 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Strategy Planning for Efficient Question Answering with Large Language Models
Paper and Code

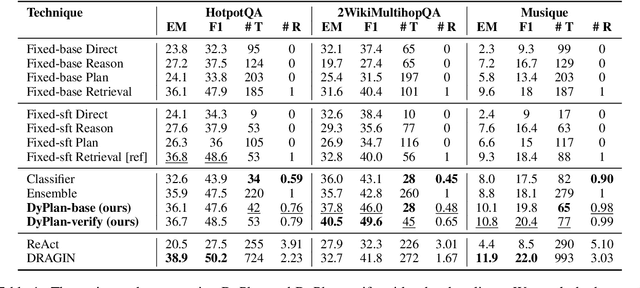
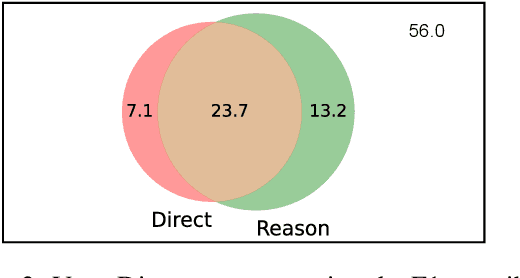
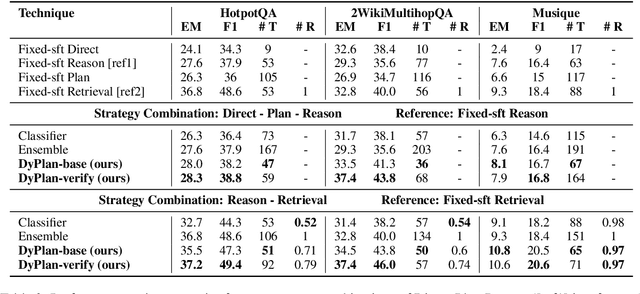
Research has shown the effectiveness of reasoning (e.g., Chain-of-Thought), planning (e.g., SelfAsk), and retrieval augmented generation strategies to improve the performance of Large Language Models (LLMs) on various tasks, such as question answering. However, using a single fixed strategy to answer different kinds of questions is suboptimal in performance and inefficient in terms of generated output tokens and performed retrievals. In our work, we propose a novel technique DyPlan, to induce a dynamic strategy selection process in LLMs, to improve performance and reduce costs in question-answering. DyPlan incorporates an initial decision step to select the most suitable strategy conditioned on the input question and guides the LLM's response generation accordingly. We extend DyPlan to DyPlan-verify, adding an internal verification and correction process to further enrich the generated answer. Experiments on three prominent multi-hop question answering (MHQA) datasets reveal how DyPlan can improve model performance by 7-13% while reducing the cost by 11-32% relative to the best baseline model.