 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGHuNeRF: Generalizable Human NeRF from a Monocular Video
Paper and Code


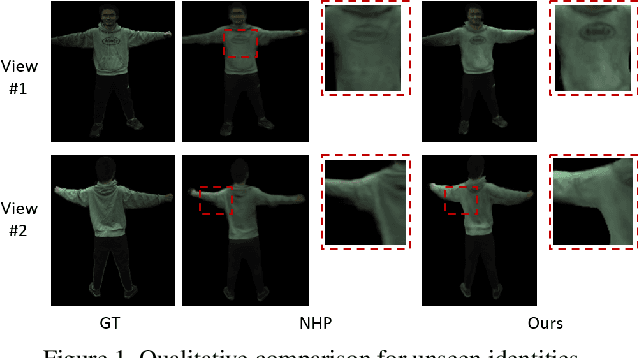

In this paper, we tackle the challenging task of learning a generalizable human NeRF model from a monocular video. Although existing generalizable human NeRFs have achieved impressive results, they require muti-view images or videos which might not be always available. On the other hand, some works on free-viewpoint rendering of human from monocular videos cannot be generalized to unseen identities. In view of these limitations, we propose GHuNeRF to learn a generalizable human NeRF model from a monocular video of the human performer. We first introduce a visibility-aware aggregation scheme to compute vertex-wise features, which is used to construct a 3D feature volume. The feature volume can only represent the overall geometry of the human performer with insufficient accuracy due to the limited resolution. To solve this, we further enhance the volume feature with temporally aligned point-wise features using an attention mechanism. Finally, the enhanced feature is used for predicting density and color for each sampled point. A surface-guided sampling strategy is also introduced to improve the efficiency for both training and inference. We validate our approach on the widely-used ZJU-MoCap dataset, where we achieve comparable performance with existing multi-view video based approaches. We also test on the monocular People-Snapshot dataset and achieve better performance than existing works when only monocular video is used.