 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePowerFusion: A Tensor Compiler with Explicit Data Movement Description and Instruction-level Graph IR
Jul 11, 2023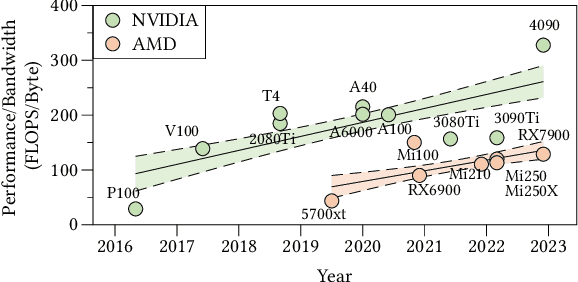
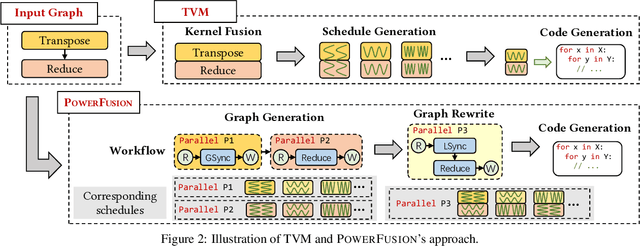
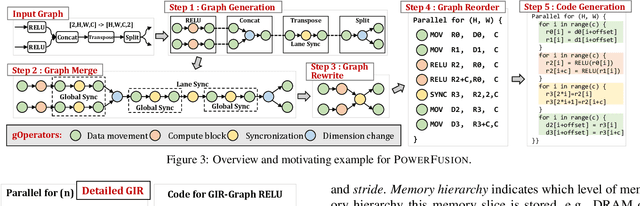
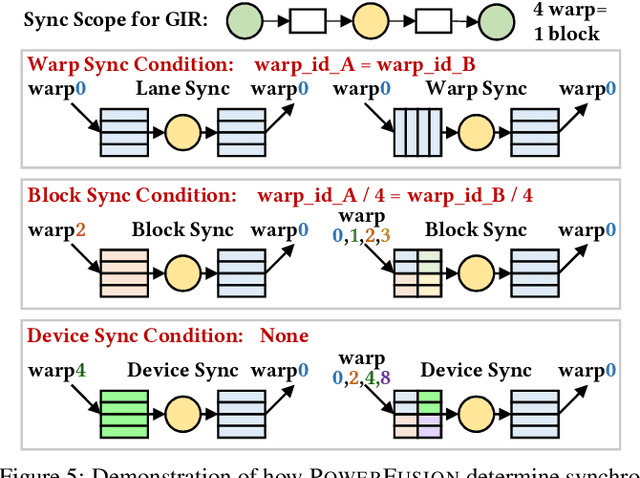
Deep neural networks (DNNs) are of critical use in different domains. To accelerate DNN computation, tensor compilers are proposed to generate efficient code on different domain-specific accelerators. Existing tensor compilers mainly focus on optimizing computation efficiency. However, memory access is becoming a key performance bottleneck because the computational performance of accelerators is increasing much faster than memory performance. The lack of direct description of memory access and data dependence in current tensor compilers' intermediate representation (IR) brings significant challenges to generate memory-efficient code. In this paper, we propose IntelliGen, a tensor compiler that can generate high-performance code for memory-intensive operators by considering both computation and data movement optimizations. IntelliGen represent a DNN program using GIR, which includes primitives indicating its computation, data movement, and parallel strategies. This information will be further composed as an instruction-level dataflow graph to perform holistic optimizations by searching different memory access patterns and computation operations, and generating memory-efficient code on different hardware. We evaluate IntelliGen on NVIDIA GPU, AMD GPU, and Cambricon MLU, showing speedup up to 1.97x, 2.93x, and 16.91x(1.28x, 1.23x, and 2.31x on average), respectively, compared to current most performant frameworks.
