 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRemote Sensing Image Super-resolution and Object Detection: Benchmark and State of the Art
Nov 05, 2021
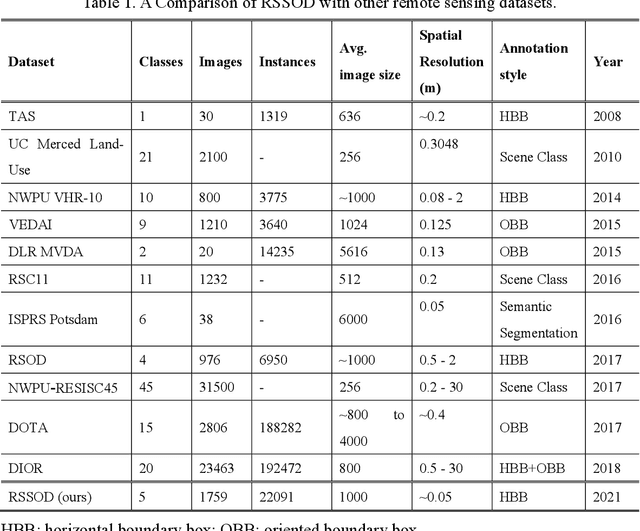
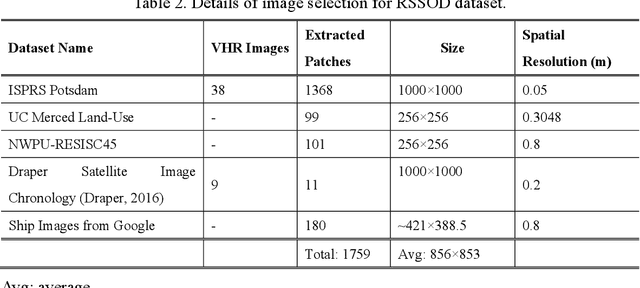
For the past two decades, there have been significant efforts to develop methods for object detection in Remote Sensing (RS) images. In most cases, the datasets for small object detection in remote sensing images are inadequate. Many researchers used scene classification datasets for object detection, which has its limitations; for example, the large-sized objects outnumber the small objects in object categories. Thus, they lack diversity; this further affects the detection performance of small object detectors in RS images. This paper reviews current datasets and object detection methods (deep learning-based) for remote sensing images. We also propose a large-scale, publicly available benchmark Remote Sensing Super-resolution Object Detection (RSSOD) dataset. The RSSOD dataset consists of 1,759 hand-annotated images with 22,091 instances of very high resolution (VHR) images with a spatial resolution of ~0.05 m. There are five classes with varying frequencies of labels per class. The image patches are extracted from satellite images, including real image distortions such as tangential scale distortion and skew distortion. We also propose a novel Multi-class Cyclic super-resolution Generative adversarial network with Residual feature aggregation (MCGR) and auxiliary YOLOv5 detector to benchmark image super-resolution-based object detection and compare with the existing state-of-the-art methods based on image super-resolution (SR). The proposed MCGR achieved state-of-the-art performance for image SR with an improvement of 1.2dB PSNR compared to the current state-of-the-art NLSN method. MCGR achieved best object detection mAPs of 0.758, 0.881, 0.841, and 0.983, respectively, for five-class, four-class, two-class, and single classes, respectively surpassing the performance of the state-of-the-art object detectors YOLOv5, EfficientDet, Faster RCNN, SSD, and RetinaNet.
