 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-Grained Embedding Dimension Optimization During Training for Recommender Systems
Jan 09, 2024



Huge embedding tables in modern Deep Learning Recommender Models (DLRM) require prohibitively large memory during training and inference. Aiming to reduce the memory footprint of training, this paper proposes FIne-grained In-Training Embedding Dimension optimization (FIITED). Given the observation that embedding vectors are not equally important, FIITED adjusts the dimension of each individual embedding vector continuously during training, assigning longer dimensions to more important embeddings while adapting to dynamic changes in data. A novel embedding storage system based on virtually-hashed physically-indexed hash tables is designed to efficiently implement the embedding dimension adjustment and effectively enable memory saving. Experiments on two industry models show that FIITED is able to reduce the size of embeddings by more than 65% while maintaining the trained model's quality, saving significantly more memory than a state-of-the-art in-training embedding pruning method. On public click-through rate prediction datasets, FIITED is able to prune up to 93.75%-99.75% embeddings without significant accuracy loss.
Heterogeneity-Aware Asynchronous Decentralized Training
Sep 17, 2019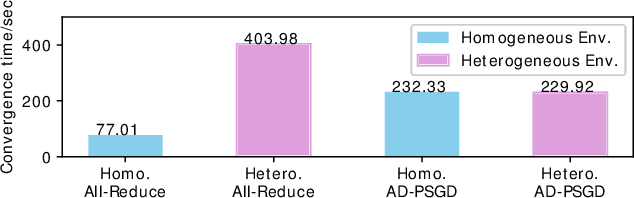
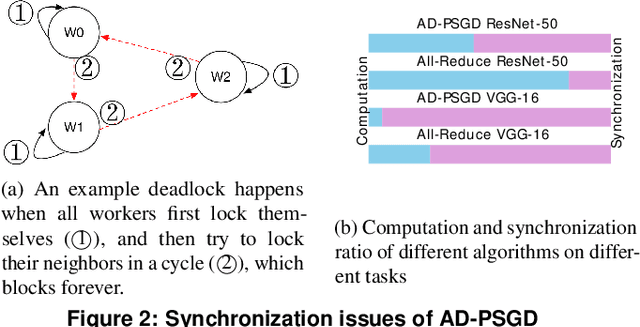
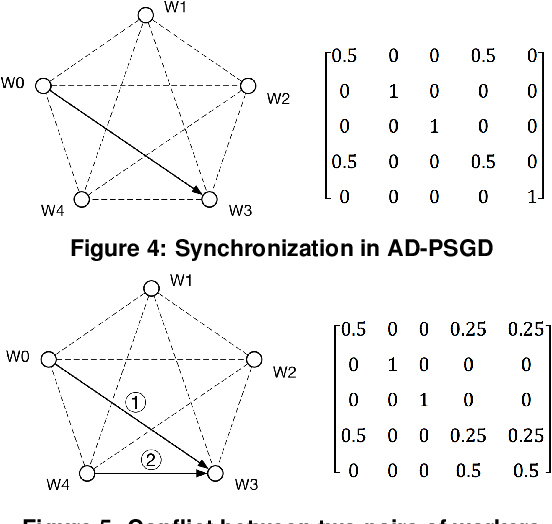
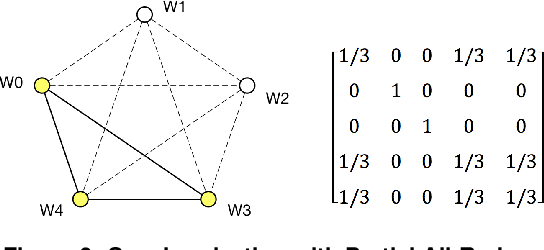
Distributed deep learning training usually adopts All-Reduce as the synchronization mechanism for data parallel algorithms due to its high performance in homogeneous environment. However, its performance is bounded by the slowest worker among all workers, and is significantly slower in heterogeneous situations. AD-PSGD, a newly proposed synchronization method which provides numerically fast convergence and heterogeneity tolerance, suffers from deadlock issues and high synchronization overhead. Is it possible to get the best of both worlds - designing a distributed training method that has both high performance as All-Reduce in homogeneous environment and good heterogeneity tolerance as AD-PSGD? In this paper, we propose Ripples, a high-performance heterogeneity-aware asynchronous decentralized training approach. We achieve the above goal with intensive synchronization optimization, emphasizing the interplay between algorithm and system implementation. To reduce synchronization cost, we propose a novel communication primitive Partial All-Reduce that allows a large group of workers to synchronize quickly. To reduce synchronization conflict, we propose static group scheduling in homogeneous environment and simple techniques (Group Buffer and Group Division) to avoid conflicts with slightly reduced randomness. Our experiments show that in homogeneous environment, Ripples is 1.1 times faster than the state-of-the-art implementation of All-Reduce, 5.1 times faster than Parameter Server and 4.3 times faster than AD-PSGD. In a heterogeneous setting, Ripples shows 2 times speedup over All-Reduce, and still obtains 3 times speedup over the Parameter Server baseline.
Hop: Heterogeneity-Aware Decentralized Training
Feb 07, 2019
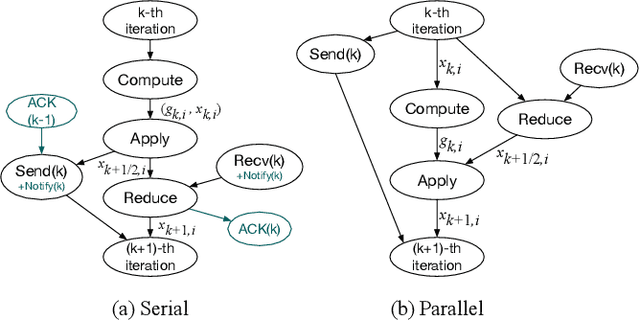
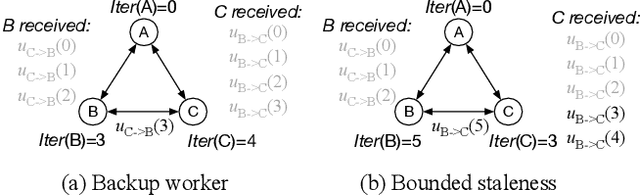

Recent work has shown that decentralized algorithms can deliver superior performance over centralized ones in the context of machine learning. The two approaches, with the main difference residing in their distinct communication patterns, are both susceptible to performance degradation in heterogeneous environments. Although vigorous efforts have been devoted to supporting centralized algorithms against heterogeneity, little has been explored in decentralized algorithms regarding this problem. This paper proposes Hop, the first heterogeneity-aware decentralized training protocol. Based on a unique characteristic of decentralized training that we have identified, the iteration gap, we propose a queue-based synchronization mechanism that can efficiently implement backup workers and bounded staleness in the decentralized setting. To cope with deterministic slowdown, we propose skipping iterations so that the effect of slower workers is further mitigated. We build a prototype implementation of Hop on TensorFlow. The experiment results on CNN and SVM show significant speedup over standard decentralized training in heterogeneous settings.