 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemory Augmented Recursive Neural Networks
Nov 08, 2019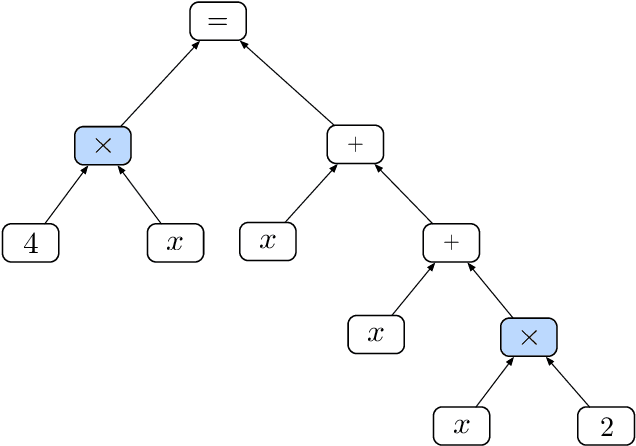

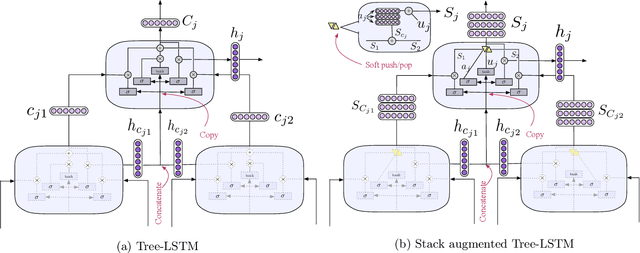
Recursive neural networks have shown an impressive performance for modeling compositional data compared to their recurrent counterparts. Although recursive neural networks are better at capturing long range dependencies, their generalization performance starts to decay as the test data becomes more compositional and potentially deeper than the training data. In this paper, we present memory-augmented recursive neural networks to address this generalization performance loss on deeper data points. We augment Tree-LSTMs with an external memory, namely neural stacks. We define soft push and pop operations for filling and emptying the memory to ensure that the networks remain end-to-end differentiable. In order to assess the effectiveness of the external memory, we evaluate our model on a neural programming task introduced in the literature called equation verification. Our results indicate that augmenting recursive neural networks with external memory consistently improves the generalization performance on deeper data points compared to the state-of-the-art Tree-LSTM by up to 10%.
Look-up and Adapt: A One-shot Semantic Parser
Oct 27, 2019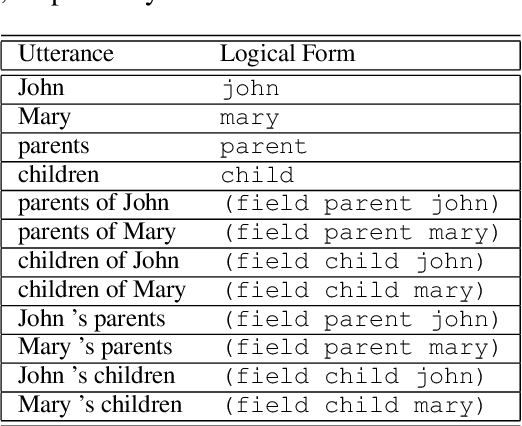
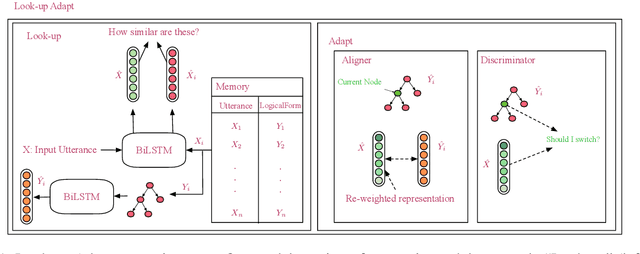
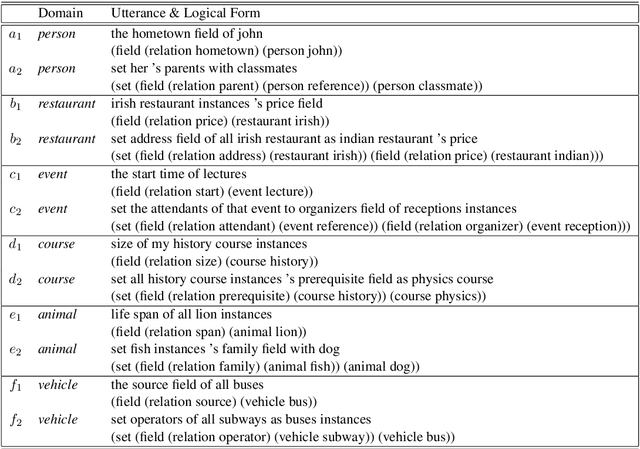
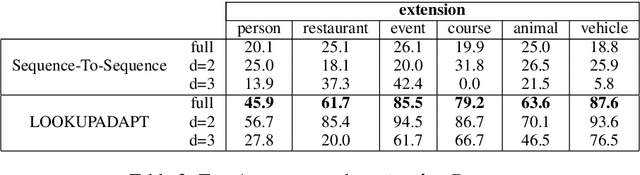
Computing devices have recently become capable of interacting with their end users via natural language. However, they can only operate within a limited "supported" domain of discourse and fail drastically when faced with an out-of-domain utterance, mainly due to the limitations of their semantic parser. In this paper, we propose a semantic parser that generalizes to out-of-domain examples by learning a general strategy for parsing an unseen utterance through adapting the logical forms of seen utterances, instead of learning to generate a logical form from scratch. Our parser maintains a memory consisting of a representative subset of the seen utterances paired with their logical forms. Given an unseen utterance, our parser works by looking up a similar utterance from the memory and adapting its logical form until it fits the unseen utterance. Moreover, we present a data generation strategy for constructing utterance-logical form pairs from different domains. Our results show an improvement of up to 68.8% on one-shot parsing under two different evaluation settings compared to the baselines.