 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Human-like Attention Supervision in Visual Question Answering
Paper and Code
Sep 19, 2017
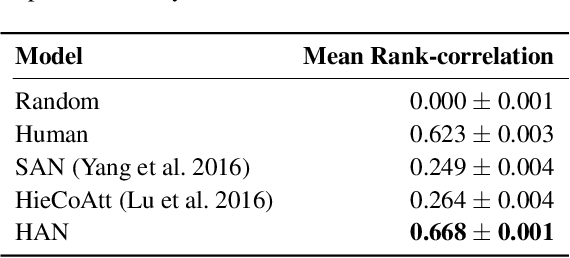
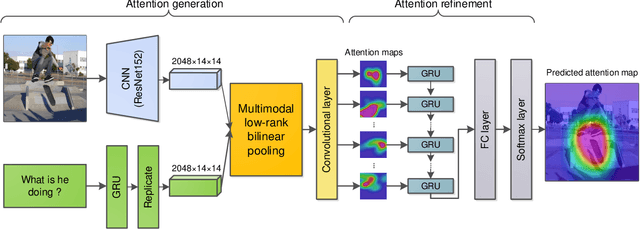

Attention mechanisms have been widely applied in the Visual Question Answering (VQA) task, as they help to focus on the area-of-interest of both visual and textual information. To answer the questions correctly, the model needs to selectively target different areas of an image, which suggests that an attention-based model may benefit from an explicit attention supervision. In this work, we aim to address the problem of adding attention supervision to VQA models. Since there is a lack of human attention data, we first propose a Human Attention Network (HAN) to generate human-like attention maps, training on a recently released dataset called Human ATtention Dataset (VQA-HAT). Then, we apply the pre-trained HAN on the VQA v2.0 dataset to automatically produce the human-like attention maps for all image-question pairs. The generated human-like attention map dataset for the VQA v2.0 dataset is named as Human-Like ATtention (HLAT) dataset. Finally, we apply human-like attention supervision to an attention-based VQA model. The experiments show that adding human-like supervision yields a more accurate attention together with a better performance, showing a promising future for human-like attention supervision in VQA.