 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDividing and Conquering a BlackBox to a Mixture of Interpretable Models: Route, Interpret, Repeat
Jul 12, 2023ML model design either starts with an interpretable model or a Blackbox and explains it post hoc. Blackbox models are flexible but difficult to explain, while interpretable models are inherently explainable. Yet, interpretable models require extensive ML knowledge and tend to be less flexible and underperforming than their Blackbox variants. This paper aims to blur the distinction between a post hoc explanation of a Blackbox and constructing interpretable models. Beginning with a Blackbox, we iteratively carve out a mixture of interpretable experts (MoIE) and a residual network. Each interpretable model specializes in a subset of samples and explains them using First Order Logic (FOL), providing basic reasoning on concepts from the Blackbox. We route the remaining samples through a flexible residual. We repeat the method on the residual network until all the interpretable models explain the desired proportion of data. Our extensive experiments show that our route, interpret, and repeat approach (1) identifies a diverse set of instance-specific concepts with high concept completeness via MoIE without compromising in performance, (2) identifies the relatively ``harder'' samples to explain via residuals, (3) outperforms the interpretable by-design models by significant margins during test-time interventions, and (4) fixes the shortcut learned by the original Blackbox. The code for MoIE is publicly available at: \url{https://github.com/batmanlab/ICML-2023-Route-interpret-repeat}
* appeared as v5 of arXiv:2302.10289 which was replaced in error, which drifted into a different work, accepted in ICML 2023
Route, Interpret, Repeat: Blurring the Line Between Post hoc Explainability and Interpretable Models
Feb 20, 2023



The current approach to ML model design is either to choose a flexible Blackbox model and explain it post hoc or to start with an interpretable model. Blackbox models are flexible but difficult to explain, whereas interpretable models are designed to be explainable. However, developing interpretable models necessitates extensive ML knowledge, and the resulting models tend to be less flexible, offering potentially subpar performance compared to their Blackbox equivalents. This paper aims to blur the distinction between a post hoc explanation of a BlackBox and constructing interpretable models. We propose beginning with a flexible BlackBox model and gradually \emph{carving out} a mixture of interpretable models and a \emph{residual network}. Our design identifies a subset of samples and \emph{routes} them through the interpretable models. The remaining samples are routed through a flexible residual network. We adopt First Order Logic (FOL) as the interpretable model's backbone, which provides basic reasoning on concepts retrieved from the BlackBox model. On the residual network, we repeat the method until the proportion of data explained by the residual network falls below a desired threshold. Our approach offers several advantages. First, the mixture of interpretable and flexible residual networks results in almost no compromise in performance. Second, the route, interpret, and repeat approach yields a highly flexible interpretable model. Our extensive experiment demonstrates the performance of the model on various datasets. We show that by editing the FOL model, we can fix the shortcut learned by the original BlackBox model. Finally, our method provides a framework for a hybrid symbolic-connectionist network that is simple to train and adaptable to many applications.
AutoNLU: Detecting, root-causing, and fixing NLU model errors
Oct 12, 2021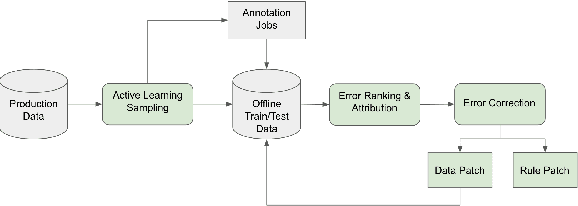


Improving the quality of Natural Language Understanding (NLU) models, and more specifically, task-oriented semantic parsing models, in production is a cumbersome task. In this work, we present a system called AutoNLU, which we designed to scale the NLU quality improvement process. It adds automation to three key steps: detection, attribution, and correction of model errors, i.e., bugs. We detected four times more failed tasks than with random sampling, finding that even a simple active learning sampling method on an uncalibrated model is surprisingly effective for this purpose. The AutoNLU tool empowered linguists to fix ten times more semantic parsing bugs than with prior manual processes, auto-correcting 65% of all identified bugs.
