 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeMo: Enabling LEss Token Involvement for MOre Context Fine-tuning
Jan 15, 2025



The escalating demand for long-context applications has intensified the necessity of extending the LLM context windows. Despite recent fine-tuning approaches successfully expanding context lengths, their high memory footprints, especially for activations, present a critical practical limitation. Current parameter-efficient fine-tuning methods prioritize reducing parameter update overhead over addressing activation memory constraints. Similarly, existing sparsity mechanisms improve computational efficiency but overlook activation memory optimization due to the phenomenon of Shadowy Activation. In this paper, we propose LeMo, the first LLM fine-tuning system that explores and exploits a new token-level sparsity mechanism inherent in long-context scenarios, termed Contextual Token Sparsity. LeMo minimizes redundant token involvement by assessing the informativeness of token embeddings while preserving model accuracy. Specifically, LeMo introduces three key techniques: (1) Token Elimination, dynamically identifying and excluding redundant tokens across varying inputs and layers. (2) Pattern Prediction, utilizing well-trained predictors to approximate token sparsity patterns with minimal overhead. (3) Kernel Optimization, employing permutation-free and segment-based strategies to boost system performance. We implement LeMo as an end-to-end fine-tuning system compatible with various LLM architectures and other optimization techniques. Comprehensive evaluations demonstrate that LeMo reduces memory consumption by up to 1.93x and achieves up to 1.36x speedups, outperforming state-of-the-art fine-tuning systems.
Ripple: Accelerating LLM Inference on Smartphones with Correlation-Aware Neuron Management
Oct 29, 2024



Large Language Models (LLMs) have achieved remarkable success across various domains, yet deploying them on mobile devices remains an arduous challenge due to their extensive computational and memory demands. While lightweight LLMs have been developed to fit mobile environments, they suffer from degraded model accuracy. In contrast, sparsity-based techniques minimize DRAM usage by selectively transferring only relevant neurons to DRAM while retaining the full model in external storage, such as flash. However, such approaches are critically limited by numerous I/O operations, particularly on smartphones with severe IOPS constraints. In this paper, we propose Ripple, a novel approach that accelerates LLM inference on smartphones by optimizing neuron placement in flash memory. Ripple leverages the concept of Neuron Co-Activation, where neurons frequently activated together are linked to facilitate continuous read access and optimize data transfer efficiency. Our approach incorporates a two-stage solution: an offline stage that reorganizes neuron placement based on co-activation patterns, and an online stage that employs tailored data access and caching strategies to align well with hardware characteristics. Evaluations conducted on a variety of smartphones and LLMs demonstrate that Ripple achieves up to 5.93x improvements in I/O latency compared to the state-of-the-art. As the first solution to optimize storage placement under sparsity, Ripple explores a new optimization space at the intersection of sparsity-driven algorithm and storage-level system co-design in LLM inference.
OLLIE: Derivation-based Tensor Program Optimizer
Aug 02, 2022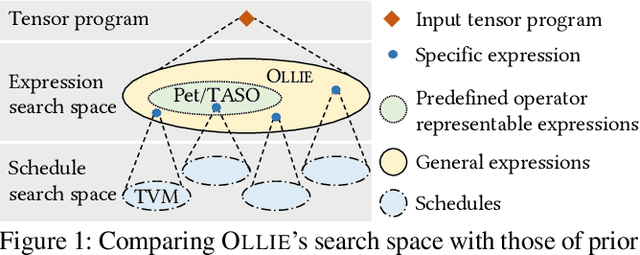
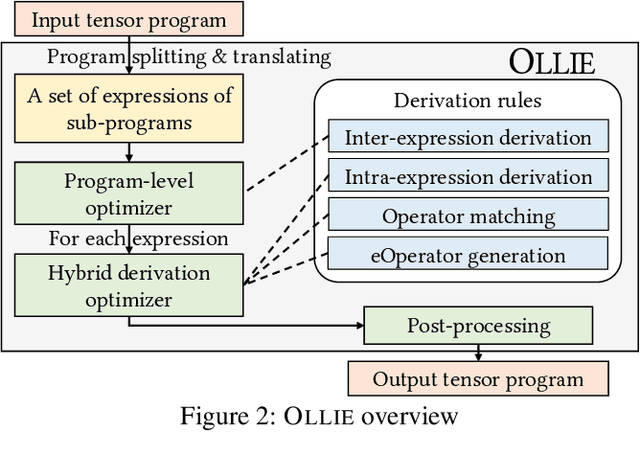
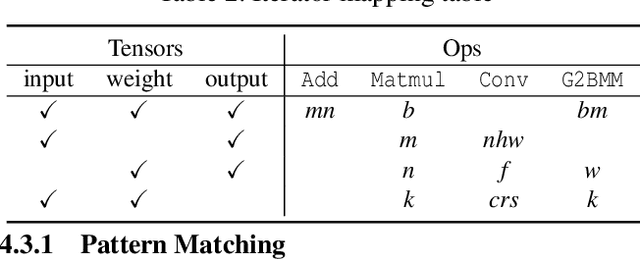
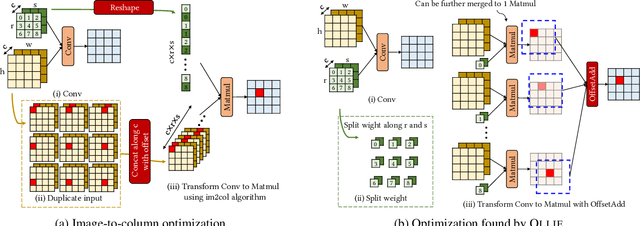
Boosting the runtime performance of deep neural networks (DNNs) is critical due to their wide adoption in real-world tasks. Existing approaches to optimizing the tensor algebra expression of a DNN only consider expressions representable by a fixed set of predefined operators, missing possible optimization opportunities between general expressions. We propose OLLIE, the first derivation-based tensor program optimizer. OLLIE optimizes tensor programs by leveraging transformations between general tensor algebra expressions, enabling a significantly larger expression search space that includes those supported by prior work as special cases. OLLIE uses a hybrid derivation-based optimizer that effectively combines explorative and guided derivations to quickly discover highly optimized expressions. Evaluation on seven DNNs shows that OLLIE can outperform existing optimizers by up to 2.73$\times$ (1.46$\times$ on average) on an A100 GPU and up to 2.68$\times$ (1.51$\times$) on a V100 GPU, respectively.