 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning When to Think: Shaping Adaptive Reasoning in R1-Style Models via Multi-Stage RL
May 16, 2025



Large reasoning models (LRMs) are proficient at generating explicit, step-by-step reasoning sequences before producing final answers. However, such detailed reasoning can introduce substantial computational overhead and latency, particularly for simple problems. To address this over-thinking problem, we explore how to equip LRMs with adaptive thinking capabilities: enabling them to dynamically decide whether or not to engage in explicit reasoning based on problem complexity. Building on R1-style distilled models, we observe that inserting a simple ellipsis ("...") into the prompt can stochastically trigger either a thinking or no-thinking mode, revealing a latent controllability in the reasoning behavior. Leveraging this property, we propose AutoThink, a multi-stage reinforcement learning (RL) framework that progressively optimizes reasoning policies via stage-wise reward shaping. AutoThink learns to invoke explicit reasoning only when necessary, while defaulting to succinct responses for simpler tasks. Experiments on five mainstream mathematical benchmarks demonstrate that AutoThink achieves favorable accuracy-efficiency trade-offs compared to recent prompting and RL-based pruning methods. It can be seamlessly integrated into any R1-style model, including both distilled and further fine-tuned variants. Notably, AutoThink improves relative accuracy by 6.4 percent while reducing token usage by 52 percent on DeepSeek-R1-Distill-Qwen-1.5B, establishing a scalable and adaptive reasoning paradigm for LRMs.
Enhancing LLM Reasoning with Iterative DPO: A Comprehensive Empirical Investigation
Mar 17, 2025



Recent advancements in post-training methodologies for large language models (LLMs) have highlighted reinforcement learning (RL) as a critical component for enhancing reasoning. However, the substantial computational costs associated with RL-based approaches have led to growing interest in alternative paradigms, such as Direct Preference Optimization (DPO). In this study, we investigate the effectiveness of DPO in facilitating self-improvement for LLMs through iterative preference-based learning. We demonstrate that a single round of DPO with coarse filtering significantly enhances mathematical reasoning performance, particularly for strong base model. Furthermore, we design an iterative enhancement framework for both the generator and the reward model (RM), enabling their mutual improvement through online interaction across multiple rounds of DPO. Finally, with simple verifiable rewards, our model DPO-VP achieves RL-level performance with significantly lower computational overhead. These findings highlight DPO as a scalable and cost-effective alternative to RL, offering a practical solution for enhancing LLM reasoning in resource-constrained situations.
An Adaptive Grasping Force Tracking Strategy for Nonlinear and Time-Varying Object Behaviors
Dec 03, 2024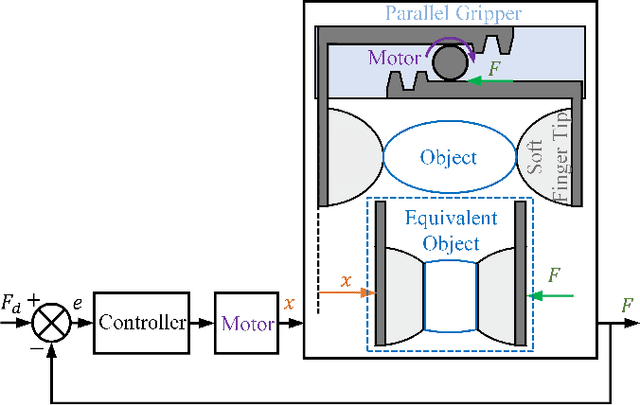

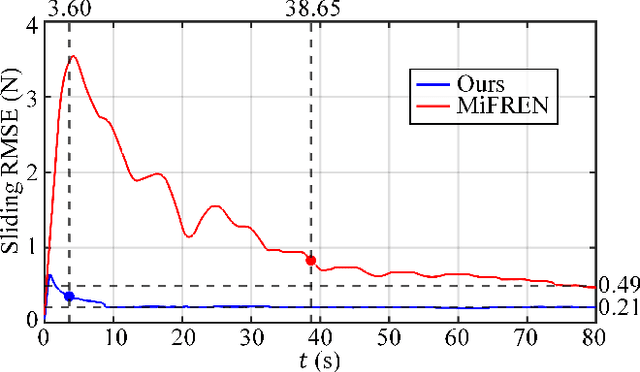

Accurate grasp force control is one of the key skills for ensuring successful and damage-free robotic grasping of objects. Although existing methods have conducted in-depth research on slip detection and grasping force planning, they often overlook the issue of adaptive tracking of the actual force to the target force when handling objects with different material properties. The optimal parameters of a force tracking controller are significantly influenced by the object's stiffness, and many adaptive force tracking algorithms rely on stiffness estimation. However, real-world objects often exhibit viscous, plastic, or other more complex nonlinear time-varying behaviors, and existing studies provide insufficient support for these materials in terms of stiffness definition and estimation. To address this, this paper introduces the concept of generalized stiffness, extending the definition of stiffness to nonlinear time-varying grasp system models, and proposes an online generalized stiffness estimator based on Long Short-Term Memory (LSTM) networks. Based on generalized stiffness, this paper proposes an adaptive parameter adjustment strategy using a PI controller as an example, enabling dynamic force tracking for objects with varying characteristics. Experimental results demonstrate that the proposed method achieves high precision and short probing time, while showing better adaptability to non-ideal objects compared to existing methods. The method effectively solves the problem of grasp force tracking in unknown, nonlinear, and time-varying grasp systems, enhancing the robotic grasping ability in unstructured environments.