 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Strategy Planning for Efficient Question Answering with Large Language Models
Oct 30, 2024
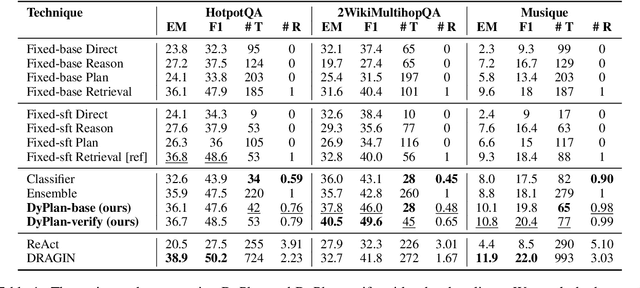
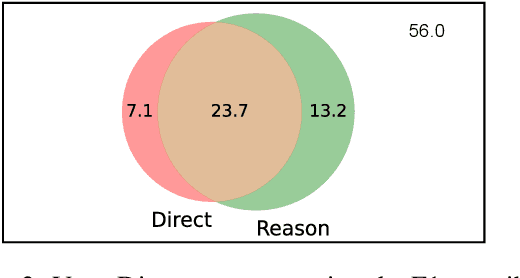
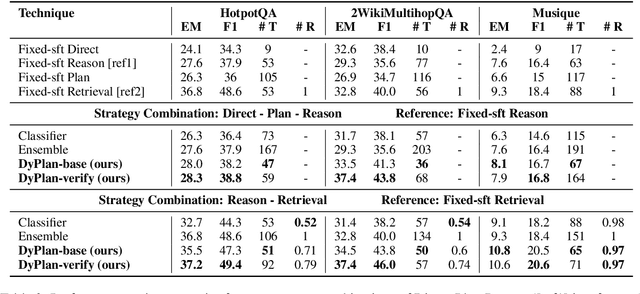
Research has shown the effectiveness of reasoning (e.g., Chain-of-Thought), planning (e.g., SelfAsk), and retrieval augmented generation strategies to improve the performance of Large Language Models (LLMs) on various tasks, such as question answering. However, using a single fixed strategy to answer different kinds of questions is suboptimal in performance and inefficient in terms of generated output tokens and performed retrievals. In our work, we propose a novel technique DyPlan, to induce a dynamic strategy selection process in LLMs, to improve performance and reduce costs in question-answering. DyPlan incorporates an initial decision step to select the most suitable strategy conditioned on the input question and guides the LLM's response generation accordingly. We extend DyPlan to DyPlan-verify, adding an internal verification and correction process to further enrich the generated answer. Experiments on three prominent multi-hop question answering (MHQA) datasets reveal how DyPlan can improve model performance by 7-13% while reducing the cost by 11-32% relative to the best baseline model.
AutoNLU: Detecting, root-causing, and fixing NLU model errors
Oct 12, 2021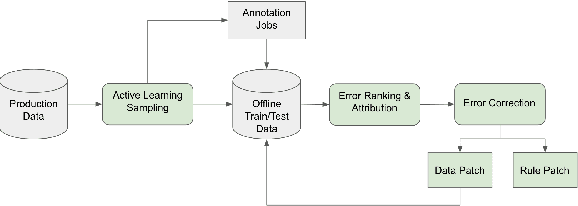

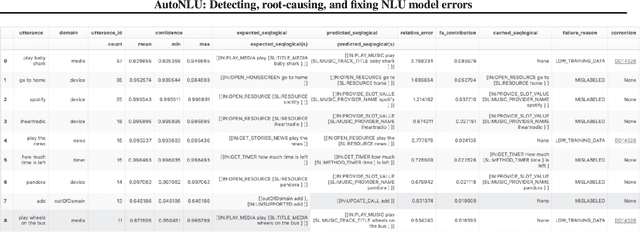

Improving the quality of Natural Language Understanding (NLU) models, and more specifically, task-oriented semantic parsing models, in production is a cumbersome task. In this work, we present a system called AutoNLU, which we designed to scale the NLU quality improvement process. It adds automation to three key steps: detection, attribution, and correction of model errors, i.e., bugs. We detected four times more failed tasks than with random sampling, finding that even a simple active learning sampling method on an uncalibrated model is surprisingly effective for this purpose. The AutoNLU tool empowered linguists to fix ten times more semantic parsing bugs than with prior manual processes, auto-correcting 65% of all identified bugs.
RETRONLU: Retrieval Augmented Task-Oriented Semantic Parsing
Sep 21, 2021
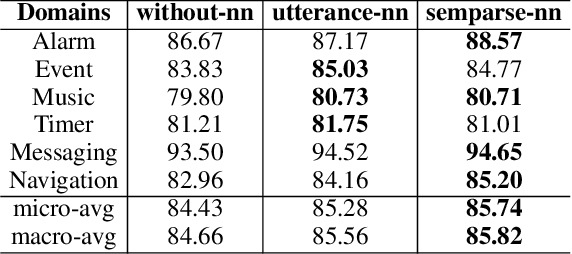
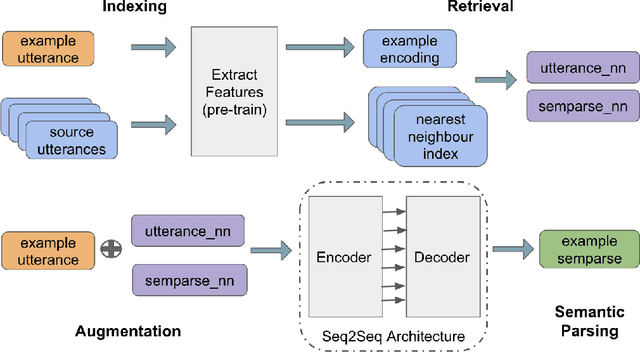
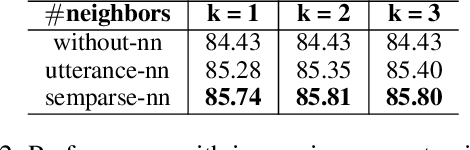
While large pre-trained language models accumulate a lot of knowledge in their parameters, it has been demonstrated that augmenting it with non-parametric retrieval-based memory has a number of benefits from accuracy improvements to data efficiency for knowledge-focused tasks, such as question answering. In this paper, we are applying retrieval-based modeling ideas to the problem of multi-domain task-oriented semantic parsing for conversational assistants. Our approach, RetroNLU, extends a sequence-to-sequence model architecture with a retrieval component, used to fetch existing similar examples and provide them as an additional input to the model. In particular, we analyze two settings, where we augment an input with (a) retrieved nearest neighbor utterances (utterance-nn), and (b) ground-truth semantic parses of nearest neighbor utterances (semparse-nn). Our technique outperforms the baseline method by 1.5% absolute macro-F1, especially at the low resource setting, matching the baseline model accuracy with only 40% of the data. Furthermore, we analyze the nearest neighbor retrieval component's quality, model sensitivity and break down the performance for semantic parses of different utterance complexity.