 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoosting Document Parsing Efficiency and Performance with Coarse-to-Fine Visual Processing
Mar 25, 2026Document parsing is a fine-grained task where image resolution significantly impacts performance. While advanced research leveraging vision-language models benefits from high-resolution input to boost model performance, this often leads to a quadratic increase in the number of vision tokens and significantly raises computational costs. We attribute this inefficiency to substantial visual regions redundancy in document images, like background. To tackle this, we propose PaddleOCR-VL, a novel coarse-to-fine architecture that focuses on semantically relevant regions while suppressing redundant ones, thereby improving both efficiency and performance. Specifically, we introduce a lightweight Valid Region Focus Module (VRFM) which leverages localization and contextual relationship prediction capabilities to identify valid vision tokens. Subsequently, we design and train a compact yet powerful 0.9B vision-language model (PaddleOCR-VL-0.9B) to perform detailed recognition, guided by VRFM outputs to avoid direct processing of the entire large image. Extensive experiments demonstrate that PaddleOCR-VL achieves state-of-the-art performance in both page-level parsing and element-level recognition. It significantly outperforms existing solutions, exhibits strong competitiveness against top-tier VLMs, and delivers fast inference while utilizing substantially fewer vision tokens and parameters, highlighting the effectiveness of targeted coarse-to-fine parsing for accurate and efficient document understanding. The source code and models are publicly available at https://github.com/PaddlePaddle/PaddleOCR.
PP-OCRv5: A Specialized 5M-Parameter Model Rivaling Billion-Parameter Vision-Language Models on OCR Tasks
Mar 25, 2026The advent of "OCR 2.0" and large-scale vision-language models (VLMs) has set new benchmarks in text recognition. However, these unified architectures often come with significant computational demands, challenges in precise text localization within complex layouts, and a propensity for textual hallucinations. Revisiting the prevailing notion that model scale is the sole path to high accuracy, this paper introduces PP-OCRv5, a meticulously optimized, lightweight OCR system with merely 5 million parameters. We demonstrate that PP-OCRv5 achieves performance competitive with many billion-parameter VLMs on standard OCR benchmarks, while offering superior localization precision and reduced hallucinations. The cornerstone of our success lies not in architectural expansion but in a data-centric investigation. We systematically dissect the role of training data by quantifying three critical dimensions: data difficulty, data accuracy, and data diversity. Our extensive experiments reveal that with a sufficient volume of high-quality, accurately labeled, and diverse data, the performance ceiling for traditional, efficient two-stage OCR pipelines is far higher than commonly assumed. This work provides compelling evidence for the viability of lightweight, specialized models in the large-model era and offers practical insights into data curation for OCR. The source code and models are publicly available at https://github.com/PaddlePaddle/PaddleOCR.
ERNIE 5.0 Technical Report
Feb 04, 2026In this report, we introduce ERNIE 5.0, a natively autoregressive foundation model desinged for unified multimodal understanding and generation across text, image, video, and audio. All modalities are trained from scratch under a unified next-group-of-tokens prediction objective, based on an ultra-sparse mixture-of-experts (MoE) architecture with modality-agnostic expert routing. To address practical challenges in large-scale deployment under diverse resource constraints, ERNIE 5.0 adopts a novel elastic training paradigm. Within a single pre-training run, the model learns a family of sub-models with varying depths, expert capacities, and routing sparsity, enabling flexible trade-offs among performance, model size, and inference latency in memory- or time-constrained scenarios. Moreover, we systematically address the challenges of scaling reinforcement learning to unified foundation models, thereby guaranteeing efficient and stable post-training under ultra-sparse MoE architectures and diverse multimodal settings. Extensive experiments demonstrate that ERNIE 5.0 achieves strong and balanced performance across multiple modalities. To the best of our knowledge, among publicly disclosed models, ERNIE 5.0 represents the first production-scale realization of a trillion-parameter unified autoregressive model that supports both multimodal understanding and generation. To facilitate further research, we present detailed visualizations of modality-agnostic expert routing in the unified model, alongside comprehensive empirical analysis of elastic training, aiming to offer profound insights to the community.