Conversational Multi-Hop Reasoning with Neural Commonsense Knowledge and Symbolic Logic Rules
Sep 17, 2021



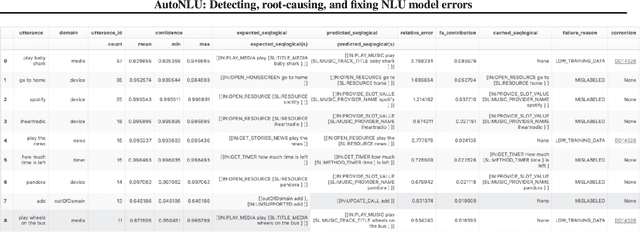
One of the challenges faced by conversational agents is their inability to identify unstated presumptions of their users' commands, a task trivial for humans due to their common sense. In this paper, we propose a zero-shot commonsense reasoning system for conversational agents in an attempt to achieve this. Our reasoner uncovers unstated presumptions from user commands satisfying a general template of if-(state), then-(action), because-(goal). Our reasoner uses a state-of-the-art transformer-based generative commonsense knowledge base (KB) as its source of background knowledge for reasoning. We propose a novel and iterative knowledge query mechanism to extract multi-hop reasoning chains from the neural KB which uses symbolic logic rules to significantly reduce the search space. Similar to any KBs gathered to date, our commonsense KB is prone to missing knowledge. Therefore, we propose to conversationally elicit the missing knowledge from human users with our novel dynamic question generation strategy, which generates and presents contextualized queries to human users. We evaluate the model with a user study with human users that achieves a 35% higher success rate compared to SOTA.
Conversational Neuro-Symbolic Commonsense Reasoning
Jun 19, 2020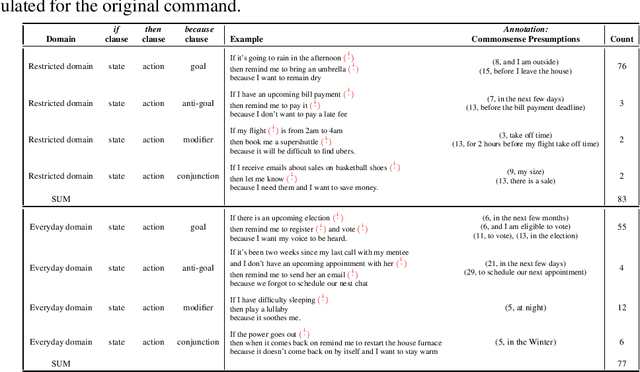
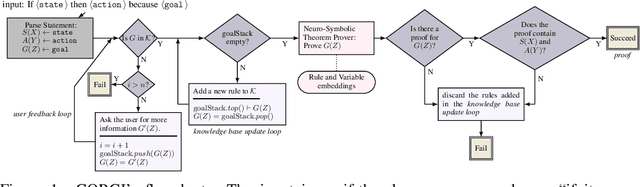
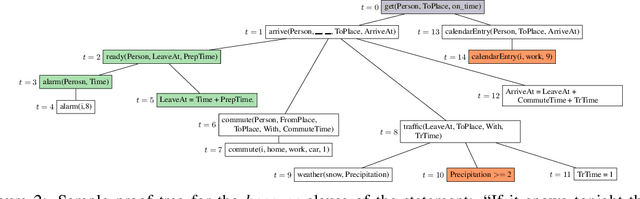

One aspect of human commonsense reasoning is the ability to make presumptions about daily experiences, activities and social interactions with others. We propose a new commonsense reasoning benchmark where the task is to uncover commonsense presumptions implied by imprecisely stated natural language commands in the form of if-then-because statements. For example, in the command "If it snows at night then wake me up early because I don't want to be late for work" the speaker relies on commonsense reasoning of the listener to infer the implicit presumption that it must snow enough to cause traffic slowdowns. Such if-then-because commands are particularly important when users instruct conversational agents. We release a benchmark data set for this task, collected from humans and annotated with commonsense presumptions. We develop a neuro-symbolic theorem prover that extracts multi-hop reasoning chains and apply it to this problem. We further develop an interactive conversational framework that evokes commonsense knowledge from humans for completing reasoning chains.
