 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnomSeer: Reinforcing Multimodal LLMs to Reason for Time-Series Anomaly Detection
Feb 09, 2026Time-series anomaly detection (TSAD) with multimodal large language models (MLLMs) is an emerging area, yet a persistent challenge remains: MLLMs rely on coarse time-series heuristics but struggle with multi-dimensional, detailed reasoning, which is vital for understanding complex time-series data. We present AnomSeer to address this by reinforcing the model to ground its reasoning in precise, structural details of time series, unifying anomaly classification, localization, and explanation. At its core, an expert chain-of-thought trace is generated to provide a verifiable, fine-grained reasoning from classical analyses (e.g., statistical measures, frequency transforms). Building on this, we propose a novel time-series grounded policy optimization (TimerPO) that incorporates two additional components beyond standard reinforcement learning: a time-series grounded advantage based on optimal transport and an orthogonal projection to ensure this auxiliary granular signal does not interfere with the primary detection objective. Across diverse anomaly scenarios, AnomSeer, with Qwen2.5-VL-3B/7B-Instruct, outperforms larger commercial baselines (e.g., GPT-4o) in classification and localization accuracy, particularly on point- and frequency-driven exceptions. Moreover, it produces plausible time-series reasoning traces that support its conclusions.
TimeMaster: Training Time-Series Multimodal LLMs to Reason via Reinforcement Learning
Jun 16, 2025Time-series reasoning remains a significant challenge in multimodal large language models (MLLMs) due to the dynamic temporal patterns, ambiguous semantics, and lack of temporal priors. In this work, we introduce TimeMaster, a reinforcement learning (RL)-based method that enables time-series MLLMs to perform structured, interpretable reasoning directly over visualized time-series inputs and task prompts. TimeMaster adopts a three-part structured output format, reasoning, classification, and domain-specific extension, and is optimized via a composite reward function that aligns format adherence, prediction accuracy, and open-ended insight quality. The model is trained using a two-stage pipeline: we first apply supervised fine-tuning (SFT) to establish a good initialization, followed by Group Relative Policy Optimization (GRPO) at the token level to enable stable and targeted reward-driven improvement in time-series reasoning. We evaluate TimeMaster on the TimerBed benchmark across six real-world classification tasks based on Qwen2.5-VL-3B-Instruct. TimeMaster achieves state-of-the-art performance, outperforming both classical time-series models and few-shot GPT-4o by over 14.6% and 7.3% performance gain, respectively. Notably, TimeMaster goes beyond time-series classification: it also exhibits expert-like reasoning behavior, generates context-aware explanations, and delivers domain-aligned insights. Our results highlight that reward-driven RL can be a scalable and promising path toward integrating temporal understanding into time-series MLLMs.
Diverse Intra- and Inter-Domain Activity Style Fusion for Cross-Person Generalization in Activity Recognition
Jun 07, 2024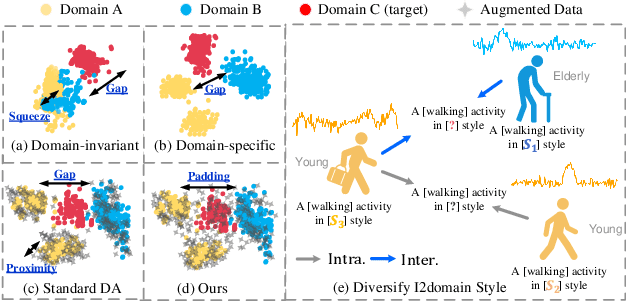
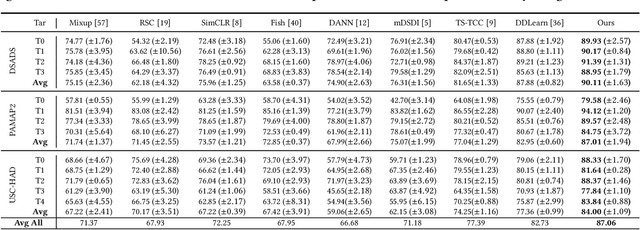
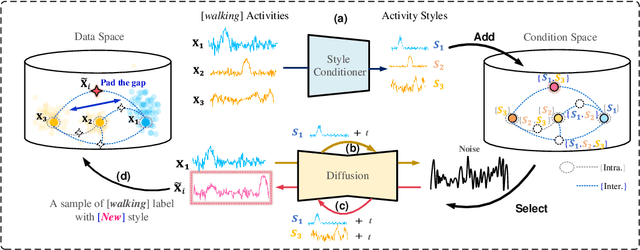
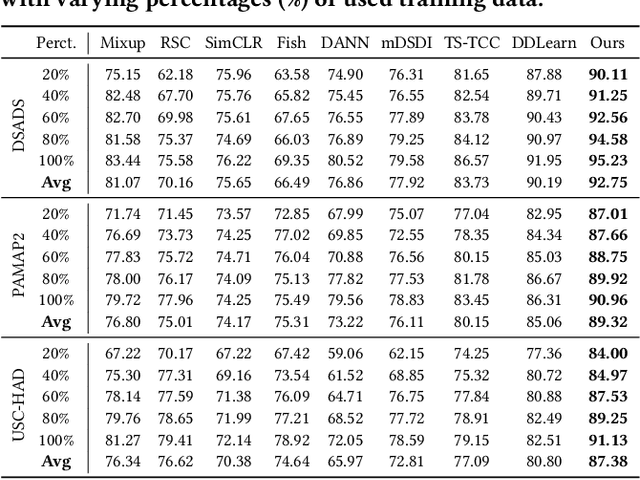
