 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePowerFusion: A Tensor Compiler with Explicit Data Movement Description and Instruction-level Graph IR
Jul 11, 2023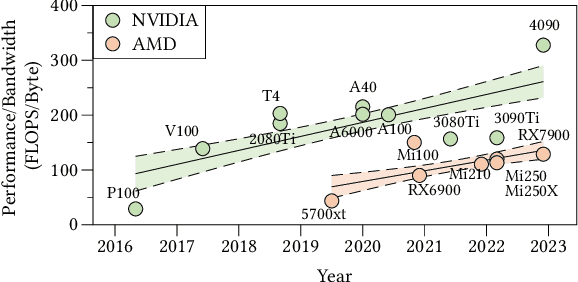
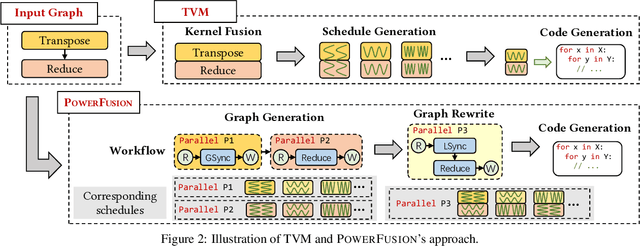
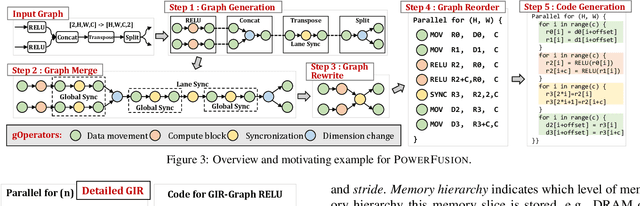
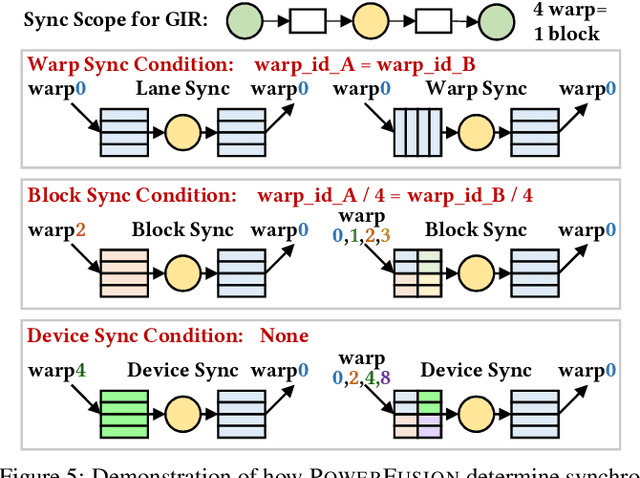
Deep neural networks (DNNs) are of critical use in different domains. To accelerate DNN computation, tensor compilers are proposed to generate efficient code on different domain-specific accelerators. Existing tensor compilers mainly focus on optimizing computation efficiency. However, memory access is becoming a key performance bottleneck because the computational performance of accelerators is increasing much faster than memory performance. The lack of direct description of memory access and data dependence in current tensor compilers' intermediate representation (IR) brings significant challenges to generate memory-efficient code. In this paper, we propose IntelliGen, a tensor compiler that can generate high-performance code for memory-intensive operators by considering both computation and data movement optimizations. IntelliGen represent a DNN program using GIR, which includes primitives indicating its computation, data movement, and parallel strategies. This information will be further composed as an instruction-level dataflow graph to perform holistic optimizations by searching different memory access patterns and computation operations, and generating memory-efficient code on different hardware. We evaluate IntelliGen on NVIDIA GPU, AMD GPU, and Cambricon MLU, showing speedup up to 1.97x, 2.93x, and 16.91x(1.28x, 1.23x, and 2.31x on average), respectively, compared to current most performant frameworks.