Medical Image Segmentation Based on Multi-Modal Convolutional Neural Network: Study on Image Fusion Schemes
Nov 02, 2017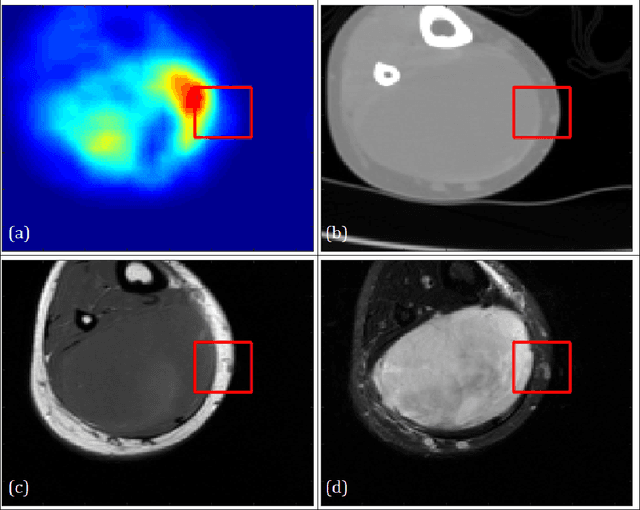
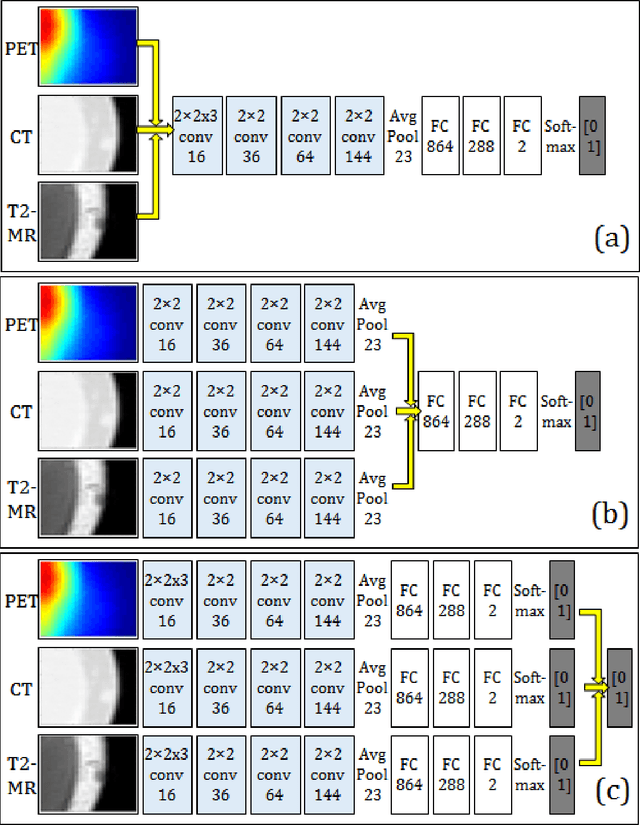
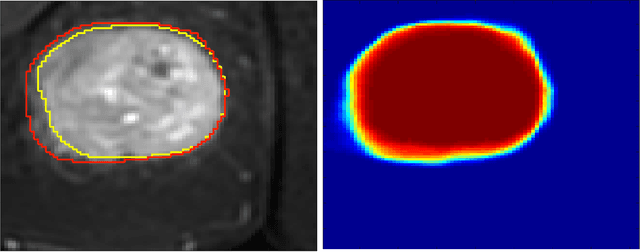
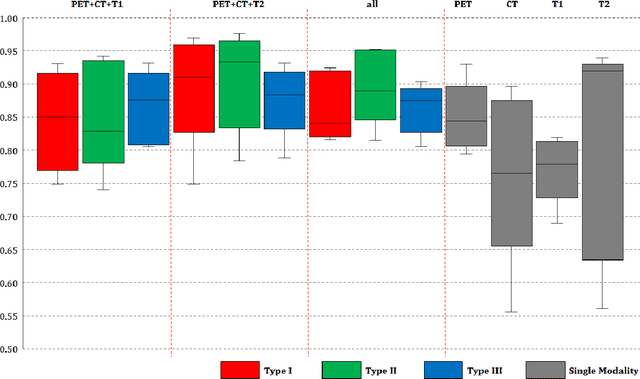
Image analysis using more than one modality (i.e. multi-modal) has been increasingly applied in the field of biomedical imaging. One of the challenges in performing the multimodal analysis is that there exist multiple schemes for fusing the information from different modalities, where such schemes are application-dependent and lack a unified framework to guide their designs. In this work we firstly propose a conceptual architecture for the image fusion schemes in supervised biomedical image analysis: fusing at the feature level, fusing at the classifier level, and fusing at the decision-making level. Further, motivated by the recent success in applying deep learning for natural image analysis, we implement the three image fusion schemes above based on the Convolutional Neural Network (CNN) with varied structures, and combined into a single framework. The proposed image segmentation framework is capable of analyzing the multi-modality images using different fusing schemes simultaneously. The framework is applied to detect the presence of soft tissue sarcoma from the combination of Magnetic Resonance Imaging (MRI), Computed Tomography (CT) and Positron Emission Tomography (PET) images. It is found from the results that while all the fusion schemes outperform the single-modality schemes, fusing at the feature level can generally achieve the best performance in terms of both accuracy and computational cost, but also suffers from the decreased robustness in the presence of large errors in any image modalities.
