 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSolution for the EPO CodeFest on Green Plastics: Hierarchical multi-label classification of patents relating to green plastics using deep learning
Feb 22, 2023



This work aims at hierarchical multi-label patents classification for patents disclosing technologies related to green plastics. This is an emerging field for which there is currently no classification scheme, and hence, no labeled data is available, making this task particularly challenging. We first propose a classification scheme for this technology and a way to learn a machine learning model to classify patents into the proposed classification scheme. To achieve this, we come up with a strategy to automatically assign labels to patents in order to create a labeled training dataset that can be used to learn a classification model in a supervised learning setting. Using said training dataset, we come up with two classification models, a SciBERT Neural Network (SBNN) model and a SciBERT Hierarchical Neural Network (SBHNN) model. Both models use a BERT model as a feature extractor and on top of it, a neural network as a classifier. We carry out extensive experiments and report commonly evaluation metrics for this challenging classification problem. The experiment results verify the validity of our approach and show that our model sets a very strong benchmark for this problem. We also interpret our models by visualizing the word importance given by the trained model, which indicates the model is capable to extract high-level semantic information of input documents. Finally, we highlight how our solution fulfills the evaluation criteria for the EPO CodeFest and we also outline possible directions for future work. Our code has been made available at https://github.com/epo/CF22-Green-Hands
S2IGAN: Speech-to-Image Generation via Adversarial Learning
May 14, 2020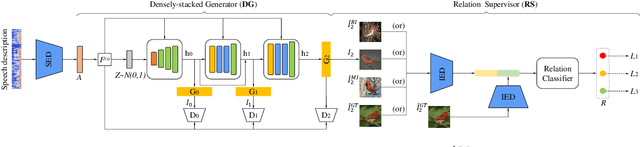
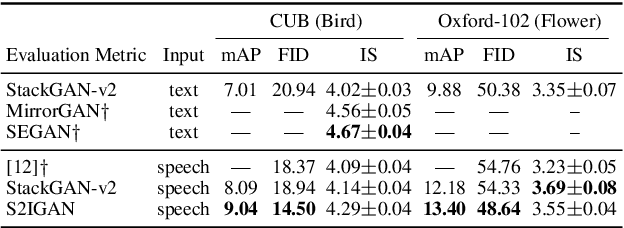


An estimated half of the world's languages do not have a written form, making it impossible for these languages to benefit from any existing text-based technologies. In this paper, a speech-to-image generation (S2IG) framework is proposed which translates speech descriptions to photo-realistic images without using any text information, thus allowing unwritten languages to potentially benefit from this technology. The proposed S2IG framework, named S2IGAN, consists of a speech embedding network (SEN) and a relation-supervised densely-stacked generative model (RDG). SEN learns the speech embedding with the supervision of the corresponding visual information. Conditioned on the speech embedding produced by SEN, the proposed RDG synthesizes images that are semantically consistent with the corresponding speech descriptions. Extensive experiments on two public benchmark datasets CUB and Oxford-102 demonstrate the effectiveness of the proposed S2IGAN on synthesizing high-quality and semantically-consistent images from the speech signal, yielding a good performance and a solid baseline for the S2IG task.
MirrorGAN: Learning Text-to-image Generation by Redescription
Mar 14, 2019



Generating an image from a given text description has two goals: visual realism and semantic consistency. Although significant progress has been made in generating high-quality and visually realistic images using generative adversarial networks, guaranteeing semantic consistency between the text description and visual content remains very challenging. In this paper, we address this problem by proposing a novel global-local attentive and semantic-preserving text-to-image-to-text framework called MirrorGAN. MirrorGAN exploits the idea of learning text-to-image generation by redescription and consists of three modules: a semantic text embedding module (STEM), a global-local collaborative attentive module for cascaded image generation (GLAM), and a semantic text regeneration and alignment module (STREAM). STEM generates word- and sentence-level embeddings. GLAM has a cascaded architecture for generating target images from coarse to fine scales, leveraging both local word attention and global sentence attention to progressively enhance the diversity and semantic consistency of the generated images. STREAM seeks to regenerate the text description from the generated image, which semantically aligns with the given text description. Thorough experiments on two public benchmark datasets demonstrate the superiority of MirrorGAN over other representative state-of-the-art methods.
Ancient Painting to Natural Image: A New Solution for Painting Processing
Jan 02, 2019
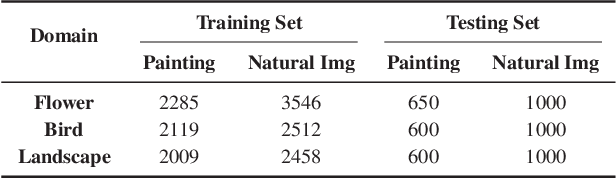

