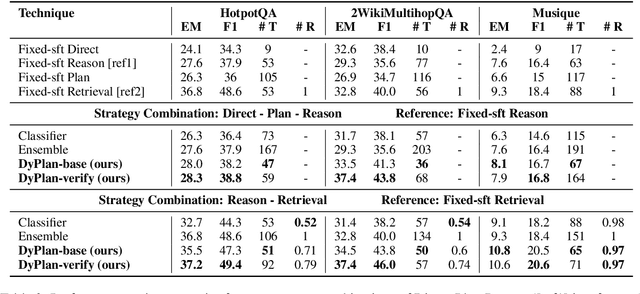
Research has shown the effectiveness of reasoning (e.g., Chain-of-Thought), planning (e.g., SelfAsk), and retrieval augmented generation strategies to improve the performance of Large Language Models (LLMs) on various tasks, such as question answering. However, using a single fixed strategy to answer different kinds of questions is suboptimal in performance and inefficient in terms of generated output tokens and performed retrievals. In our work, we propose a novel technique DyPlan, to induce a dynamic strategy selection process in LLMs, to improve performance and reduce costs in question-answering. DyPlan incorporates an initial decision step to select the most suitable strategy conditioned on the input question and guides the LLM's response generation accordingly. We extend DyPlan to DyPlan-verify, adding an internal verification and correction process to further enrich the generated answer. Experiments on three prominent multi-hop question answering (MHQA) datasets reveal how DyPlan can improve model performance by 7-13% while reducing the cost by 11-32% relative to the best baseline model.
Improving Model Factuality with Fine-grained Critique-based Evaluator
Oct 24, 2024Factuality evaluation aims to detect factual errors produced by language models (LMs) and hence guide the development of more factual models. Towards this goal, we train a factuality evaluator, FenCE, that provides LM generators with claim-level factuality feedback. We conduct data augmentation on a combination of public judgment datasets to train FenCE to (1) generate textual critiques along with scores and (2) make claim-level judgment based on diverse source documents obtained by various tools. We then present a framework that leverages FenCE to improve the factuality of LM generators by constructing training data. Specifically, we generate a set of candidate responses, leverage FenCE to revise and score each response without introducing lesser-known facts, and train the generator by preferring highly scored revised responses. Experiments show that our data augmentation methods improve the evaluator's accuracy by 2.9% on LLM-AggreFact. With FenCE, we improve Llama3-8B-chat's factuality rate by 14.45% on FActScore, outperforming state-of-the-art factuality finetuning methods by 6.96%.
Utilizing Lexical Similarity between Related, Low-resource Languages for Pivot-based SMT
Oct 04, 2017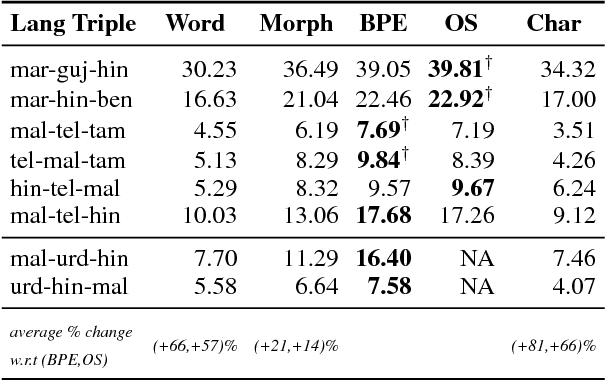

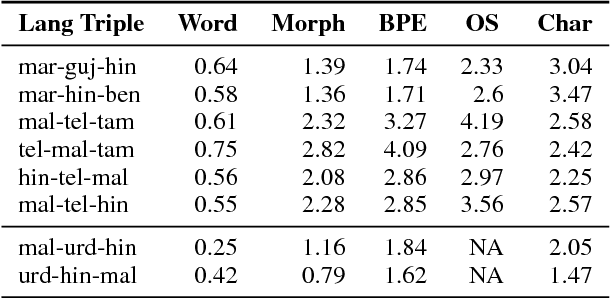
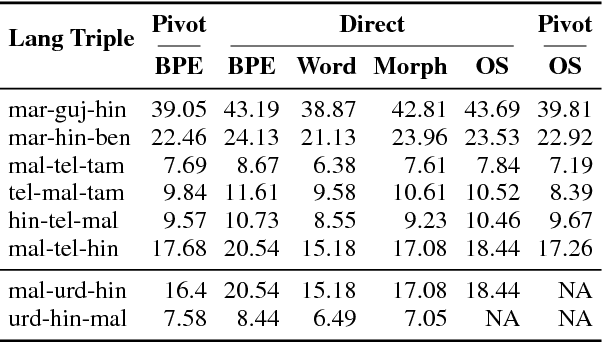
We investigate pivot-based translation between related languages in a low resource, phrase-based SMT setting. We show that a subword-level pivot-based SMT model using a related pivot language is substantially better than word and morpheme-level pivot models. It is also highly competitive with the best direct translation model, which is encouraging as no direct source-target training corpus is used. We also show that combining multiple related language pivot models can rival a direct translation model. Thus, the use of subwords as translation units coupled with multiple related pivot languages can compensate for the lack of a direct parallel corpus.