PaddleOCR-VL-1.5: Towards a Multi-Task 0.9B VLM for Robust In-the-Wild Document Parsing
Jan 29, 2026We introduce PaddleOCR-VL-1.5, an upgraded model achieving a new state-of-the-art (SOTA) accuracy of 94.5% on OmniDocBench v1.5. To rigorously evaluate robustness against real-world physical distortions, including scanning, skew, warping, screen-photography, and illumination, we propose the Real5-OmniDocBench benchmark. Experimental results demonstrate that this enhanced model attains SOTA performance on the newly curated benchmark. Furthermore, we extend the model's capabilities by incorporating seal recognition and text spotting tasks, while remaining a 0.9B ultra-compact VLM with high efficiency. Code: https://github.com/PaddlePaddle/PaddleOCR
PaddleOCR-VL: Boosting Multilingual Document Parsing via a 0.9B Ultra-Compact Vision-Language Model
Oct 16, 2025In this report, we propose PaddleOCR-VL, a SOTA and resource-efficient model tailored for document parsing. Its core component is PaddleOCR-VL-0.9B, a compact yet powerful vision-language model (VLM) that integrates a NaViT-style dynamic resolution visual encoder with the ERNIE-4.5-0.3B language model to enable accurate element recognition. This innovative model efficiently supports 109 languages and excels in recognizing complex elements (e.g., text, tables, formulas, and charts), while maintaining minimal resource consumption. Through comprehensive evaluations on widely used public benchmarks and in-house benchmarks, PaddleOCR-VL achieves SOTA performance in both page-level document parsing and element-level recognition. It significantly outperforms existing solutions, exhibits strong competitiveness against top-tier VLMs, and delivers fast inference speeds. These strengths make it highly suitable for practical deployment in real-world scenarios.
PP-DocLayout: A Unified Document Layout Detection Model to Accelerate Large-Scale Data Construction
Mar 21, 2025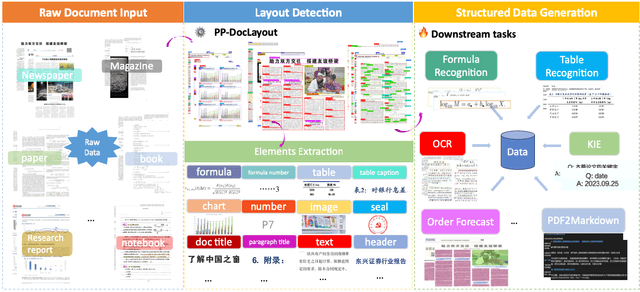

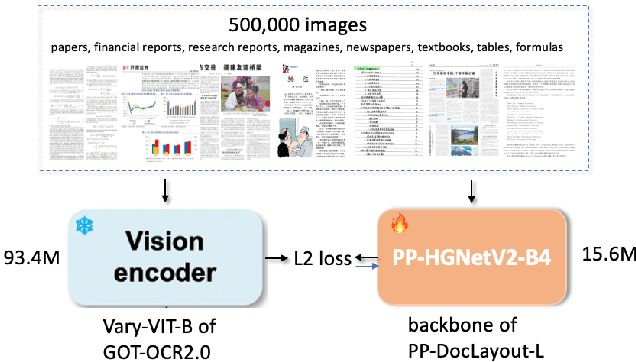

Document layout analysis is a critical preprocessing step in document intelligence, enabling the detection and localization of structural elements such as titles, text blocks, tables, and formulas. Despite its importance, existing layout detection models face significant challenges in generalizing across diverse document types, handling complex layouts, and achieving real-time performance for large-scale data processing. To address these limitations, we present PP-DocLayout, which achieves high precision and efficiency in recognizing 23 types of layout regions across diverse document formats. To meet different needs, we offer three models of varying scales. PP-DocLayout-L is a high-precision model based on the RT-DETR-L detector, achieving 90.4% mAP@0.5 and an end-to-end inference time of 13.4 ms per page on a T4 GPU. PP-DocLayout-M is a balanced model, offering 75.2% mAP@0.5 with an inference time of 12.7 ms per page on a T4 GPU. PP-DocLayout-S is a high-efficiency model designed for resource-constrained environments and real-time applications, with an inference time of 8.1 ms per page on a T4 GPU and 14.5 ms on a CPU. This work not only advances the state of the art in document layout analysis but also provides a robust solution for constructing high-quality training data, enabling advancements in document intelligence and multimodal AI systems. Code and models are available at https://github.com/PaddlePaddle/PaddleX .
DiSCo: Device-Server Collaborative LLM-Based Text Streaming Services
Feb 17, 2025The rapid rise of large language models (LLMs) in text streaming services has introduced significant cost and Quality of Experience (QoE) challenges in serving millions of daily requests, especially in meeting Time-To-First-Token (TTFT) and Time-Between-Token (TBT) requirements for real-time interactions. Our real-world measurements show that both server-based and on-device deployments struggle to meet diverse QoE demands: server deployments face high costs and last-hop issues (e.g., Internet latency and dynamics), while on-device LLM inference is constrained by resources. We introduce DiSCo, a device-server cooperative scheduler designed to optimize users' QoE by adaptively routing requests and migrating response generation between endpoints while maintaining cost constraints. DiSCo employs cost-aware scheduling, leveraging the predictable speed of on-device LLM inference with the flexible capacity of server-based inference to dispatch requests on the fly, while introducing a token-level migration mechanism to ensure consistent token delivery during migration. Evaluations on real-world workloads -- including commercial services like OpenAI GPT and DeepSeek, and open-source deployments such as LLaMA3 -- show that DiSCo can improve users' QoE by reducing tail TTFT (11-52\%) and mean TTFT (6-78\%) across different model-device configurations, while dramatically reducing serving costs by up to 84\% through its migration mechanism while maintaining comparable QoE levels.