* Zhe Guo and Xiang Li contribute equally to this work
Label distribution based facial attractiveness computation by deep residual learning
Sep 07, 2016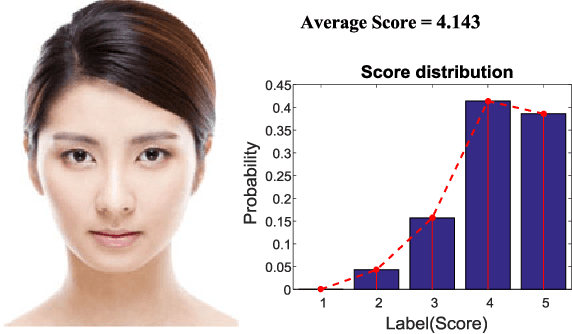
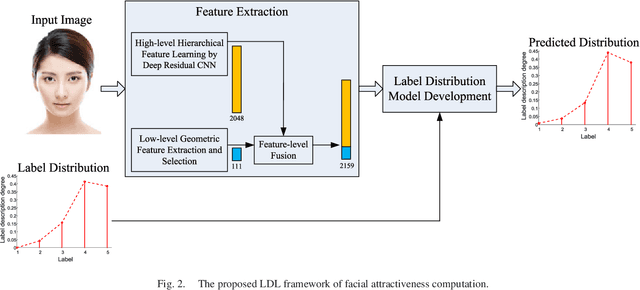
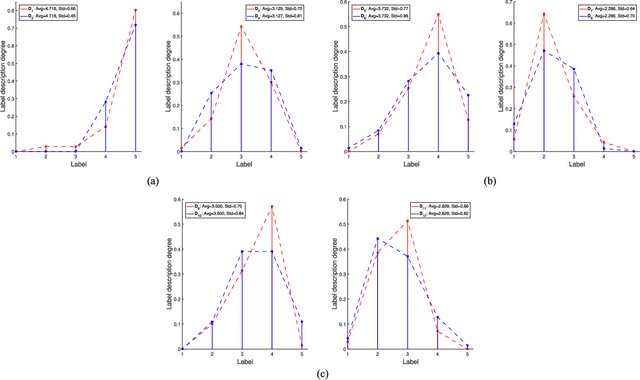
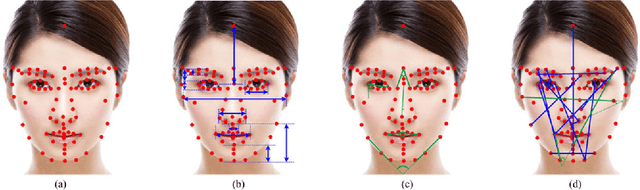
Two challenges lie in the facial attractiveness computation research: the lack of true attractiveness labels (scores), and the lack of an accurate face representation. In order to address the first challenge, this paper recasts facial attractiveness computation as a label distribution learning (LDL) problem rather than a traditional single-label supervised learning task. In this way, the negative influence of the label incomplete problem can be reduced. Inspired by the recent promising work in face recognition using deep neural networks to learn effective features, the second challenge is expected to be solved from a deep learning point of view. A very deep residual network is utilized to enable automatic learning of hierarchical aesthetics representation. Integrating these two ideas, an end-to-end deep learning framework is established. Our approach achieves the best results on a standard benchmark SCUT-FBP dataset compared with other state-of-the-art work.