GLM-130B: An Open Bilingual Pre-trained Model
Oct 05, 2022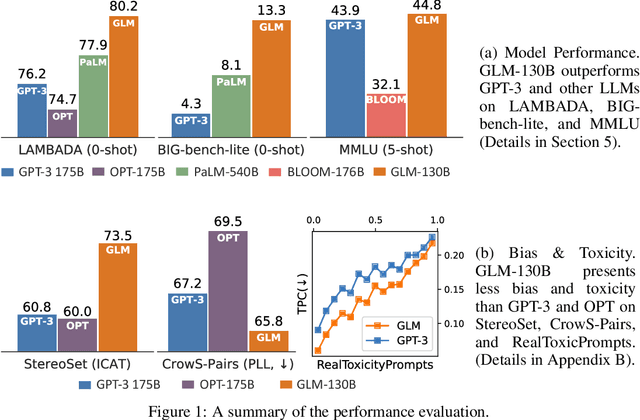
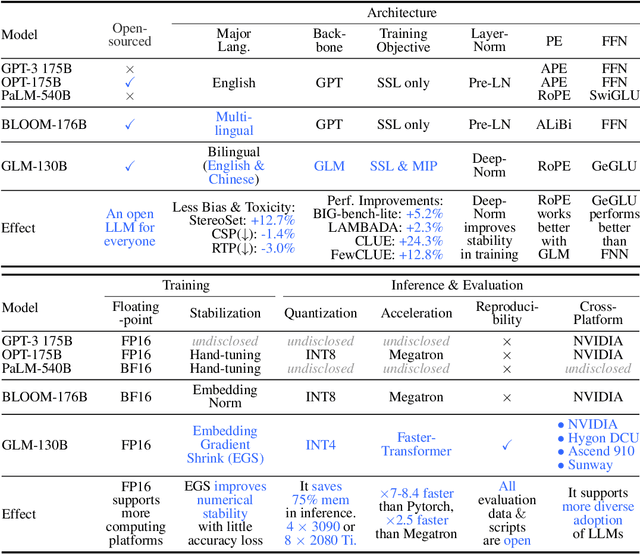

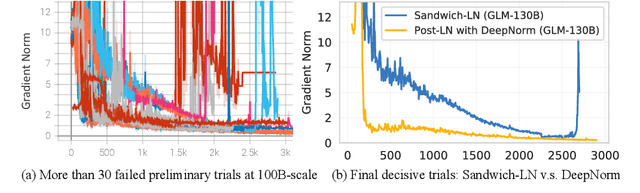
We introduce GLM-130B, a bilingual (English and Chinese) pre-trained language model with 130 billion parameters. It is an attempt to open-source a 100B-scale model at least as good as GPT-3 and unveil how models of such a scale can be successfully pre-trained. Over the course of this effort, we face numerous unexpected technical and engineering challenges, particularly on loss spikes and disconvergence. In this paper, we introduce the training process of GLM-130B including its design choices, training strategies for both efficiency and stability, and engineering efforts. The resultant GLM-130B model offers significant outperformance over GPT-3 175B on a wide range of popular English benchmarks while the performance advantage is not observed in OPT-175B and BLOOM-176B. It also consistently and significantly outperforms ERNIE TITAN 3.0 260B -- the largest Chinese language model -- across related benchmarks. Finally, we leverage a unique scaling property of GLM-130B to reach INT4 quantization, without quantization aware training and with almost no performance loss, making it the first among 100B-scale models. More importantly, the property allows its effective inference on 4$\times$RTX 3090 (24G) or 8$\times$RTX 2080 Ti (11G) GPUs, the most ever affordable GPUs required for using 100B-scale models. The GLM-130B model weights are publicly accessible and its code, training logs, related toolkit, and lessons learned are open-sourced at https://github.com/THUDM/GLM-130B .