SHIELD: Evaluation and Defense Strategies for Copyright Compliance in LLM Text Generation
Jun 18, 2024



Large Language Models (LLMs) have transformed machine learning but raised significant legal concerns due to their potential to produce text that infringes on copyrights, resulting in several high-profile lawsuits. The legal landscape is struggling to keep pace with these rapid advancements, with ongoing debates about whether generated text might plagiarize copyrighted materials. Current LLMs may infringe on copyrights or overly restrict non-copyrighted texts, leading to these challenges: (i) the need for a comprehensive evaluation benchmark to assess copyright compliance from multiple aspects; (ii) evaluating robustness against safeguard bypassing attacks; and (iii) developing effective defenses targeted against the generation of copyrighted text. To tackle these challenges, we introduce a curated dataset to evaluate methods, test attack strategies, and propose lightweight, real-time defenses to prevent the generation of copyrighted text, ensuring the safe and lawful use of LLMs. Our experiments demonstrate that current LLMs frequently output copyrighted text, and that jailbreaking attacks can significantly increase the volume of copyrighted output. Our proposed defense mechanisms significantly reduce the volume of copyrighted text generated by LLMs by effectively refusing malicious requests. Code is publicly available at https://github.com/xz-liu/SHIELD
PP-MobileSeg: Explore the Fast and Accurate Semantic Segmentation Model on Mobile Devices
Apr 11, 2023The success of transformers in computer vision has led to several attempts to adapt them for mobile devices, but their performance remains unsatisfactory in some real-world applications. To address this issue, we propose PP-MobileSeg, a semantic segmentation model that achieves state-of-the-art performance on mobile devices. PP-MobileSeg comprises three novel parts: the StrideFormer backbone, the Aggregated Attention Module (AAM), and the Valid Interpolate Module (VIM). The four-stage StrideFormer backbone is built with MV3 blocks and strided SEA attention, and it is able to extract rich semantic and detailed features with minimal parameter overhead. The AAM first filters the detailed features through semantic feature ensemble voting and then combines them with semantic features to enhance the semantic information. Furthermore, we proposed VIM to upsample the downsampled feature to the resolution of the input image. It significantly reduces model latency by only interpolating classes present in the final prediction, which is the most significant contributor to overall model latency. Extensive experiments show that PP-MobileSeg achieves a superior tradeoff between accuracy, model size, and latency compared to other methods. On the ADE20K dataset, PP-MobileSeg achieves 1.57% higher accuracy in mIoU than SeaFormer-Base with 32.9% fewer parameters and 42.3% faster acceleration on Qualcomm Snapdragon 855. Source codes are available at https://github.com/PaddlePaddle/PaddleSeg/tree/release/2.8.
LVIS Challenge Track Technical Report 1st Place Solution: Distribution Balanced and Boundary Refinement for Large Vocabulary Instance Segmentation
Nov 05, 2021
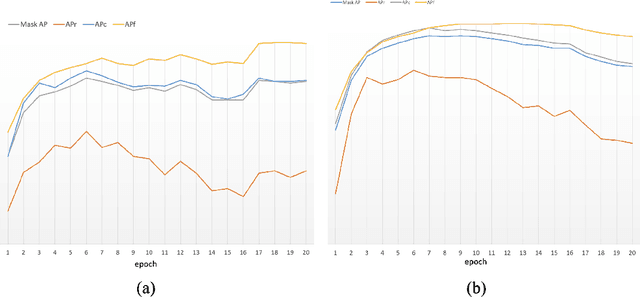
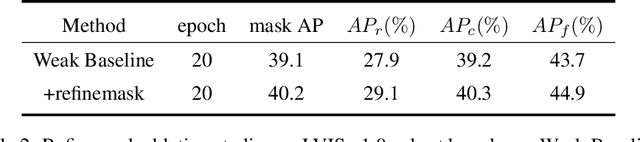

This report introduces the technical details of the team FuXi-Fresher for LVIS Challenge 2021. Our method focuses on the problem in following two aspects: the long-tail distribution and the segmentation quality of mask and boundary. Based on the advanced HTC instance segmentation algorithm, we connect transformer backbone(Swin-L) through composite connections inspired by CBNetv2 to enhance the baseline results. To alleviate the problem of long-tail distribution, we design a Distribution Balanced method which includes dataset balanced and loss function balaced modules. Further, we use a Mask and Boundary Refinement method composed with mask scoring and refine-mask algorithms to improve the segmentation quality. In addition, we are pleasantly surprised to find that early stopping combined with EMA method can achieve a great improvement. Finally, by using multi-scale testing and increasing the upper limit of the number of objects detected per image, we achieved more than 45.4% boundary AP on the val set of LVIS Challenge 2021. On the test data of LVIS Challenge 2021, we rank 1st and achieve 48.1% AP. Notably, our APr 47.5% is very closed to the APf 48.0%.