Memory Augmented Recursive Neural Networks
Nov 08, 2019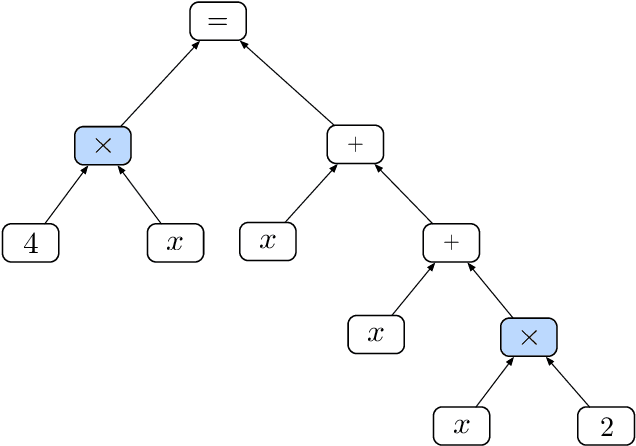
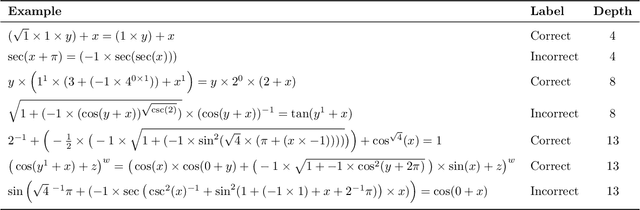

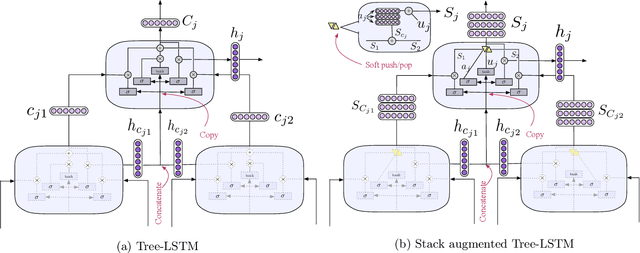
Recursive neural networks have shown an impressive performance for modeling compositional data compared to their recurrent counterparts. Although recursive neural networks are better at capturing long range dependencies, their generalization performance starts to decay as the test data becomes more compositional and potentially deeper than the training data. In this paper, we present memory-augmented recursive neural networks to address this generalization performance loss on deeper data points. We augment Tree-LSTMs with an external memory, namely neural stacks. We define soft push and pop operations for filling and emptying the memory to ensure that the networks remain end-to-end differentiable. In order to assess the effectiveness of the external memory, we evaluate our model on a neural programming task introduced in the literature called equation verification. Our results indicate that augmenting recursive neural networks with external memory consistently improves the generalization performance on deeper data points compared to the state-of-the-art Tree-LSTM by up to 10%.
