 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrismFlow: Residual Dynamics for Flow Matching in Time-Series Generation
May 22, 2026Generating high-quality time-series data is challenging because real-world signals often exhibit multimodal patterns and multiscale dynamics, including oscillations and high-frequency variations. Flow Matching (FM) offers an efficient alternative to diffusion models, but practical implementations typically rely on a single finite-capacity global vector-field estimator. In such heterogeneous temporal distributions, distinct regimes may pass through nearby flow states while requiring incompatible conditional velocities. A monolithic estimator trained with the standard $\ell_2$ velocity-matching objective may therefore learn an overly smoothed approximation of the local transport field. This estimator-level smoothing can attenuate branch-specific dynamics, leading to spectral distortion and poor mode coverage. To address this, we propose PrismFlow, a new FM method with Koopman-inspired dynamical experts. Each expert learns residual corrections in a latent space where local nonlinear temporal evolution can be approximated by linear transitions. We further propose a confidence-aware Winner-Take-All (WTA) objective that updates only the expert best aligned with each sample while masking gradients to the others, encouraging mode-specific specialization. During sampling, the selected expert adds a residual dynamical correction to the global transport field, preserving FM stability while recovering fine-grained and high-frequency temporal structures. Across various benchmarks, PrismFlow effectively mitigates the spectral contraction in standard FM and achieves state-of-the-art performance, with a 15.6% gain in Context-FID and a 38.6% improvement in Discriminative Score, while remaining robust in low-data settings and effective for forecasting and imputation.
AnomSeer: Reinforcing Multimodal LLMs to Reason for Time-Series Anomaly Detection
Feb 09, 2026Time-series anomaly detection (TSAD) with multimodal large language models (MLLMs) is an emerging area, yet a persistent challenge remains: MLLMs rely on coarse time-series heuristics but struggle with multi-dimensional, detailed reasoning, which is vital for understanding complex time-series data. We present AnomSeer to address this by reinforcing the model to ground its reasoning in precise, structural details of time series, unifying anomaly classification, localization, and explanation. At its core, an expert chain-of-thought trace is generated to provide a verifiable, fine-grained reasoning from classical analyses (e.g., statistical measures, frequency transforms). Building on this, we propose a novel time-series grounded policy optimization (TimerPO) that incorporates two additional components beyond standard reinforcement learning: a time-series grounded advantage based on optimal transport and an orthogonal projection to ensure this auxiliary granular signal does not interfere with the primary detection objective. Across diverse anomaly scenarios, AnomSeer, with Qwen2.5-VL-3B/7B-Instruct, outperforms larger commercial baselines (e.g., GPT-4o) in classification and localization accuracy, particularly on point- and frequency-driven exceptions. Moreover, it produces plausible time-series reasoning traces that support its conclusions.
Improving Densification in 3D Gaussian Splatting for High-Fidelity Rendering
Aug 17, 2025Although 3D Gaussian Splatting (3DGS) has achieved impressive performance in real-time rendering, its densification strategy often results in suboptimal reconstruction quality. In this work, we present a comprehensive improvement to the densification pipeline of 3DGS from three perspectives: when to densify, how to densify, and how to mitigate overfitting. Specifically, we propose an Edge-Aware Score to effectively select candidate Gaussians for splitting. We further introduce a Long-Axis Split strategy that reduces geometric distortions introduced by clone and split operations. To address overfitting, we design a set of techniques, including Recovery-Aware Pruning, Multi-step Update, and Growth Control. Our method enhances rendering fidelity without introducing additional training or inference overhead, achieving state-of-the-art performance with fewer Gaussians.
TimeMaster: Training Time-Series Multimodal LLMs to Reason via Reinforcement Learning
Jun 16, 2025Time-series reasoning remains a significant challenge in multimodal large language models (MLLMs) due to the dynamic temporal patterns, ambiguous semantics, and lack of temporal priors. In this work, we introduce TimeMaster, a reinforcement learning (RL)-based method that enables time-series MLLMs to perform structured, interpretable reasoning directly over visualized time-series inputs and task prompts. TimeMaster adopts a three-part structured output format, reasoning, classification, and domain-specific extension, and is optimized via a composite reward function that aligns format adherence, prediction accuracy, and open-ended insight quality. The model is trained using a two-stage pipeline: we first apply supervised fine-tuning (SFT) to establish a good initialization, followed by Group Relative Policy Optimization (GRPO) at the token level to enable stable and targeted reward-driven improvement in time-series reasoning. We evaluate TimeMaster on the TimerBed benchmark across six real-world classification tasks based on Qwen2.5-VL-3B-Instruct. TimeMaster achieves state-of-the-art performance, outperforming both classical time-series models and few-shot GPT-4o by over 14.6% and 7.3% performance gain, respectively. Notably, TimeMaster goes beyond time-series classification: it also exhibits expert-like reasoning behavior, generates context-aware explanations, and delivers domain-aligned insights. Our results highlight that reward-driven RL can be a scalable and promising path toward integrating temporal understanding into time-series MLLMs.