OLLIE: Derivation-based Tensor Program Optimizer
Aug 02, 2022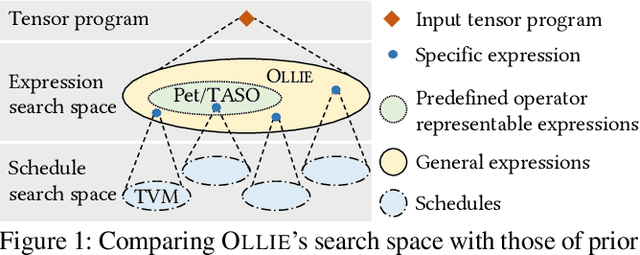
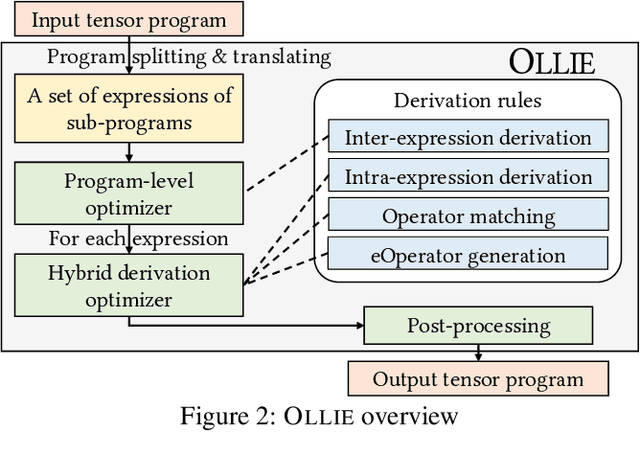
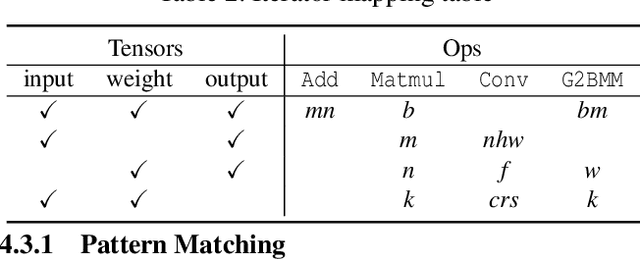
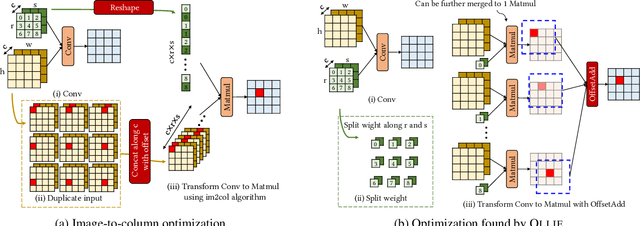
Boosting the runtime performance of deep neural networks (DNNs) is critical due to their wide adoption in real-world tasks. Existing approaches to optimizing the tensor algebra expression of a DNN only consider expressions representable by a fixed set of predefined operators, missing possible optimization opportunities between general expressions. We propose OLLIE, the first derivation-based tensor program optimizer. OLLIE optimizes tensor programs by leveraging transformations between general tensor algebra expressions, enabling a significantly larger expression search space that includes those supported by prior work as special cases. OLLIE uses a hybrid derivation-based optimizer that effectively combines explorative and guided derivations to quickly discover highly optimized expressions. Evaluation on seven DNNs shows that OLLIE can outperform existing optimizers by up to 2.73$\times$ (1.46$\times$ on average) on an A100 GPU and up to 2.68$\times$ (1.51$\times$) on a V100 GPU, respectively.