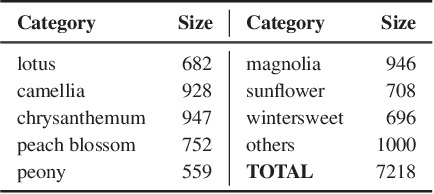
Collecting a large-scale and well-annotated dataset for image processing has become a common practice in computer vision. However, in the ancient painting area, this task is not practical as the number of paintings is limited and their style is greatly diverse. We, therefore, propose a novel solution for the problems that come with ancient painting processing. This is to use domain transfer to convert ancient paintings to photo-realistic natural images. By doing so, the ancient painting processing problems become natural image processing problems and models trained on natural images can be directly applied to the transferred paintings. Specifically, we focus on Chinese ancient flower, bird and landscape paintings in this work. A novel Domain Style Transfer Network (DSTN) is proposed to transfer ancient paintings to natural images which employ a compound loss to ensure that the transferred paintings still maintain the color composition and content of the input paintings. The experiment results show that the transferred paintings generated by the DSTN have a better performance in both the human perceptual test and other image processing tasks than other state-of-art methods, indicating the authenticity of the transferred paintings and the superiority of the proposed method.
Exploring Human-like Attention Supervision in Visual Question Answering
Sep 19, 2017
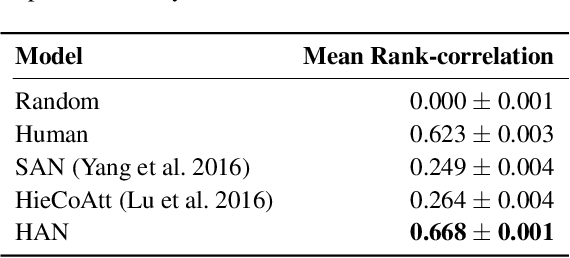
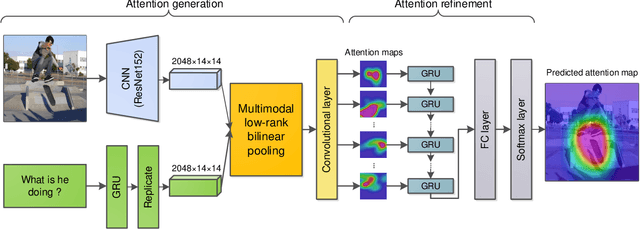

Attention mechanisms have been widely applied in the Visual Question Answering (VQA) task, as they help to focus on the area-of-interest of both visual and textual information. To answer the questions correctly, the model needs to selectively target different areas of an image, which suggests that an attention-based model may benefit from an explicit attention supervision. In this work, we aim to address the problem of adding attention supervision to VQA models. Since there is a lack of human attention data, we first propose a Human Attention Network (HAN) to generate human-like attention maps, training on a recently released dataset called Human ATtention Dataset (VQA-HAT). Then, we apply the pre-trained HAN on the VQA v2.0 dataset to automatically produce the human-like attention maps for all image-question pairs. The generated human-like attention map dataset for the VQA v2.0 dataset is named as Human-Like ATtention (HLAT) dataset. Finally, we apply human-like attention supervision to an attention-based VQA model. The experiments show that adding human-like supervision yields a more accurate attention together with a better performance, showing a promising future for human-like attention supervision in VQA.