Efficient Density Control for 3D Gaussian Splatting
Nov 15, 2024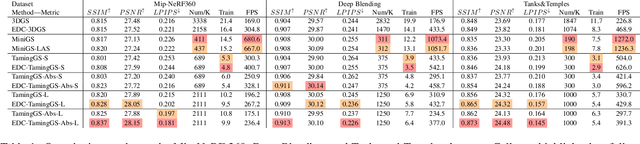
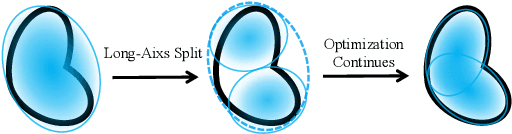
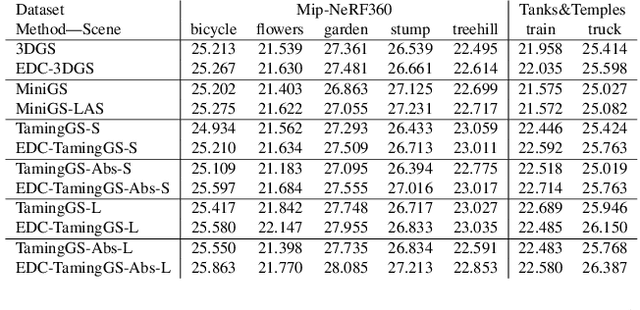
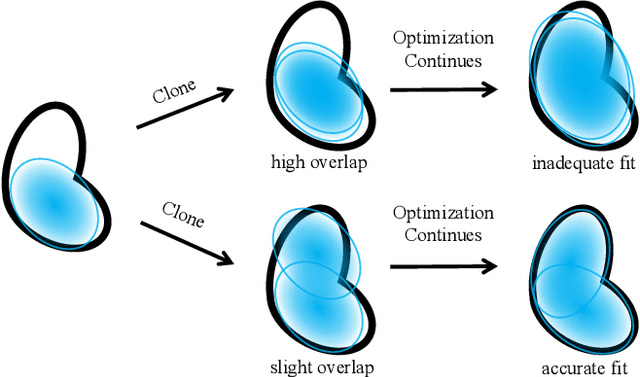
3D Gaussian Splatting (3DGS) excels in novel view synthesis, balancing advanced rendering quality with real-time performance. However, in trained scenes, a large number of Gaussians with low opacity significantly increase rendering costs. This issue arises due to flaws in the split and clone operations during the densification process, which lead to extensive Gaussian overlap and subsequent opacity reduction. To enhance the efficiency of Gaussian utilization, we improve the adaptive density control of 3DGS. First, we introduce a more efficient long-axis split operation to replace the original clone and split, which mitigates Gaussian overlap and improves densification efficiency.Second, we propose a simple adaptive pruning technique to reduce the number of low-opacity Gaussians. Finally, by dynamically lowering the splitting threshold and applying importance weighting, the efficiency of Gaussian utilization is further improved.We evaluate our proposed method on various challenging real-world datasets. Experimental results show that our Efficient Density Control (EDC) can enhance both the rendering speed and quality.
