 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRETRONLU: Retrieval Augmented Task-Oriented Semantic Parsing
Paper and Code
Sep 21, 2021
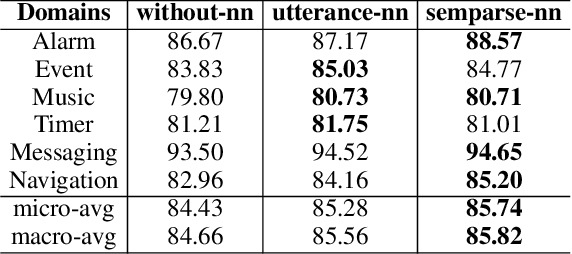
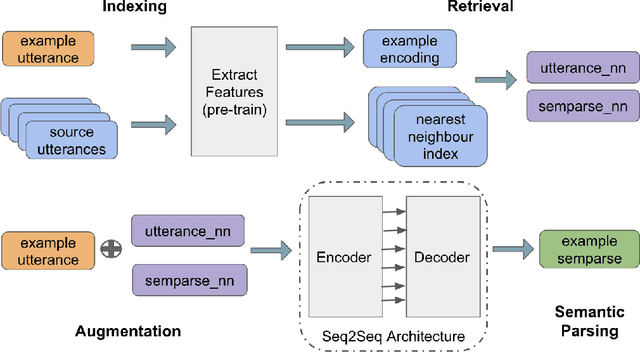
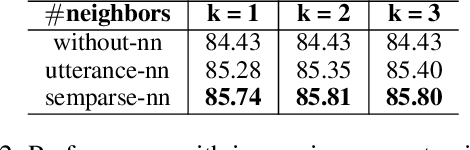
While large pre-trained language models accumulate a lot of knowledge in their parameters, it has been demonstrated that augmenting it with non-parametric retrieval-based memory has a number of benefits from accuracy improvements to data efficiency for knowledge-focused tasks, such as question answering. In this paper, we are applying retrieval-based modeling ideas to the problem of multi-domain task-oriented semantic parsing for conversational assistants. Our approach, RetroNLU, extends a sequence-to-sequence model architecture with a retrieval component, used to fetch existing similar examples and provide them as an additional input to the model. In particular, we analyze two settings, where we augment an input with (a) retrieved nearest neighbor utterances (utterance-nn), and (b) ground-truth semantic parses of nearest neighbor utterances (semparse-nn). Our technique outperforms the baseline method by 1.5% absolute macro-F1, especially at the low resource setting, matching the baseline model accuracy with only 40% of the data. Furthermore, we analyze the nearest neighbor retrieval component's quality, model sensitivity and break down the performance for semantic parses of different utterance complexity.