Look-up and Adapt: A One-shot Semantic Parser
Oct 27, 2019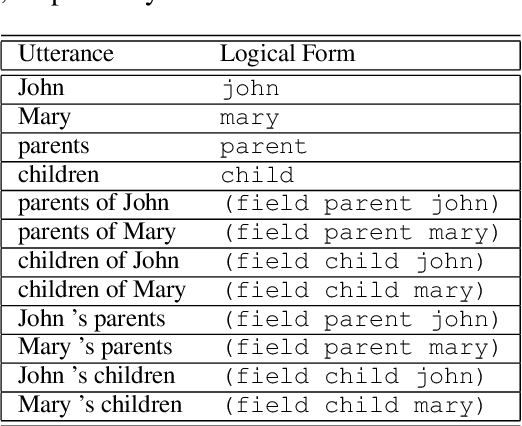
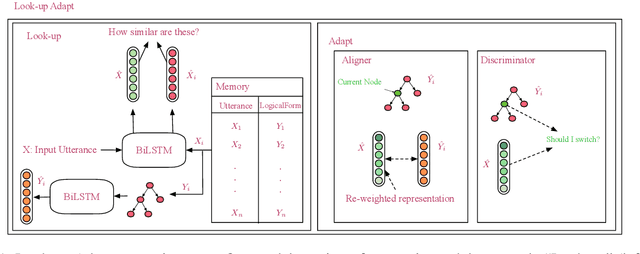
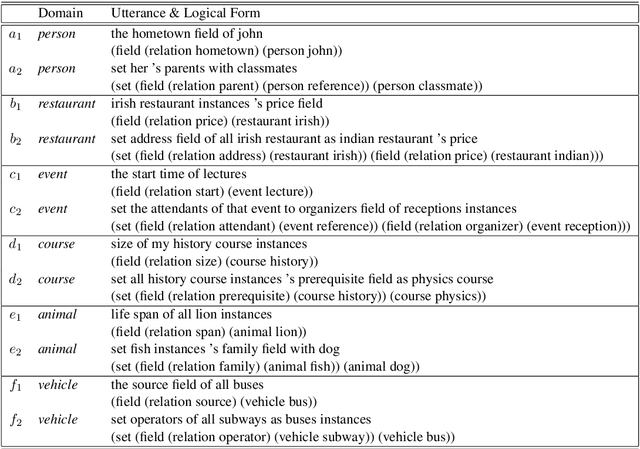
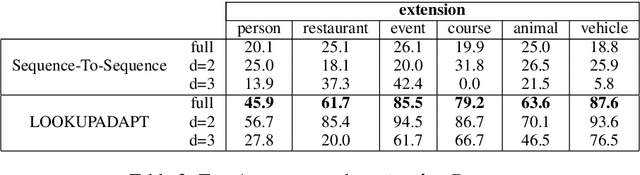
Computing devices have recently become capable of interacting with their end users via natural language. However, they can only operate within a limited "supported" domain of discourse and fail drastically when faced with an out-of-domain utterance, mainly due to the limitations of their semantic parser. In this paper, we propose a semantic parser that generalizes to out-of-domain examples by learning a general strategy for parsing an unseen utterance through adapting the logical forms of seen utterances, instead of learning to generate a logical form from scratch. Our parser maintains a memory consisting of a representative subset of the seen utterances paired with their logical forms. Given an unseen utterance, our parser works by looking up a similar utterance from the memory and adapting its logical form until it fits the unseen utterance. Moreover, we present a data generation strategy for constructing utterance-logical form pairs from different domains. Our results show an improvement of up to 68.8% on one-shot parsing under two different evaluation settings compared to the baselines.
Combining Symbolic Expressions and Black-box Function Evaluations in Neural Programs
Apr 26, 2018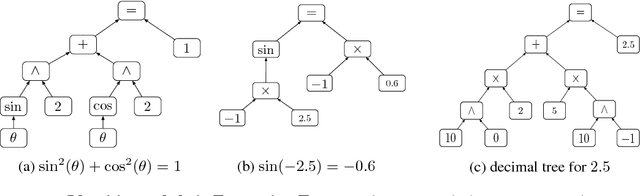
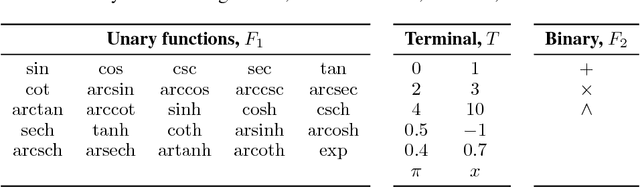
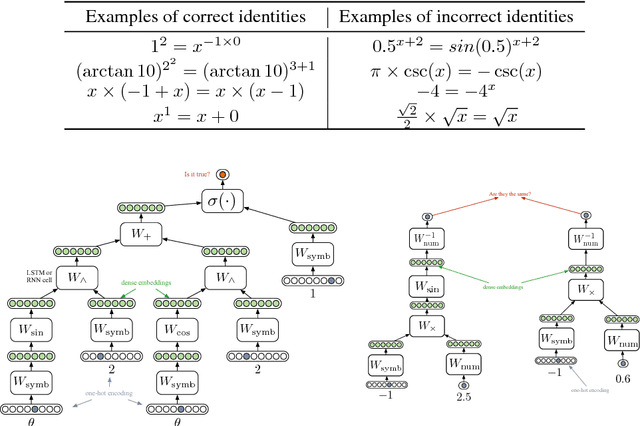
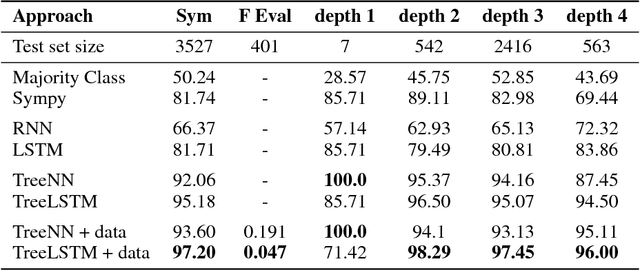
Neural programming involves training neural networks to learn programs, mathematics, or logic from data. Previous works have failed to achieve good generalization performance, especially on problems and programs with high complexity or on large domains. This is because they mostly rely either on black-box function evaluations that do not capture the structure of the program, or on detailed execution traces that are expensive to obtain, and hence the training data has poor coverage of the domain under consideration. We present a novel framework