Diverse Intra- and Inter-Domain Activity Style Fusion for Cross-Person Generalization in Activity Recognition
Jun 07, 2024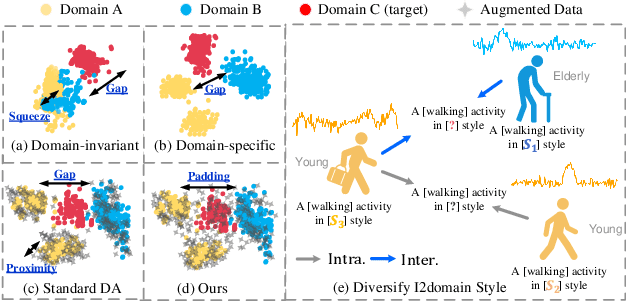
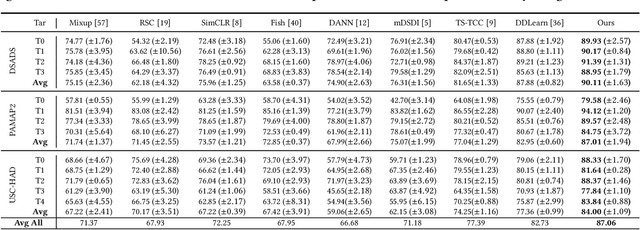
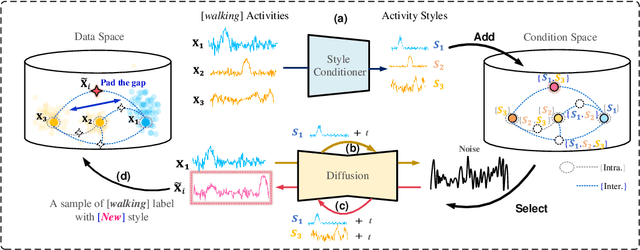
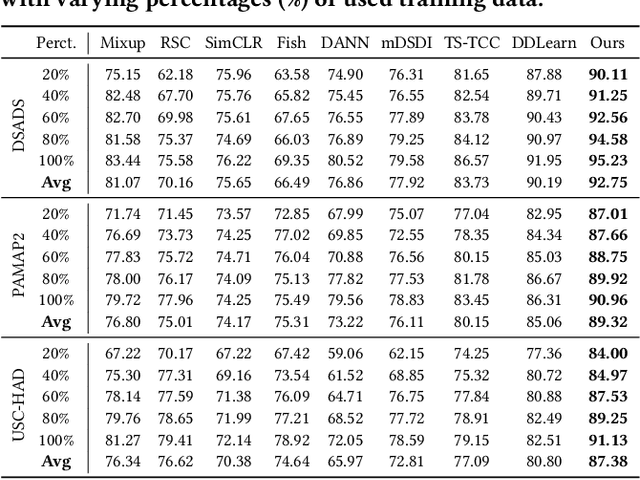
Existing domain generalization (DG) methods for cross-person generalization tasks often face challenges in capturing intra- and inter-domain style diversity, resulting in domain gaps with the target domain. In this study, we explore a novel perspective to tackle this problem, a process conceptualized as domain padding. This proposal aims to enrich the domain diversity by synthesizing intra- and inter-domain style data while maintaining robustness to class labels. We instantiate this concept using a conditional diffusion model and introduce a style-fused sampling strategy to enhance data generation diversity. In contrast to traditional condition-guided sampling, our style-fused sampling strategy allows for the flexible use of one or more random styles to guide data synthesis. This feature presents a notable advancement: it allows for the maximum utilization of possible permutations and combinations among existing styles to generate a broad spectrum of new style instances. Empirical evaluations on a board of datasets demonstrate that our generated data achieves remarkable diversity within the domain space. Both intra- and inter-domain generated data have proven to be significant and valuable, contributing to varying degrees of performance enhancements. Notably, our approach outperforms state-of-the-art DG methods in all human activity recognition tasks.
MirrorGAN: Learning Text-to-image Generation by Redescription
Mar 14, 2019



Generating an image from a given text description has two goals: visual realism and semantic consistency. Although significant progress has been made in generating high-quality and visually realistic images using generative adversarial networks, guaranteeing semantic consistency between the text description and visual content remains very challenging. In this paper, we address this problem by proposing a novel global-local attentive and semantic-preserving text-to-image-to-text framework called MirrorGAN. MirrorGAN exploits the idea of learning text-to-image generation by redescription and consists of three modules: a semantic text embedding module (STEM), a global-local collaborative attentive module for cascaded image generation (GLAM), and a semantic text regeneration and alignment module (STREAM). STEM generates word- and sentence-level embeddings. GLAM has a cascaded architecture for generating target images from coarse to fine scales, leveraging both local word attention and global sentence attention to progressively enhance the diversity and semantic consistency of the generated images. STREAM seeks to regenerate the text description from the generated image, which semantically aligns with the given text description. Thorough experiments on two public benchmark datasets demonstrate the superiority of MirrorGAN over other representative state-of-the-art methods.
