 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRipple: Accelerating LLM Inference on Smartphones with Correlation-Aware Neuron Management
Oct 29, 2024



Large Language Models (LLMs) have achieved remarkable success across various domains, yet deploying them on mobile devices remains an arduous challenge due to their extensive computational and memory demands. While lightweight LLMs have been developed to fit mobile environments, they suffer from degraded model accuracy. In contrast, sparsity-based techniques minimize DRAM usage by selectively transferring only relevant neurons to DRAM while retaining the full model in external storage, such as flash. However, such approaches are critically limited by numerous I/O operations, particularly on smartphones with severe IOPS constraints. In this paper, we propose Ripple, a novel approach that accelerates LLM inference on smartphones by optimizing neuron placement in flash memory. Ripple leverages the concept of Neuron Co-Activation, where neurons frequently activated together are linked to facilitate continuous read access and optimize data transfer efficiency. Our approach incorporates a two-stage solution: an offline stage that reorganizes neuron placement based on co-activation patterns, and an online stage that employs tailored data access and caching strategies to align well with hardware characteristics. Evaluations conducted on a variety of smartphones and LLMs demonstrate that Ripple achieves up to 5.93x improvements in I/O latency compared to the state-of-the-art. As the first solution to optimize storage placement under sparsity, Ripple explores a new optimization space at the intersection of sparsity-driven algorithm and storage-level system co-design in LLM inference.
Sapphire: Automatic Configuration Recommendation for Distributed Storage Systems
Jul 07, 2020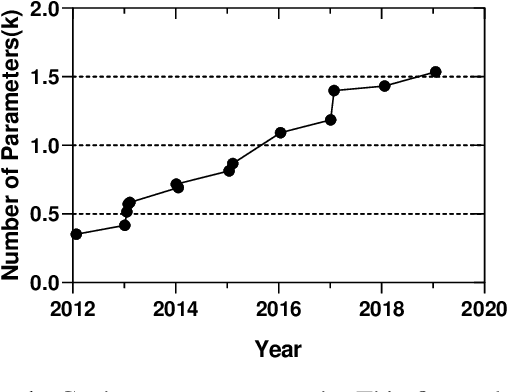


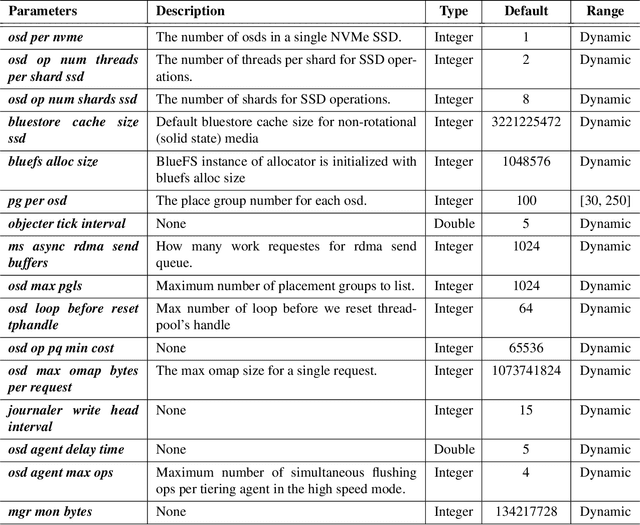
Modern distributed storage systems come with aplethora of configurable parameters that controlmodule behavior and affect system performance. Default settings provided by developers are often suboptimal for specific user cases. Tuning parameters can provide significant performance gains but is a difficult task requiring profound experience and expertise, due to the immense number of configurable parameters, complex inner dependencies and non-linearsystem behaviors. To overcome these difficulties, we propose an automatic simulation-based approach, Sapphire, to recommend optimal configurations by leveraging machine learning and black-box optimization techniques. We evaluate Sapphire on Ceph. Results show that Sapphire significantly boosts Ceph performance to 2.2x compared to the default configuration.