 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiSCo: Device-Server Collaborative LLM-Based Text Streaming Services
Feb 17, 2025The rapid rise of large language models (LLMs) in text streaming services has introduced significant cost and Quality of Experience (QoE) challenges in serving millions of daily requests, especially in meeting Time-To-First-Token (TTFT) and Time-Between-Token (TBT) requirements for real-time interactions. Our real-world measurements show that both server-based and on-device deployments struggle to meet diverse QoE demands: server deployments face high costs and last-hop issues (e.g., Internet latency and dynamics), while on-device LLM inference is constrained by resources. We introduce DiSCo, a device-server cooperative scheduler designed to optimize users' QoE by adaptively routing requests and migrating response generation between endpoints while maintaining cost constraints. DiSCo employs cost-aware scheduling, leveraging the predictable speed of on-device LLM inference with the flexible capacity of server-based inference to dispatch requests on the fly, while introducing a token-level migration mechanism to ensure consistent token delivery during migration. Evaluations on real-world workloads -- including commercial services like OpenAI GPT and DeepSeek, and open-source deployments such as LLaMA3 -- show that DiSCo can improve users' QoE by reducing tail TTFT (11-52\%) and mean TTFT (6-78\%) across different model-device configurations, while dramatically reducing serving costs by up to 84\% through its migration mechanism while maintaining comparable QoE levels.
Fine-Grained Embedding Dimension Optimization During Training for Recommender Systems
Jan 09, 2024



Huge embedding tables in modern Deep Learning Recommender Models (DLRM) require prohibitively large memory during training and inference. Aiming to reduce the memory footprint of training, this paper proposes FIne-grained In-Training Embedding Dimension optimization (FIITED). Given the observation that embedding vectors are not equally important, FIITED adjusts the dimension of each individual embedding vector continuously during training, assigning longer dimensions to more important embeddings while adapting to dynamic changes in data. A novel embedding storage system based on virtually-hashed physically-indexed hash tables is designed to efficiently implement the embedding dimension adjustment and effectively enable memory saving. Experiments on two industry models show that FIITED is able to reduce the size of embeddings by more than 65% while maintaining the trained model's quality, saving significantly more memory than a state-of-the-art in-training embedding pruning method. On public click-through rate prediction datasets, FIITED is able to prune up to 93.75%-99.75% embeddings without significant accuracy loss.
PowerFusion: A Tensor Compiler with Explicit Data Movement Description and Instruction-level Graph IR
Jul 11, 2023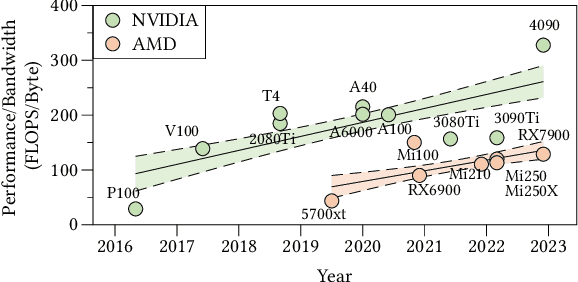
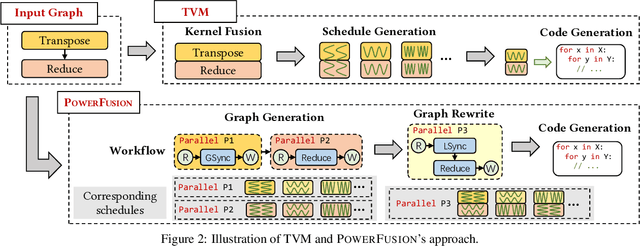
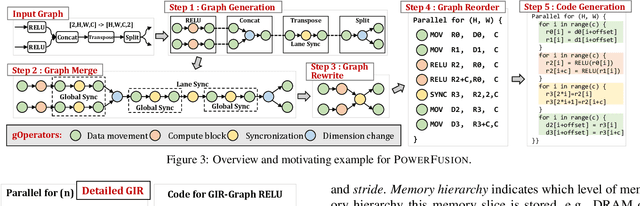
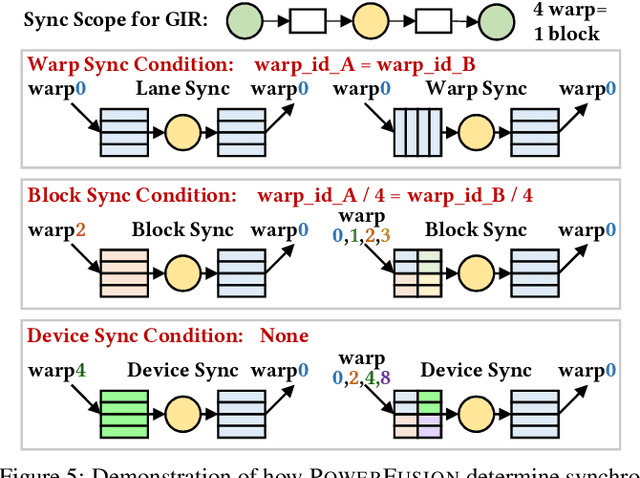
Deep neural networks (DNNs) are of critical use in different domains. To accelerate DNN computation, tensor compilers are proposed to generate efficient code on different domain-specific accelerators. Existing tensor compilers mainly focus on optimizing computation efficiency. However, memory access is becoming a key performance bottleneck because the computational performance of accelerators is increasing much faster than memory performance. The lack of direct description of memory access and data dependence in current tensor compilers' intermediate representation (IR) brings significant challenges to generate memory-efficient code. In this paper, we propose IntelliGen, a tensor compiler that can generate high-performance code for memory-intensive operators by considering both computation and data movement optimizations. IntelliGen represent a DNN program using GIR, which includes primitives indicating its computation, data movement, and parallel strategies. This information will be further composed as an instruction-level dataflow graph to perform holistic optimizations by searching different memory access patterns and computation operations, and generating memory-efficient code on different hardware. We evaluate IntelliGen on NVIDIA GPU, AMD GPU, and Cambricon MLU, showing speedup up to 1.97x, 2.93x, and 16.91x(1.28x, 1.23x, and 2.31x on average), respectively, compared to current most performant frameworks.
Mirror: A Natural Language Interface for Data Querying, Summarization, and Visualization
Mar 15, 2023We present Mirror, an open-source platform for data exploration and analysis powered by large language models. Mirror offers an intuitive natural language interface for querying databases, and automatically generates executable SQL commands to retrieve relevant data and summarize it in natural language. In addition, users can preview and manually edit the generated SQL commands to ensure the accuracy of their queries. Mirror also generates visualizations to facilitate understanding of the data. Designed with flexibility and human input in mind, Mirror is suitable for both experienced data analysts and non-technical professionals looking to gain insights from their data.