Ancient Painting to Natural Image: A New Solution for Painting Processing
Jan 02, 2019
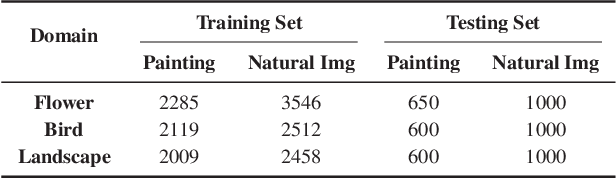

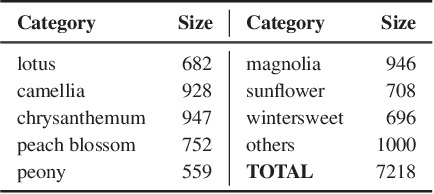
Collecting a large-scale and well-annotated dataset for image processing has become a common practice in computer vision. However, in the ancient painting area, this task is not practical as the number of paintings is limited and their style is greatly diverse. We, therefore, propose a novel solution for the problems that come with ancient painting processing. This is to use domain transfer to convert ancient paintings to photo-realistic natural images. By doing so, the ancient painting processing problems become natural image processing problems and models trained on natural images can be directly applied to the transferred paintings. Specifically, we focus on Chinese ancient flower, bird and landscape paintings in this work. A novel Domain Style Transfer Network (DSTN) is proposed to transfer ancient paintings to natural images which employ a compound loss to ensure that the transferred paintings still maintain the color composition and content of the input paintings. The experiment results show that the transferred paintings generated by the DSTN have a better performance in both the human perceptual test and other image processing tasks than other state-of-art methods, indicating the authenticity of the transferred paintings and the superiority of the proposed method.
Cross-Media Similarity Evaluation for Web Image Retrieval in the Wild
Jan 06, 2018
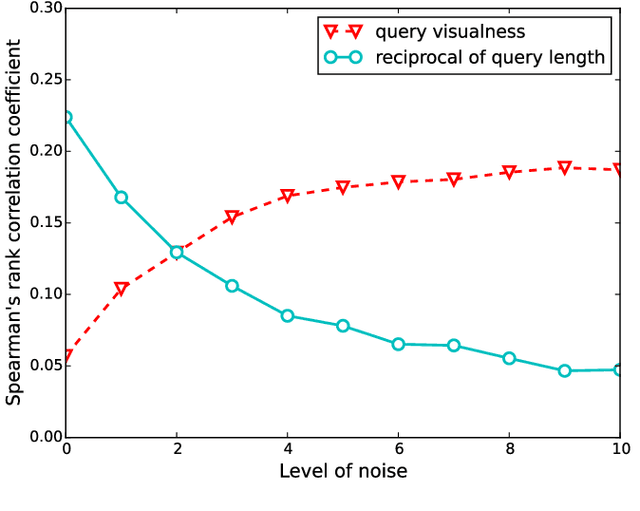
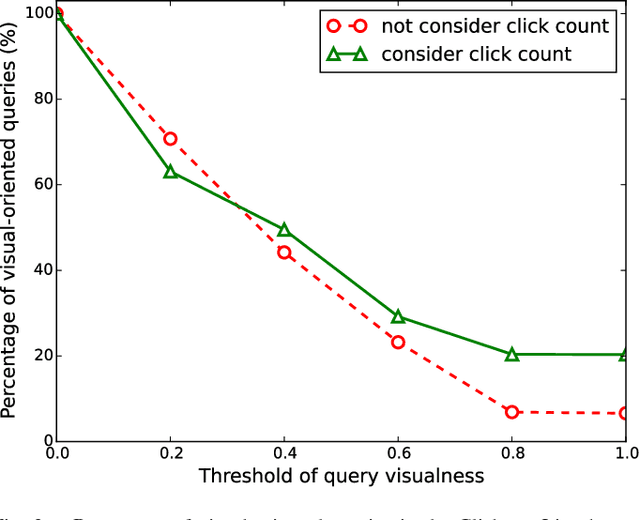
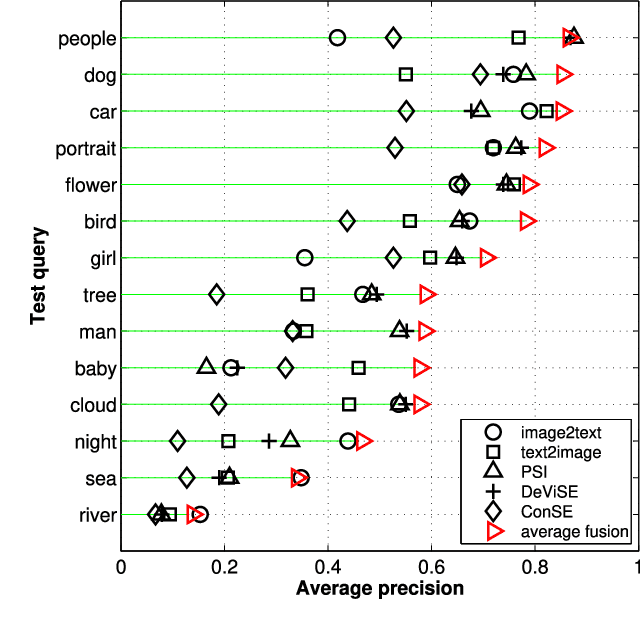
In order to retrieve unlabeled images by textual queries, cross-media similarity computation is a key ingredient. Although novel methods are continuously introduced, little has been done to evaluate these methods together with large-scale query log analysis. Consequently, how far have these methods brought us in answering real-user queries is unclear. Given baseline methods that compute cross-media similarity using relatively simple text/image matching, how much progress have advanced models made is also unclear. This paper takes a pragmatic approach to answering the two questions. Queries are automatically