Existing domain generalization (DG) methods for cross-person generalization tasks often face challenges in capturing intra- and inter-domain style diversity, resulting in domain gaps with the target domain. In this study, we explore a novel perspective to tackle this problem, a process conceptualized as domain padding. This proposal aims to enrich the domain diversity by synthesizing intra- and inter-domain style data while maintaining robustness to class labels. We instantiate this concept using a conditional diffusion model and introduce a style-fused sampling strategy to enhance data generation diversity. In contrast to traditional condition-guided sampling, our style-fused sampling strategy allows for the flexible use of one or more random styles to guide data synthesis. This feature presents a notable advancement: it allows for the maximum utilization of possible permutations and combinations among existing styles to generate a broad spectrum of new style instances. Empirical evaluations on a board of datasets demonstrate that our generated data achieves remarkable diversity within the domain space. Both intra- and inter-domain generated data have proven to be significant and valuable, contributing to varying degrees of performance enhancements. Notably, our approach outperforms state-of-the-art DG methods in all human activity recognition tasks.
Temporal Convolutional Explorer Helps Understand 1D-CNN's Learning Behavior in Time Series Classification from Frequency Domain
Oct 09, 2023



While one-dimensional convolutional neural networks (1D-CNNs) have been empirically proven effective in time series classification tasks, we find that there remain undesirable outcomes that could arise in their application, motivating us to further investigate and understand their underlying mechanisms. In this work, we propose a Temporal Convolutional Explorer (TCE) to empirically explore the learning behavior of 1D-CNNs from the perspective of the frequency domain. Our TCE analysis highlights that deeper 1D-CNNs tend to distract the focus from the low-frequency components leading to the accuracy degradation phenomenon, and the disturbing convolution is the driving factor. Then, we leverage our findings to the practical application and propose a regulatory framework, which can easily be integrated into existing 1D-CNNs. It aims to rectify the suboptimal learning behavior by enabling the network to selectively bypass the specified disturbing convolutions. Finally, through comprehensive experiments on widely-used UCR, UEA, and UCI benchmarks, we demonstrate that 1) TCE's insight into 1D-CNN's learning behavior; 2) our regulatory framework enables state-of-the-art 1D-CNNs to get improved performances with less consumption of memory and computational overhead.
FP3O: Enabling Proximal Policy Optimization in Multi-Agent Cooperation with Parameter-Sharing Versatility
Oct 08, 2023



Existing multi-agent PPO algorithms lack compatibility with different types of parameter sharing when extending the theoretical guarantee of PPO to cooperative multi-agent reinforcement learning (MARL). In this paper, we propose a novel and versatile multi-agent PPO algorithm for cooperative MARL to overcome this limitation. Our approach is achieved upon the proposed full-pipeline paradigm, which establishes multiple parallel optimization pipelines by employing various equivalent decompositions of the advantage function. This procedure successfully formulates the interconnections among agents in a more general manner, i.e., the interconnections among pipelines, making it compatible with diverse types of parameter sharing. We provide a solid theoretical foundation for policy improvement and subsequently develop a practical algorithm called Full-Pipeline PPO (FP3O) by several approximations. Empirical evaluations on Multi-Agent MuJoCo and StarCraftII tasks demonstrate that FP3O outperforms other strong baselines and exhibits remarkable versatility across various parameter-sharing configurations.