that utilizes black-box function evaluations, in conjunction with symbolic expressions that define relationships between the given functions. We employ tree LSTMs to incorporate the structure of the symbolic expression trees. We use tree encoding for numbers present in function evaluation data, based on their decimal representation. We present an evaluation benchmark for this task to demonstrate our proposed model combines symbolic reasoning and function evaluation in a fruitful manner, obtaining high accuracies in our experiments. Our framework generalizes significantly better to expressions of higher depth and is able to fill partial equations with valid completions.
Spectral Methods for Correlated Topic Models
Nov 13, 2016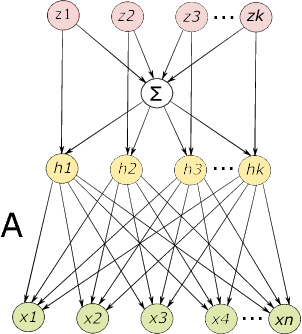

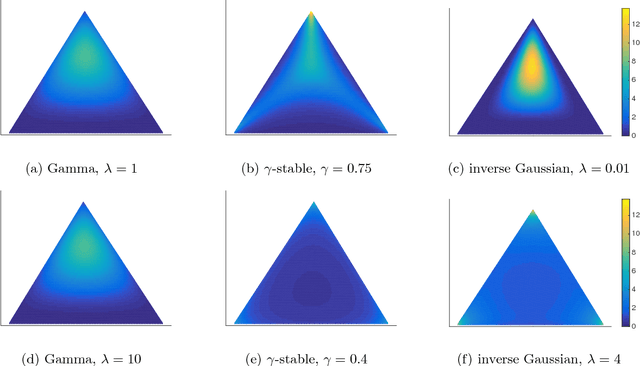

In this paper, we propose guaranteed spectral methods for learning a broad range of topic models, which generalize the popular Latent Dirichlet Allocation (LDA). We overcome the limitation of LDA to incorporate arbitrary topic correlations, by assuming that the hidden topic proportions are drawn from a flexible class of Normalized Infinitely Divisible (NID) distributions. NID distributions are generated through the process of normalizing a family of independent Infinitely Divisible (ID) random variables. The Dirichlet distribution is a special case obtained by normalizing a set of Gamma random variables. We prove that this flexible topic model class can be learned via spectral methods using only moments up to the third order, with (low order) polynomial sample and computational complexity. The proof is based on a key new technique derived here that allows us to diagonalize the moments of the NID distribution through an efficient procedure that requires evaluating only univariate integrals, despite the fact that we are handling high dimensional multivariate moments. In order to assess the performance of our proposed Latent NID topic model, we use two real datasets of articles collected from New York Times and Pubmed. Our experiments yield improved perplexity on both datasets compared with the baseline.