categorized according to the proposed query visualness measure, and later connected to the evaluation of multiple cross-media similarity models on three test sets. Such a connection reveals that the success of the state-of-the-art is mainly attributed to their good performance on visual-oriented queries, while these queries account for only a small part of real-user queries. To quantify the current progress, we propose a simple text2image method, representing a novel test query by a set of images selected from large-scale query log. Consequently, computing cross-media similarity between the test query and a given image boils down to comparing the visual similarity between the given image and the selected images. Image retrieval experiments on the challenging Clickture dataset show that the proposed text2image compares favorably to recent deep learning based alternatives.
Exploring Human-like Attention Supervision in Visual Question Answering
Sep 19, 2017
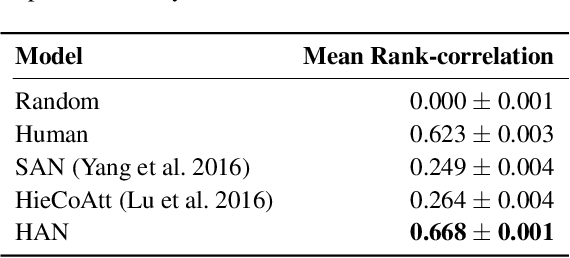
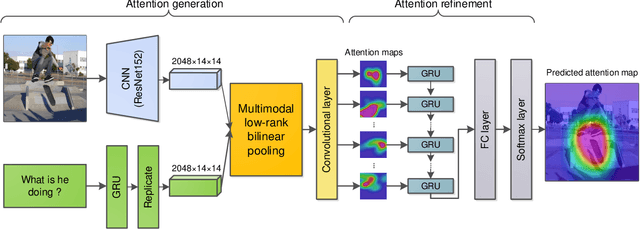

Attention mechanisms have been widely applied in the Visual Question Answering (VQA) task, as they help to focus on the area-of-interest of both visual and textual information. To answer the questions correctly, the model needs to selectively target different areas of an image, which suggests that an attention-based model may benefit from an explicit attention supervision. In this work, we aim to address the problem of adding attention supervision to VQA models. Since there is a lack of human attention data, we first propose a Human Attention Network (HAN) to generate human-like attention maps, training on a recently released dataset called Human ATtention Dataset (VQA-HAT). Then, we apply the pre-trained HAN on the VQA v2.0 dataset to automatically produce the human-like attention maps for all image-question pairs. The generated human-like attention map dataset for the VQA v2.0 dataset is named as Human-Like ATtention (HLAT) dataset. Finally, we apply human-like attention supervision to an attention-based VQA model. The experiments show that adding human-like supervision yields a more accurate attention together with a better performance, showing a promising future for human-like attention supervision in VQA.