A Roadmap for Big Model
Apr 02, 2022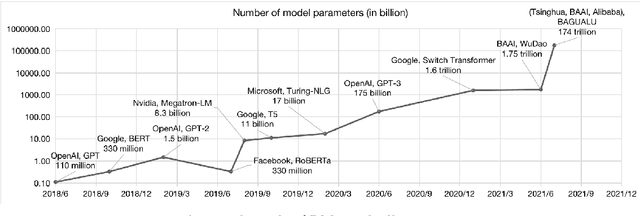
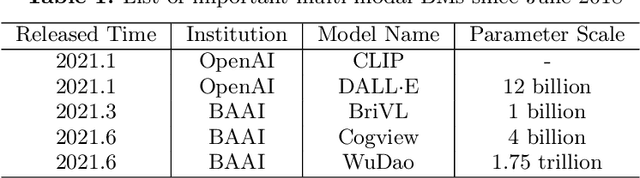
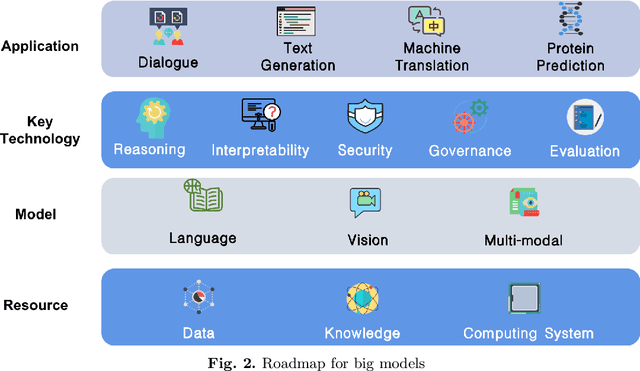
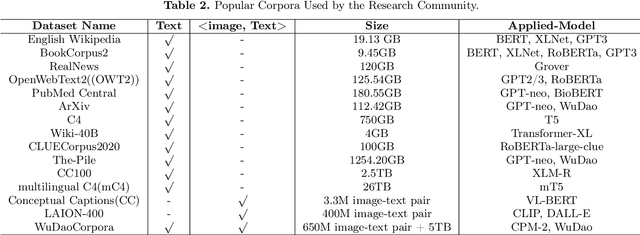
With the rapid development of deep learning, training Big Models (BMs) for multiple downstream tasks becomes a popular paradigm. Researchers have achieved various outcomes in the construction of BMs and the BM application in many fields. At present, there is a lack of research work that sorts out the overall progress of BMs and guides the follow-up research. In this paper, we cover not only the BM technologies themselves but also the prerequisites for BM training and applications with BMs, dividing the BM review into four parts: Resource, Models, Key Technologies and Application. We introduce 16 specific BM-related topics in those four parts, they are Data, Knowledge, Computing System, Parallel Training System, Language Model, Vision Model, Multi-modal Model, Theory&Interpretability, Commonsense Reasoning, Reliability&Security, Governance, Evaluation, Machine Translation, Text Generation, Dialogue and Protein Research. In each topic, we summarize clearly the current studies and propose some future research directions. At the end of this paper, we conclude the further development of BMs in a more general view.
Ancient Painting to Natural Image: A New Solution for Painting Processing
Jan 02, 2019
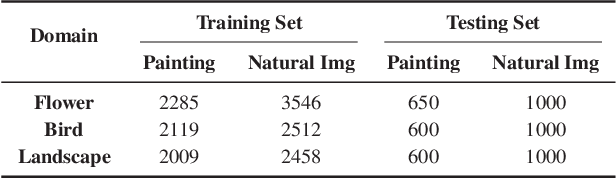

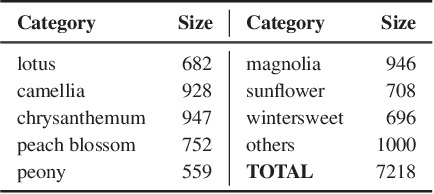
Collecting a large-scale and well-annotated dataset for image processing has become a common practice in computer vision. However, in the ancient painting area, this task is not practical as the number of paintings is limited and their style is greatly diverse. We, therefore, propose a novel solution for the problems that come with ancient painting processing. This is to use domain transfer to convert ancient paintings to photo-realistic natural images. By doing so, the ancient painting processing problems become natural image processing problems and models trained on natural images can be directly applied to the transferred paintings. Specifically, we focus on Chinese ancient flower, bird and landscape paintings in this work. A novel Domain Style Transfer Network (DSTN) is proposed to transfer ancient paintings to natural images which employ a compound loss to ensure that the transferred paintings still maintain the color composition and content of the input paintings. The experiment results show that the transferred paintings generated by the DSTN have a better performance in both the human perceptual test and other image processing tasks than other state-of-art methods, indicating the authenticity of the transferred paintings and the superiority of the proposed method.